一种视频监控场景中的行为分析方法与流程
本发明涉及计算机视频处理技术领域,特别是一种视频监控场景中的行为分析方法。
背景技术:
复杂监控场景是指一些人流大、车流大、密度高的公共场所,如地铁、广场、公共交通路口等,这些场所包含多种并发的行为,且易发生群体性事件如果不能及时处理,会产生严重的影响。智能监控系统希望监控探头可以像人眼和大脑一样对监控场景中的行为进行分析。识别场景中的行为模式,包括行为之间的时空交互,是智能视频监控中的一个重要问题。目的是尽可能的采用无监督的方法检测出多个行为,并建立它们之间的时间依赖关系。通常,行为时空交互关系的识别可以用于更高层次的语义分析,比如,识别交通监控场景中不同的交通流,以及交通状态之间的转换,从而可以检测和阻止可能出现的交通混乱。然而在复杂视频监控场景中,检测并量化行为之间的相关性并不是一件易事。
基于概率主题模型的复杂监控场景行为分析方法,直接基于底层视频特征,无需进行目标检测和跟踪,具有较好的鲁棒性(参见:wangx,max,grimsonwel.unsupervisedactivityperceptionincrowdedandcomplicatedscenesusinghierarchicalbayesianmodels[j].ieeetransactionsonpatternanalysisandmachineintelligence,2009,31(3):539-555.)。概率主题模型是基于词袋表示方法的,根据词袋内视觉单词的共生来捕捉行为,完全忽略视觉单词的时间信息,且不对词袋之间的相关性建模。因此这类方法虽然对噪声鲁棒,但是以舍弃了行为之间的动态信息为代价,无法检测出行为之间的时间依赖关系。经对现有技术的检索发现,为了解决概率主题模型缺少时间信息的问题,一般有两类方法:一种是直接通过给单词添加时间戳来检测行为的时间模式(参见:emonetr,varadarajanj,odobezjm.extractingandlocatingtemporalmotifsinvideoscenesusingahierarchicalnonparametricbayesianmodel[c]//computervisionandpatternrecognition(cvpr),2011ieeeconferenceon.ieee,2011:3233-3240.)。但是这一类方法对时间过于敏感,造成检测出的一些类似的行为序列,因此存在语义混淆,此外这类方法无法检出全局交互行为。另一类方法是在概率主题模型中引入hmm模型,为行为在时域上的动态变化建立一个马尔科夫链,比如mctm(参见:hospedalest,gongs,xiangt.amarkovclusteringtopicmodelforminingbehaviourinvideo[c]//computervision,2009ieee12thinternationalconferenceon.ieee,2009:1165-1172.)、hdp-hmm(参见:kuetteld,breitensteinmd,vangooll,etal.what'sgoingon?discoveringspatio-temporaldependenciesindynamicscenes[c]//computervisionandpatternrecognition(cvpr),2010ieeeconferenceon.ieee,2010:1951-1958.)。但是这类方法一般是建立全局行为之间的状态转移,原子行为之间的时间关系模糊不清,限制了模型在时间关系方面的表现力。
技术实现要素:
本发明所要解决的技术问题是克服现有技术的不足而提供一种视频监控场景中的行为分析方法,本发明结合了概率主题模型,基于noisy-or假设,提出一种动态因果主题模型,利用非参格兰杰方法计算因果关系矩阵,在统一结构下实现原子行为的识别及它们之间因果关系的度量。从因果影响角度对行为进行排序,以期实现常态化监控和“高影响力”行为的识别。
