一种基于深度学习的跨站点冷启动推荐方法与流程
本发明涉及一种冷启动推荐方法,特别是一种基于深度学习的跨站点冷启动推荐方法。
背景技术:
社交类网站为人们的生活提供了便利。现在的社交网站已经不仅仅具有邮件传递、朋友联络的功能。它们更贴近人们的现实生活,人们可以在社交网站上完成餐厅预订、找工作、购买产品等活动。facebook和twitter平台在2014年添加的一个新功能就很清楚地说明了这个问题,它们允许用户直接通过点击一个“buy”按钮来购买在广告上看到的产品。而且许多电子商务网站允许用户使用社交网络(如facebook、twitter以及google)的登录信息完成登录。把电子商务网站和社交网站的用户信息绑定在一起可以帮助获取更加丰富的用户信息,利用这些信息可以更加详细地了解用户的兴趣点,从而能更好地完成推荐。
个性化推荐是在线网站服务的一个重要组成部分,它能在扩大网站优势的同时,为用户节约大量的时间。个性化推荐的一个主要方法就是协同过滤算法,这类算法使用用户在网站上的历史交互记录来完成推荐过程,如它利用用户的最近邻居用户对商品的加权评分来预测用户对目标的评分。另一个方法就是基于内容的推荐算法,这种算法可以根据产品或者用户的特征为用户推荐一些新的产品。这两种方法都有很好的表现,并被广泛应用。值得说明的是,用户需要一定数量的历史交互记录才能利用协同过滤算法得到较好的推荐结果。但如果遇到用户冷启动这类任务,即给新用户推荐产品,协同过滤算法就很难发挥它们的优势。而基于内容的推荐算法可以从任意的用户和产品抽取特征,并使用这些特征完成对用户的推荐过程。发现基于内容的推荐算法可以完成一些冷启动任务,如给用户推荐一些新产品。但是该算法在为新用户推荐时效果并不是很好。这是因为使用基于内容的算法获取的用户特征比较有限,系统很难了解用户的兴趣所在。
技术实现要素:
本发明提出了一种跨站点的冷启动推荐方法,利用电子商务网站的新用户在社交网站上的信息来完成对新用户的产品推荐,不需要用户的历史记录,仅使用了用户的社交信息就能详细了解用户的兴趣点,并转换成用于冷启动推荐的数据表示,提高了推荐的效率。
附图说明
图1为本发明跨站点的冷启动推荐方法的主要步骤。
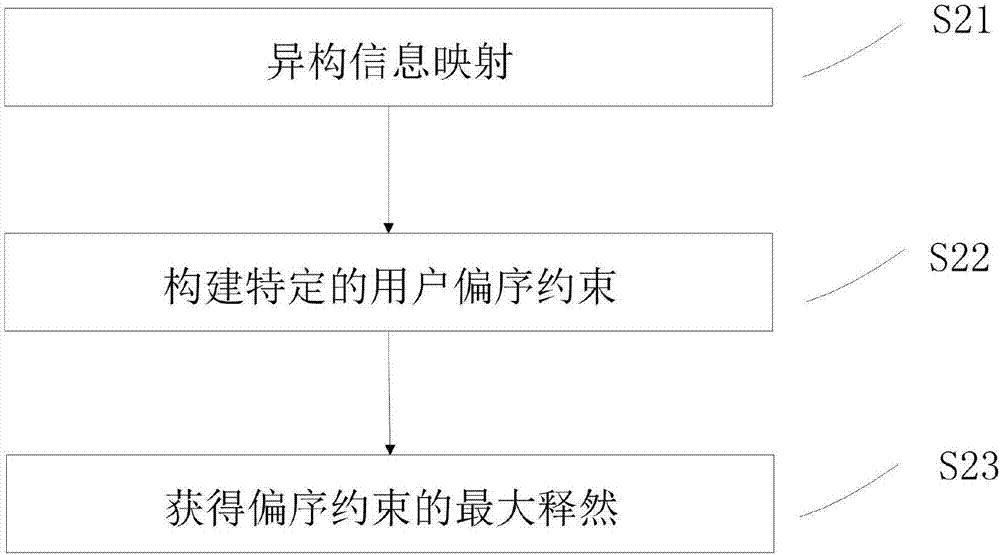
图2为本发明深度异构映射模型构建阶段的主要步骤。
图3为本发明偏序约束的构建关系。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明提出的跨站点的冷启动推荐方法涉及到智能分析、深度学习等技术,利用电子商务网站的新用户在社交网站上的信息来完成对新用户的产品推荐,不需要用户的历史记录,只使用了用户的社交信息转换成能用于冷启动推荐的数据表示。
在电子商务网站中,用户的购买记录由用户集和产品集组成。u表示用户集,p表示产品集,而
本发明考虑的跨站点情景就是:一个微博用户
