基于熵权算法的多变量面板数据聚类分析方法与流程
本发明属于数据挖掘
技术领域:
,主要应用于对目标群体的分类处理,为目标群体进行差异化分析奠定基础,具体涉及一种基于熵权算法的多变量面板数据聚类分析方法。
背景技术:
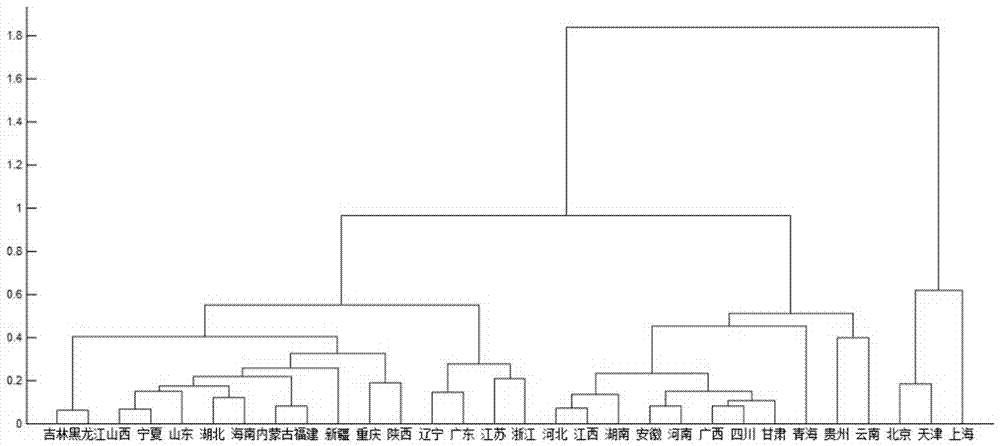
:(1)聚类分析的基本原理聚类分析是以差异分析为基础的统计分析方法。通过计算各个样本之间的“亲疏程度”实现对“没有先验知识”的样本进行分类,从而达到“物以类聚”的效果。这里所谓的“亲疏程度”指的是各样本在各变量取值上的差异状况。“没有先验知识”是指在进行聚类分析前不对样本进行事前的分类假定,仅是将样本集视为一个整体或是将每个样本视为单独一类。(2)现有基于面板数据的多变量聚类分析相关研究目前基于面板数据的多变量聚类分析研究工作并不多。这些研究多采用“退化时间维度”的思路,通过将时间维度的变量均值进行降维,或者将各时点下各变量的“统计距离”简单相加。这样的处理方法忽略了变量值在时间序列上的变化情况,减少了聚类分析的可用信息,分析结果存在着不足和缺陷。另一方面,部分研究者注意到了时间序列上变量值的变化情况对聚类分析的贡献。但是,目前在处理多变量数据集时,尚缺乏科学的方法和技术对时间序列变化情况的贡献度(权重)进行测算,因此并不能准确地测算出时间变化对聚类分析的影响程度。在现有可知的研究成果中,李因果[1]将“绝对量距离”、“增量距离”和“变异系数距离”通过α、β和γ三个权重进行加权求和,得到整体的“综合全时距离”。他在研究中假设α、β和γ对任何变量都保持相等的取值,并且简单地将权重设置为α=β=γ=1/3。这一假设缺乏可靠的理论依据,也不符合现实情况,因此而得到的分类结果不够准确。高雪[2]采用和李因果类似的思路,计算了“绝对距离”和“增速距离”,并对两者进行加权求和,得到个体距离。她通过对每个时点下样本个体落入k类别的次数进行比较,以完成对多变量面板数据的聚类分析。这一方法割裂了整个时间区间,得到的分析结果并不能有效地反映整个时间序列的变化情况。另外,算法对权重值的设定也基于和李因果相同的假设,这并不能反映出变量间真实的权重关系。李峥和刘云霞[3]也做了类似的研究,但其构建的“欧氏时空距离”本质上是仅针对“绝对距离”进行的聚类分析,并不能反映出时间序列上的变化特征。(3)权重设定的相关研究权重设定有很多方法,其中熵权法是对权重进行客观测定的一种重要方法,已经在工程技术、经济社会研究中得到了广泛的应用。在信息论中,熵反映的是信息的无序程度。信息集中数值的变异程度越大,其包含的信息量越大,则表明该信息集越重要,赋予它的权重也应该越大。但是现有的研究中,熵权法都是应用在单一时点的横截面数据或技术退化为单一时点的面板数据分析中,无法体现信息在时间序列上的变化。目前在对多变量数集进行聚类分析时,大部分研究工作仅仅针对横截面数据进行分析,忽略了数据的时间序列变化特征。少数研究工作注意到时间序列上变量值的变化会对聚类分析产生重要的影响。但是,在多变量数集聚类分析中,他们对时间序列变化因素的贡献度(权重)测算缺乏科学可行的技术和方法,只是简单人为赋予主观的权重值,这样得到的聚类分析结果必然缺乏科学依据。熵权法是进行权重测算的一个重要技术。这一方法已经在工程技术和经济社会研究中得到了广泛应用。但是目前熵权法还没有很好的技术用于反映信息在时间序列上的变异情况,因此这一技术在聚类分析中没有得到很好的应用。本发明提出基于面板数据的多变量聚类分析新思路,解决了熵权法在处理时间序列数据时的技术问题,并将熵权法和多变量聚类分析结合起来,用熵权法的结果作为多变量聚类分析中权重设定的依据,解决了聚类分析在多变量面板数据分类问题中的关键性环节,对聚类分析的应用有着实质性的突破。参考文献:[1]李因果.面板数据聚类方法及应用[j].统计研究,2010,27(9):73-79[2]李峥、刘云霞.面板数据多指标聚类和变系数模型的方法与实证[j].