本发明为解决上述技术问题采用以下技术方案:
根据本发明提出的一种视频监控场景中的行为分析方法,包括以下步骤:
第一步、利用tv-l1光流算法计算视频序列中相邻帧之间的光流特征,并对光流特征进行幅度去噪;
第二步、对去噪后的光流特征进行位置和方向的量化,每个光流特征根据其所在的位置和方向映射成一个视觉单词,将视频序列分割成不重叠的若干个视频片段,累积每个视频片段内包含的视觉单词,从而构建成每个视频片段所对应的视频文档;
第三步、利用动态因果主题模型对视频文档建模;
第四步、根据动态因果主题模型的模型参数,计算行为的因果影响力;
第五步、根据行为的因果影响力,对行为进行排序。
作为本发明所述的一种视频监控场景中的行为分析方法进一步优化方案,所述第一步中对光流特征进行幅度去噪具体如下:若光流特征的幅度值小于阈值thra,则将该光流去除。
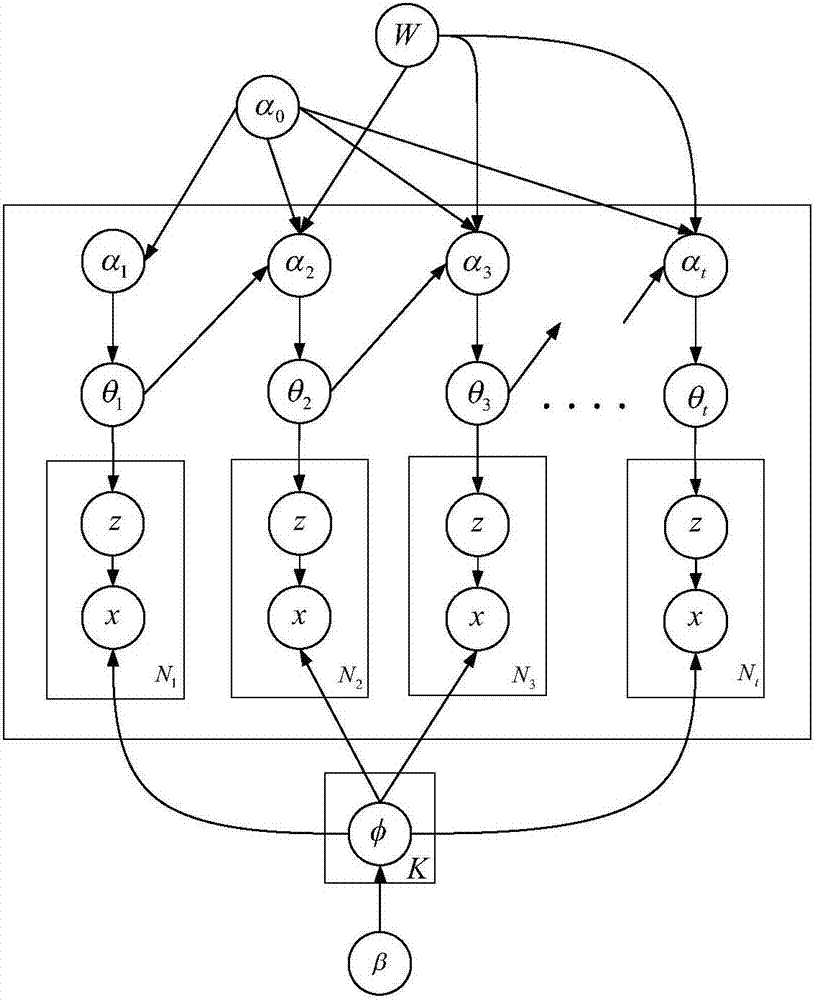
作为本发明所述的一种视频监控场景中的行为分析方法进一步优化方案,第三步中所述动态因果主题模型,具体包括:
1.定义主题数k;
2.初始化模型参数α0、β、θt、φk和w;其中,α0=[α0,k]∈rk表示初始先验参数,其中α0,k表示第k个主题对应的参数;
θt~dir(αt)表示狄利克雷文档-主题分布,其中,dir(αt)表示狄利克雷分布,αt表示狄利克雷分布的超参数,θt=[θt,k]∈rk,θt,k表示t时刻第k个主题的混合概率,rk表示维数为k的实向量;
φk~dir(β)表示狄利克雷主题-单词分布,其中,dir(β)表示狄利克雷分布,β表示狄利克雷分布的超参数,φk=[φk,v]∈rv,φk,v表示对于第k个主题第v个单词的混合概率,rv表示维数为v的实向量;初始化θt和φk,使得
3.对于时刻t的视频文档dt,估计当前时刻的先验参数αt=[αt,k]∈rk
αt=pt+α0
其中,αt,k表示第k主题对应的超参数,pt=[pt,k]∈rk表示t时刻的先验主题分布,其中
4.采用吉布斯采样算法进行主题的后验概率估计,在条件概率中,将参数θt和φk积分掉,具体如下:
其中,zt,i表示单词xt,i对应的主题,p(zt,i=k|z-t,i,d,αt,β)表示zt,i是第k个主题的概率,d表示训练数据集;z-t,i表示除过zt,i的所有的主题,
5.更新狄利克雷文档-主题分布θt:
其中:nt,k表示文档dt中第k个主题的数目;
6.重复步骤3-5,直到遍历完所有的视频文档;更新狄利克雷主题-单词分布φk:
其中,nk,v表示整个视频序列中与第k个主题相关的第v个单词的数目;
7.更新因果矩阵w:
并对w进行归一化使得其值位于0和1之间;
其中,
8.重复步骤3-7直到采样结束。
作为本发明所述的一种视频监控场景中的行为分析方法进一步优化方案,所述第四步中计算行为的因果影响力,具体如下:
基于因果矩阵w,计算第m个主题的影响力tm,该tm即为行为的因果影响力:
作为本发明所述的一种视频监控场景中的行为分析方法进一步优化方案,所述第五步中,基于影响力对行为进行排序。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
(1)本发明提出了一种新的动态因果主题模型;
(2)在主题推理过程中将高层因果反馈作为底层的先验信息,即利用上层计算出的主题间因果关系来改善下层的主题的检测性能;
(3)基于学习到的因果矩阵,可以实现主题的因果排序,从而识别出场景中的高影响力行为。
附图说明
图1是复杂视频监控场景行为分析总流程框图。
图2是动态因果主题模型。
图3是复杂视频监控场景的行为。
图4是行为排序。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
实施例