本发明中,微博和电子商务网站的关联用户用来训练模型。所述关联用户可作为连接微博信息和电子商务网站用户信息的一个桥梁。通过合理的信息映射,用户的微博信息用于对电子商务网站上的个性化推荐任务。利用关联用户,在他们的微博信息和购买的产品集之间建立一个映射关系。鉴于产品集本身的内容信息比较有限,而且很多时候用户购买产品是随机状态,找出微博用户和电子商务网站用户购买行为习惯的关系。也就是说,给定一个微博用户,找到与其最“相似”的电子商务网站上的用户,构建用户之间的相似程度模型。
如图1所示,本发明的跨站点的冷启动推荐方法主要包括三个阶段:特征提取阶段,深度异构映射模型构建阶段,将深度异构模型映射用于跨站点的冷启动推荐阶段。
首先需要完成对微博用户和电子商务网站的用户的特征提取过程,特征提取包括微博特征提取和电子商务用户特征提取。
微博特征提取包括用户的人口特征,文本属性,社会属性以及时间属性。
所述人口特征可以直接从用户在微博网站上的公开信息中获取,包括用户的性别,年龄,婚姻状况,教育水平,职业,兴趣爱好等。
所述文本属性由所有的用户的微博内容整合成一个文件。基于潜在狄利克雷分布,输入为多个文档,输出是每个文档的隐含话题表示,采用了词袋方法,使用三层贝叶斯概率模型获得话题分布和词的隐含表示。
所述社会属性由话题模型去学习用户潜在的群组特征。所述话题模型将每个用户作为一个词,将关注该用户的用户整合成文件。然后可以抓取有相近喜好的潜在用户群组,在潜在用户群组的基础上给出每个用户一个兴趣表示。
所述时间属性包括每日活动分布和每周活动分布。用户的每日活动分布共有24维,第i维表示用户在一天中的第i个小时内发微博的平均条数。同理用户的每周活动分布共有7维,第i维表示用户在一周中的第i天内发微博的平均条数。
本发明在电子商务用户特征提取阶段,将根据用户的购买记录为电子商务网站上的每个用户生成有效的表示vu。使用分布式表示学习的方法,因为使用该类方法用户表示vu是稠密的,且通常几百维数据就比较有效。
基于分布式学习方法的模型的输入为关系图,包括相关结点和结点之间的权重,其输出的是各个结点的固定维度的隐含表示。先从图上每个结点出发,随机游走产生多条路径,将这些路径作为模型的输入。这样利用路径中结点的上下文关系,可以生成结点的隐含表示了。
在获取用户的“电商表示”之前,需要将用户历史数据处理成图结构,在最终的图结构中用户是结点,边用来连接购买产品集相似的用户。
本发明将每一个用户作为一个结点,图中每一条边带有权重sim(u1,u2),连接结点u1和u2,若其中令nu表示与用户u购物行为最相似的k个用户,则
其中p(u)表示用户u购买的产品集,k设置为20。
在获得了au“微博特征表示”和vu“电商特征表示”之后,利用关联用户训练一个跨站点的深度偏好排序模型。由于au和vu是实值向量,很难找到一个有效的回归函数,本发明使用两个神经网络模型,所述模型分别把au和vu映射到同一隐含空间中,基于深度神经网络模型变相完成了au到vu的转换。
在深度神经网络模型构建中,采用了一个非线性函数作为激活函数:
深度神经网络模型构造如下:令x为输入向量,y是输出向量,li表示第i个中间隐含层的向量,wi表示第i层权重,bi表示第i层的偏差向量,则有l1=w1x,li=f(wili-1+bi),,y=f(wnln-1+bn),其中i=2,…,n-1。