统计与决策,2014(7):11-14[3]高雪、谢仪、侯红卫.基于多指标面板数据的改进的聚类方法及应用[j].浙江工业大学学报,2014,42(8):468-472。技术实现要素:本发明的目的在于提供一种基于熵权算法的多变量面板数据聚类分析方法,该方法基本克服了现有方法在处理时间序列上的缺陷,有效地丰富了可用信息,还对权重测算方法进行了很好的改善,最终提升了聚类分析结果的有效性和科学性。为实现上述目的,本发明的技术方案是:一种基于熵权算法的多变量面板数据聚类分析方法,包括如下步骤,s1:读入多变量面板数据;s2:计算各个变量所对应的绝对距离和相对距离;s3:计算各个变量的个体距离矩阵;s4:计算全变量个体距离矩阵;s5:以全变量个体距离矩阵为依据,完成样本的类型划分。在本发明一实施例中,所述步骤s2具体实现方式如下:假设通过读入的多变量面板数据采集到的数据共存在n个观测对象(n=1,2,…,n-1,n),时间序列为t期(t=1,2,…,t-1,t),并含有k个变量(k=1,2,…,k-1,k);那么,观测对象n在时点t上对于变量k的取值表示为xntk;s21:对于变量k在时间序列上的绝对取值,个体ni和个体nj之间的距离,即绝对距离,用表示,其中s22:对于变量k在时间序列上的相对变化率δxntk/xn,t-1,k,个体ni和个体nj之间的距离,即相对距离,用表示,其中在本发明一实施例中,所述步骤s3具体实现方式如下:s31:用反映离散程度的统计量对多变量面板数据的时间序列进行降维,构建新的数据矩阵r,该过程中采用标准差系数cvnk=σnk/μnk对多变量面板数据的时间序列进行降维,其中σnk、μnk分别表示在时间序列上个体n关于变量k取值的标准差和均值;s32:计算第k个变量下第n个个体在时间序列上标准差系数cvnk的比重pnk:s33:通过pnk计算第k个变量的熵值ek:s34:计算第k个变量的熵权αk:s35:计算各变量的个体距离矩阵dk:在本发明一实施例中,所述步骤s4具体实现方式如下:将各变量的个体距离矩阵dk进行加总,得到全变量个体距离矩阵d;d表示为:其中并且在本发明一实施例中,所述步骤s5完成样本的类型划分是通过包括最近邻居距离、最远邻居距离、离差平方和法的计算方法实现。相较于现有技术,本发明具有以下有益效果:本发明在分析现有的多指标面板数据聚类分析的基础上,提出了一种新的基于熵权法的聚类分析方法;该方法基本克服了现有方法在处理时间序列上的缺陷,有效地丰富了可用信息,还对权重测算方法进行了很好的改善,最终提升了聚类分析结果的有效性和科学性。附图说明图1为本发明方法流程图。图2为全国省市自治区城镇化水平的聚类分析结果。图3为综合多变化的城镇化水平分类。图4为针对人口城镇化水平的城镇化水平分类。具体实施方式下面结合附图,对本发明的技术方案进行具体说明。如图1所示,本发明的一种基于熵权算法的多变量面板数据聚类分析方法,首先,读入多变量面板数据;然后,计算各个变量所对应的绝对距离和相对距离;而后,计算各个变量的个体距离矩阵;再而,计算全变量个体距离矩阵;最后,以全变量个体距离矩阵为依据,即可完成样本的类型划分;具体如下:假设通过读入的多变量面板数据采集到的数据共存在n个观测对象(n=1,2,…,n-1,n),时间序列为t期(t=1,2,…,t-1,t),并含有k个变量(k=1,2,…,k-1,k);那么,观测对象n在时点t上对于变量k的取值表示为xntk;1)计算各个变量所对应的绝对距离和相对距离:(1)对于变量k在时间序列上的绝对取值,个体ni和个体nj之间的距离,即绝对距离,用表示,其中(2)对于变量k在时间序列上的相对变化率δxntk/xn,t-1,k,个体ni和个体nj之间的距离,即相对距离,用表示,其中2)计算各个变量的个体距离矩阵:个体距离dk是包含着绝对距离和相对距离的“综合距离”矩阵。