一种优化数据流架构访存延迟的方法及其系统与流程
本发明涉及数据流架构当中访存指令的执行方式,特别涉及降低访存指令延迟的方法和系统。
背景技术:
随着计算机体系结构的发展,领域专用的计算机体系结构成为主要发展趋势。在面向特定应用时,专用型结构利用应用特征对结构进行相应的优化,从而更好地发挥出硬件的计算性能。在高性能计算领域,数据流计算是领域专用计算结构的一个重要分支,数据流计算表现出了较好的性能和适用性。数据流指令执行的基本原则是:所有的源操作数都准备好了,并且下游节点有空闲的数据槽可以接收数据,则该指令即可执行。在数据流计算模式中,源指令(生产者)执行的结果不会写入共享寄存器或共享缓存,而是直接传递给目的指令(消费者)。
针对传统数据流架构当中的访存指令,尤其是load指令,数据传递方式如图1所示。在这个例子当中,pe3节点103当中的一条load指令,要从spm节点105取出load数据,发送给pe9节点101的源操作数槽。要想完成这样一条指令,需要经历3个步骤:
在这个过程中,pe3节点103是上游节点,pe9节点101是下游节点。
步骤101:下游节点101的源操作数槽(sourceoperand)空闲之后,通过网络102向上游节点103发送“ready”消息;
步骤102:上游节点103通过网络104向片上缓存spm节点105发出数据请求;
步骤103:片上缓存spm节点105通过网络106把取出的load数据发送给下游节点101;
从时间轴107可以看出,最差情况下,三段步骤的时间是完全串行的。这种情况下load指令的延迟完全取决于上游节点、下游节点以及片上缓存spm的相对距离和位置,没有任何可以优化的余地。
技术实现要素:
针对现有技术中数据访存指令的数据传输延迟较大的问题,本发明提出了一套优化和降低load指令传输延迟的方法和系统,具体技术方案如下:
一种优化数据流架构访存延迟的方法,包括以下步骤:
s1:上游节点对下游节点反馈空闲状态的时间进行预测,并将得到的预测时间与一阈值进行比较;当所述预测时间小于所述阈值时,执行推测模式进行数据访存;当所述预测时间小于所述阈值时,执行三段式握手模式进行数据访存;
s2:所述推测模式的执行步骤为:所述上游节点向片上缓存节点发送带有令牌信息的数据包,并同时向下游节点发送令牌信息;所述片上缓存节点将所述带有令牌信息的数据包发送给下游节点;所述下游节点将从所述片上缓存节点中收到的数据包中的令牌信息与从所述上游节点收到的令牌信息进行比较;如果两个令牌信息的比较结果一致且所述下游节点的指令槽为空闲状态,则所述下游节点向所述上游节点发送确认信息;
s3:如果两个令牌信息的比较结果不一致或者所述下游节点的指令槽不为空闲状态,则所述下游节点丢弃来自片上缓存节点的数据包和来自上游节点的令牌信息,不向所述上游节点反馈任何信息;待所述下游节点的指令槽为空闲状态时,执行三段式握手模式进行数据访存。