本发明使用两个不同的深度神经网络模型将au“微博特征表示”和vu“电商特征表示”映射成两个不同的向量表示,并利用特定的用户偏序约束在统一的向量空间中连接上述两个向量表示。
如图2所示,深度异构映射模型构建阶段包括异构信息映射,构建特定的用户偏序约束,获得偏序约束的最大释然。
如图3所示,其中e和e′表示两个电子商务网站上的用户,u表示关联用户或者微博用户。特定的用户偏序约束定义为:给定一个关联用户u,
异构信息映射:先将au“微博特征表示”和vu“电商特征表示”映射到统一隐含空间中,然后描述它们的用户偏序约束。假设ve和ve′分别是e和e′的电商特征表示,给定微博用户u和他的微博特征表示au,需要找到两个映射函数g(·)和h(·)分别将au“微博特征表示”和vu“电商特征表示”映射为不同的d维隐含表示。而映射函数g(·)和h(·)就是两个dnn模型。则g(au)→yu(m),h(ve)→ye(e),其中
特定的用户偏序约束的公式表示:利用映射函数g(·)和h(·)将au和ve映射到统一隐含空间中,即yu(m)和ye(e)维度相同。接下来使用余弦相似度来描述特定的用户偏序约束,给定一个偏序约束
特定的用户偏序约束的构建:为了训练模型,按照下列方法构建偏序约束集:从n(u)中选取e,从u\(n(u)∪{u})中选取e′,对于其他用户,指定用户的购买行为和它的k近邻更相似。对于每个用户e,从u\(n(u)∪{u})中随机选取10个用户。选取的e和e′都来自n(u),而连接e和u的边的权重比连接e′和u的边更大。其中e就是用户u,而e′来自n(u)。对比其他用户,指定用户本身的购买行为习惯和自身最为相近。在偏序约束
采用pairwiseranking的模型来获得偏序约束的最大似然。我们用sigmoid函数作为损失函数:
其中y是一个收缩因子。根据上述的损失函数,整体的正则化损失函数为:
其中
本方法先找到可能与该用户购买行为相似的top-k个用户,可简称为k近邻。通常情况下,给定一个用户u和其微博特征au,利用已经训练好的模型,可以根据下列公式对电子商务网站上的用户进行排序:
其中re,p代表用户e购买产品p的次数。而对于那些从来没有被用户e购买的产品,按照这些产品的历史被购买次数排序,然后放在候选列表的靠后部分。
本发明提出的方法的时间主要花费在寻找k近邻的过程中。为了提高这个部分的效率,首先我们离线完成所有电子商务网站用户的特征向量的计算,然后利用函数h(·)将该特征向量映射为ye(e)。当一个微博用户出现时,首先获取该用户的微博特征向量au,利用函数g(·)将其映射为yu(m)。在线推荐重,对于yu(m),使其和每一个ye(e)进行点积运算。
由于电子商务网站的用户数量太过庞大,使得运算的消耗太大,可以使用近似加速的算法帮助加速找k近邻的过程,即先根据学习到的用户表示使用聚类算法聚成c类,便可以得到c个超用户。根据用户u找到与其相似的top-k′个超用户,然后仅在这些超用户所在用户堆中的用户进行相似度的计算,最终找到用户u的k近邻。其中k′=3时有较好的测试结果,同时聚类堆数可以根据
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!