矩阵中的每个元素是各个变量绝对距离和相对距离的加权之和,表示为其中,αk1和αk2分别为变量k绝对距离和相对距离的权重。用扩展的熵权法对权重αk1和αk2进行测算熵反映的是信息的无序程度。如果在一个封闭的信息集中,其包含的数值变异程度越大,说明其包含的信息量越大。那么,该信息集越重要,赋予它的权重也应该越大。为了使熵权法在面板数据分析中能够包含时间序列的变化特点,本发明对熵权法进行了进一步的扩展。(1)用反映离散程度的统计量对多变量面板数据的时间序列进行降维,构建新的数据矩阵r,该过程中采用标准差系数cvnk=σnk/μnk对多变量面板数据的时间序列进行降维,其中σnk、μnk分别表示在时间序列上个体n关于变量k取值的标准差和均值;(2)计算第k个变量下第n个个体在时间序列上标准差系数cvnk的比重pnk:(3)通过pnk计算第k个变量的熵值ek:(4)计算第k个变量的熵权αk:(5)计算各变量的个体距离矩阵dk:3)计算全变量个体距离矩阵:将各变量的个体距离矩阵dk进行加总,得到全变量个体距离矩阵d;d表示为:其中并且4)以全变量个体距离矩阵d为依据,即可完成样本的类型划分:具体过程中可采用聚类分析常用的最近邻居距离、最远邻居距离、离差平方和法等计算方法。以下为本发明的具体实施例。根据上述方法,本文对中国城镇化水平的真实数据进行实证分析。为了计算思路的清晰,将城镇化水平分解为人口城镇化水平、土地城镇化水平、人口城镇化增速和土地城镇化增速四个变量。其中,前两个变量表示“绝对量”,而后两个代表着“相对量”。表1列举了分析所用的各项变量及其数据来源,各变量样本时间范围为2008-2013年。表1:各个变量指标及数据来源指标单位数据来源非农业人口人中国人口和就业统计年鉴农业人口人中国人口和就业统计年鉴城镇人口人中国统计年鉴乡村人口人中国统计年鉴城市建成区面积平方公里中国统计年鉴建制镇建成区面积平方公里中国城乡建设统计年鉴土地调查面积万公顷中国统计年鉴以户籍为统计口径的城镇化水平=非农业人口/(非农业人口+农业人口)以常住人口为统计口径的城镇化水平=城镇人口/(城镇人口+乡村人口)人口城镇化水平=0.2666×以户籍为统计口径的城镇化水平+0.7334×以常住人口为统计口径的城镇化水平土地城镇化水平=(城市建成区面积+建制镇建成区面积)/土地调查面积实证分析的具体步骤如下:(1)各个指标熵权的测算。表2是根据前文所述方法得到熵权结果:表2:各个城镇化指标的熵权(2)采用欧氏距离的算法,分别计算各个指标的个体距离dk。(3)求得个体全距离,(4)以全指标个体距离矩阵d为依据,采用离差平方和法(ward方法)进行类型间的类型距离度量,完成样本的类型划分。(5)最终得到如图2所示的聚类分析的树形图。根据得到的层次聚类分析结果,可以将全国城镇化水平分为五类,其中,第一类:北京、天津、上海第二类:辽宁、广东、江苏、浙江第三类:吉林、黑龙江、山西、宁夏、山东、湖北、海南、内蒙古、福建、新疆、重庆、陕西第四类:河北、江西、湖南、安徽、河南、广西、四川、甘肃、青海第五类:贵州、云南为了说明新方法的优点,我们针对人口城镇化水平这一单独的变量也进行面板数据聚类分析。图3为综合四个变量进行面板数据聚类分析得到的城镇化类型聚类分析结果。图4展示的就是针对单一变量进行分析而得到的城镇化类型划分结果。从两个城镇化水平分类图可以明显看出,基于不同的聚类分析得到的城镇化水平类型划分有着显著差别。图3所展示的第一类和第五类省份个数分别为3个和2个,而第二类、第三类和第四类省份个数分别为4、12、9。在图4中,五个类别的省份个数则分别是3、3、6、10、8。相比较两种类型划分方法的分类结果,综合多指标的城镇化分类结果更符合正态分布。就统计意义而言,这一分类结果更符合统计原则。因此,这一分类方法在未来进行基于城镇化分类的相关扩展研究工作中,将提供更科学、更合理的技术基础。以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1