基于词典的网络舆情信息情感分类方法与流程
本发明涉及一种基于词典的网络舆情信息情感分类方法。
背景技术:
随着网络舆论成为社会舆论的一种重要表现形式,网络舆情也逐渐对有关部门的决策产生了影响。但由于网络舆论是个“自由超市”,加上内容“把关人”的缺席,网络舆论的局限性比起传统媒体环境中一般意义上的局限更甚。因此,必须对网络舆论信息进行有效的汇集以及整理,以作进一步的引导和控制。
舆情工作者每天面对海量的舆论信息,想要及时发现负面敏感信息是非常困难的,亟需完善的文本情感分类方法。近年来,网络舆情信息情感的分类方法也在不断被研究人员推陈出新,现有的主要计算方法有:
1)基于贝叶斯分类器的分类方法
收集一定比例的正面、中性、负面情感文本语料库,将文本通过分词工具预处理,得到每一种情感分类下的词汇集合和相应的概率。通过贝叶斯分类器进行机器学习,在待分类文本到来时,分别计算文本属于正面、中性、负面三类集合的概率,得到概率值后,认定文本属于概率值较大的一类,得到情感倾向分析结果。
2)基于词典和极性的分类方法
人工构建情感词典库,其中标注有词汇、分值、极性,同时引入极性判断规则,在文本极性发生变化时,相应的情感得分值会取反。在待分类文本到来时,参考预置的情感词典库,对每一个情感词汇计算得分值,汇总所有的情感词汇分值后,比对预先测算出的阈值,判断目标值所处的区间,以得到文本所属的情感分类。
现有技术的缺点如下:
1)贝叶斯分类器模型依赖于其学习的语料库,语料库的收集和全面性是一大难题。另外,汉语言的复杂性、语境问题也使得分类结果会产生较大偏差。
2)舆情领域的情感词典随着经验的积累会相对完善,但单纯考虑情感词极性对篇章情感的影响不够全面,忽略了词性、语义这些对情感结果作用的因素。
技术实现要素:
本发明要解决的技术问题是提供一种基于词典的网络舆情信息情感分类方法。该方法通过基础情感词典库,对待分类文本进行分词后,结合词典分值、篇章结构、语义和句法多种因素对待分类文本进行情感分类,以得到相对更准确的情感分类结果。
为了解决上述技术问题,本发明采用的技术方案是,基于词典的网络舆情信息情感分类方法,包括以下步骤:
一、构建词典
通过人工收集和标注的形式构建情感词词典、否定词词典、程度词词典库;
情感词词典包含词汇、词性、情感强度、极性四个属性;否定词词典包含词汇一个属性;程度词词典包含词汇、强度两个属性;
二、待分类文本拆分
按照篇章-段落-句子-意群子句的结构对待分类文本进行拆分,得到若干意群子句;
三、计算意群情感分值
对每一意群子句采用hanlp分词包分词,得到词汇和词性信息,记为词汇组;
遍历词汇组中的每一个词汇,同时标记程度词和否定词出现的位置,依据词性类别从情感词典中取出情感强度,记为得分值,在词汇极性为负面时取反;如果情感词前出现程度词,则分值在原有基础上乘以程度词强度值;如果情感词前出现否定词,则分值在原有基础上取反,否定词作用可累加;词汇组中每一个词汇得分值累加后得到的是意群情感分值;
四、计算文本情感分值
将意群子句情感分值按照文本篇章结构逆向合并即可得到文本情感分值,过程如下:
1)将句子中各意群子句分值累加得到句子分值;
2)将段落中各句子分值取均值得到段落分值;
3)将篇章中各段落分值取均值得到文本篇章分值;
4)由文本篇章分值落入的区间范围,判定文章情感倾向性。
本发明的有益效果是:
通过基于构建的词典库,结合文本篇章结构、句法分析内容,充分考虑意群子句中否定词、程度词的作用和情感词词性的影响,能够更为准确地计算出文本篇章所表述出的情感倾向性,能更好地适用于网络舆情信息情感分类。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1是本发明基于词典的网络舆情信息情感分类方法实施例的结构示意图。
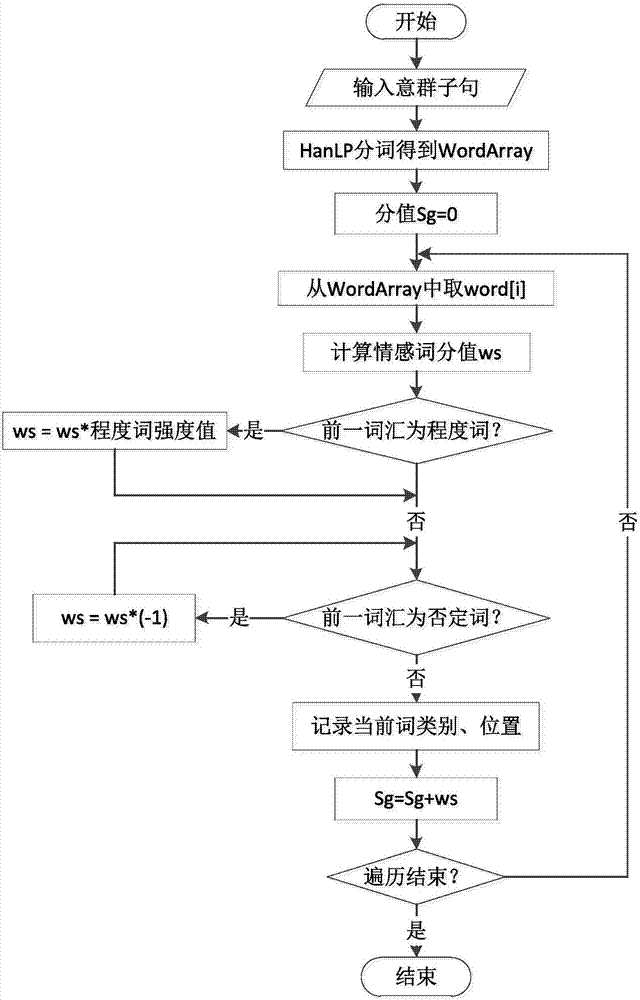
图2是本发明基于词典的网络舆情信息情感分类方法实施例的意群子句情感分值计算的流程图。
图3是本发明基于词典的网络舆情信息情感分类方法实施例的意群子句逆向合并得到文本篇章情感值的过程示意图。
具体实施方式
一种基于词典的网络舆情信息情感分类方法,包括以下步骤:
一、构建词典
通过人工收集和标注的形式构建情感词词典(sentilib)、否定词词典(negativelib)、程度词词典(degreelib)库。