本实施采用的视频序列来自数据库qmul(thequeenmaryuniversityoflondon)交通数据库,帧率为25pfs,分辨率为360×288。qmul数据库来自于伦敦大学玛丽皇后学院,是专门用于复杂视频监控场景分析的数据库。图1是复杂视频监控场景行为分析总流程框图,本实施例中行为的建模是通过本发明的动态因果主题模型实现的,技术方案包括以下步骤:
本实施例涉及的视频底层时空特征提取方法,包括如下具体步骤:
本发明是通过以下技术方案实现的,包括以下步骤:
第一步:利用tv-l1光流算法计算视频序列中相邻帧之间的光流特征,并对光流进行幅度去噪,即若光流特征的幅度值小于阈值thra,则将该光流去除。
本实施例thra=0.8。
第二步:对去噪后的光流特征进行位置和方向的量化,将视频序列表示成词袋模式。具体措施包括,
1)构建视觉词典。每个运动像素都包含两个特征:位置和方向。为了对位置进行量化,整个场景被分割成36×29的网格,每个网格单元大小10×10。然后运动方向均匀量化为8个。因此,可以构建出一个规模为v=8352(36×29×8)的视觉词典。每个光流特征根据其所在的位置和方向映射成一个视觉单词。
2)构建视觉文档。
将视频序列分割成时长dt=3s的不重叠的nt=1199个视频片段,每个视频文档dt由其所包含的视觉单词累积而成。
第三步:利用动态因果主题模型对场景中的行为进行建模。
具体步骤为:
1.定义主题数,本实施例中k=21。
2.初始化模型参数α0、β、θt、φk和w;其中,α0=[α0,k]∈rk表示初始先验参数,其中α0,k表示第k个主题对应的参数,本实施例中α0,k=0.5;
θt~dir(αt)表示狄利克雷文档-主题分布,其中,dir(αt)表示狄利克雷分布,αt表示狄利克雷分布的超参数,θt=[θt,k]∈rk,θt,k表示t时刻第k个主题的混合概率,rk表示维数为k的实向量;
φk~dir(β)表示狄利克雷主题-单词分布,其中,dir(β)表示狄利克雷分布;β表示狄利克雷分布的超参数,本实施例中β=0.02;φk=[φk,v]∈rv,φk,v表示对于第k个主题第v个单词的混合概率,rv表示维数为v的实向量;初始化θt和φk,使得
3.对于时刻t的视频文档dt,估计当前时刻的先验参数αt=[αt,k]∈rk
αt=pt+α0
其中,αt,k表示第k主题对应的超参数,pt=[pt,k]∈rk表示t时刻的先验主题分布,其中
4.采用吉布斯采样算法进行主题的后验概率估计,在条件概率中,将参数θt和φk积分
掉,具体如下:
其中,zt,i表示单词xt,i对应的主题,p(zt,i=k|z-t,i,d,αt,β)表示zt,i是第k个主题的概率,
d表示训练数据集;z-t,i表示除过zt,i的所有的主题,
的数目,
dt中主题zt,i的数目,
5.更新狄利克雷文档-主题分布θt:
其中:nt,k表示文档dt中第k个主题的数目;
6.重复步骤3-5,直到遍历完1199个视频文档;更新狄利克雷主题-单词分布φk:
其中,nk,v表示整个视频序列中与第k个主题相关的第v个单词的数目;
7.更新因果矩阵w:
并对w进行归一化使得其值位于0和1之间;
其中,
8.重复步骤3-7直到采样迭代结束。在本实施例中采样迭代2500次。
第四步:基于因果矩阵w,计算第m个主题的影响力tm,该tm即为行为的因果影响力:
第五步:按照影响力测度对行为进行排序,本实施例子中行为排序为:
最低t15,1≤t3,2≤t5,2≤...≤t6,22最高。
通过实验证明,本实施例较之以前方法能很好的复杂监控场景行为建模,并能对场景中的行为按照影响力排序。图2是动态因果主题模型;图3是复杂监控场景中的行为;图4是对图3中行为按照影响力进行排序结果。由图4所示可以看出,按照影响力进行排序与按照比例进行排序的结果并不一致,这意味着行为所占的时空比例大并不意味着影响力大,因此本发明结果蕴含丰富的语义信息便于后续的进一步处理。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替代,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!