情感词词典包含词汇(word)、词性(feature)、情感强度(strength)、极性(polar)四个属性;否定词词典包含词汇(word)一个属性;程度词词典包含词汇(word)、强度(strength)两个属性。
二、待分类文本拆分
按照篇章-段落-句子-意群子句的结构对待分类文本进行拆分,得到若干意群子句。主要包含以下步骤(图1):
1)将文本按照篇章结构拆分成段落集合ps=[p1,p2,…,pn];
2)对每一个段落按照句子结构拆分成句子集合sts=[st1,st2,…,stm];
3)对每一个句子按照逗号“,”分隔符拆分成意群子句集合gs=[g1,g2,…,gk]。
三、计算意群情感分值
对每一意群子句gi采用hanlp分词包分词,得到词汇和词性信息,记为词汇组wordarray=[word1,word2,…,wordn]。
意群子句gi情感分值sg由词汇组得分值合并得来,遍历词汇组中的每一个词汇word[i],按照以下规则计算分值:
1)将情感词典中标注的情感强度记为得分值ws,在词汇极性为负面时取反ws=ws*(-1);
2)如果情感词前出现程度词,则分值在原有基础上乘以程度词强度值ws=ws*degree;
3)如果情感词前出现否定词,则分值在原有基础上取反ws=ws*(-1);如连续出现否定词,则依次取反ws=ws*(-1);
4)将当前词汇得分值纳入意群子句分值中sg=sg+ws。重复以上步骤直至本意群子句中所有词汇分值计算结束。
图2是上述意群子句情感分值计算的流程图。
四、计算文本情感分值
将意群子句情感分值按照文本篇章结构逆向合并即可得到文本情感分值。如图3所示,过程如下:
1)将句子中各意群子句分值累加得到句子分值sc=sg[0]+sg[1]+…+sg[k];
2)将段落中各句子分值取均值得到段落分值sp=(sc[0]+sc[1]+…sc[n])/m;
3)将篇章中各段落分值取均值得到文本篇章分值s=(sp[0]+sp[1]+…sp[n])/n;
4)由文本篇章分值落入的区间范围,判定文章情感倾向性。s∈(-∞,-1]时,文本情感倾向于负面;s∈(-1,5]时,文本情感倾向于中性;s∈(5,+∞)时,文本情感倾向于正面。
案例
假定要对文本:“记者在基层调研发现,受利益驱使,企业环保数据造假的行为仍旧屡禁不止。不断涌现出来的环保数据造假使数据失真,进而影响环保治理决策,长此以往终究危及环境。”进行情感分类,如图2所示,过程如下:
1、构建词典
通过人工收集和标注的形式构建情感词词典sentilib、否定词词典negativelib、程度词词典库degreelib。
2、待分类文本拆分
1)段落集合ps=[p1],其中p1=“记者在基层调研发现,受利益驱使,企业环保数据造假的行为仍旧屡禁不止。不断涌现出来的环保数据造假使数据失真,进而影响环保治理决策,长此以往终究危及环境。”;
2)句子集合sts=[st1,st2],其中st1=“记者在基层调研发现,受利益驱使,企业环保数据造假的行为仍旧屡禁不止。”,st2=“不断涌现出来的环保数据造假使数据失真,进而影响环保治理决策,长此以往终究危及环境。”;
3)意群子句集合gs1=[g11,g12,g13],gs2=[g21,g22,g23],其中g11=“记者在基层调研发现”,g12=“受利益驱使”,以此类推。
3、计算意群情感分值
1)对意群子句g11采用hanlp分词包分词,得到wordarray=[记者/nnt,在/p,基层/n,调研/vn,发现/v];
2)依规则计算得到sg=ws1+ws2+ws3+ws4+ws5=1.0;
3)重复以上步骤,计算出所有的sg。
4、计算文本情感分值
1)句子分值sc[0]=sg1[0]+sg1[1]+sg1[2]=-9.0,
sc[1]=sg2[0]+sg2[1]+sg2[2]=-5.0;
2)段落分值sp[0]=(sc[0]+sc[1])/2=-7.0;
3)文本篇章分值s=(sp[0])/1=-7.0;
4)本例中s∈(-∞,-1],文本情感倾向于负面。
以上所述的本发明实施方式,并不构成对本发明保护范围的限定。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明的权利要求保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!