根据本发明提出的优化数据流架构访存延迟的方法,其中,每个数据访存指令需要单独计算预测时间。
根据本发明提出的优化数据流架构访存延迟的方法,其中,所述阈值是通过软件profiling的方式得到的。
本发明同时还提出一种优化数据流架构访存延迟的系统,在数据流架构的每个节点上包括以下部件:
访存计数器:用于计算当上游节点发出数据访存指令时,从下游节点的源操作数空闲状态到上游节点的目的操作数空闲状态之间的时间差;
阈值存储器,用于保存一预设的时间阈值;
预测位,与所述访存计数器和所述阈值存储器相连,根据所述时间差和所述时间阈值的比较结果来确定执行推测模式或三段式握手模式进行数据访存;
令牌管理部件,与所述预测位相连,当所述预测位确定执行推测模式时,所述令牌管理部件用于分别向上游节点和下游节点发送令牌信息;
令牌确认部件,与所述令牌管理部件相连,用于将所述下游节点接收到的令牌信息与来自片上缓存节点的访存数据包中包含的令牌信息进行比较,如果两个令牌信息的比较结果一致且所述下游节点的指令槽为空闲状态,则所述下游节点向所述上游节点发送确认信息;如果两个令牌信息的比较结果不一致或者所述下游节点的指令槽不为空闲状态,则所述下游节点丢弃来自片上缓存节点的数据包和来自上游节点的令牌信息,不向所述上游节点反馈任何信息;待所述下游节点的指令槽为空闲状态时,执行三段式握手模式进行数据访存。
根据本发明提出的优化数据流架构访存延迟的系统,其中,每个数据访存指令需要单独计算预测时间。
根据本发明提出的优化数据流架构访存延迟的系统,其中,所述阈值是通过软件profiling的方式得到的。
与现有技术相比,本发明针对传统数据流架构的数据传输特点,通过在数据流架构的每个节点增加针对访存延迟的预测、训练、和令牌机制,有效地优化访存指令的传输延迟,从而提高整个数据流架构的执行效率和数据吞吐率。
附图说明
图1为传统数据流架构当中load指令的数据传递过程图;
图2为本发明的数据流架构当中load指令的数据传递过程图;
图3为本发明的数据流架构的节点当中新增部件的结构示意图;
图4为本发明的实施例流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
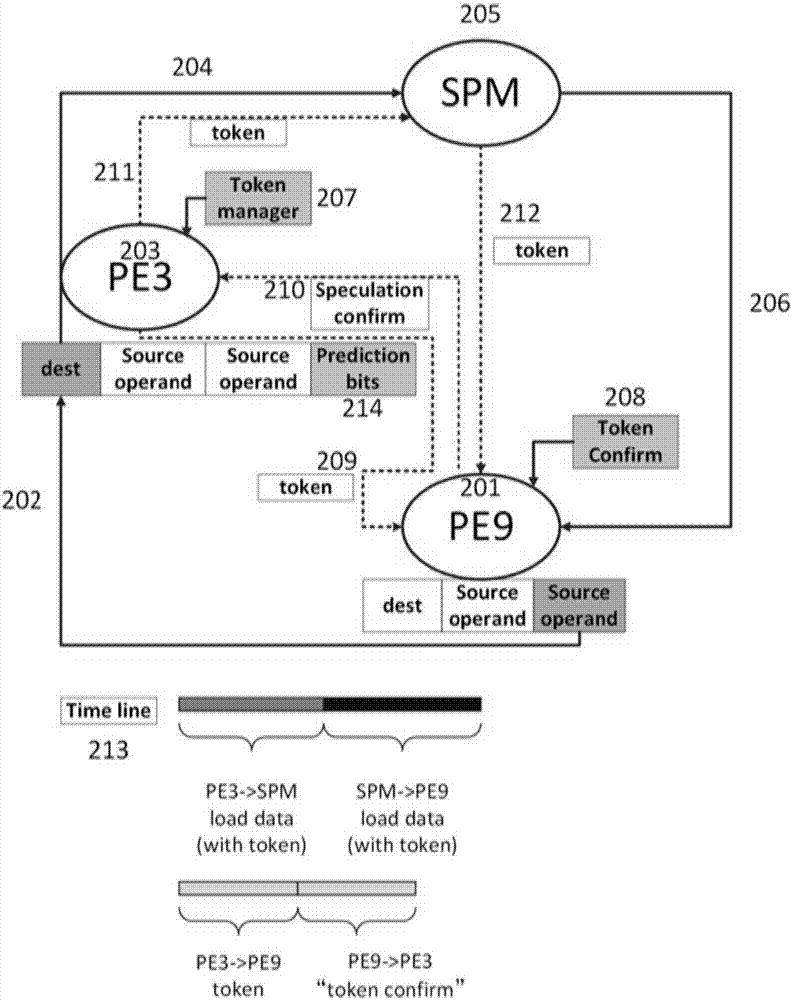
本发明提出的优化方法主要包括3个方面,分别是预测、令牌管理、推测执行和令牌确认。具体步骤和结构如图2所示:
预测和令牌管理:在数据流架构的每个执行节点当中设置预测部件,为节点当中的每个指令槽增加预测位214、令牌管理部件207和令牌确认部件208。针对访存指令(load指令)等待下游节点反馈“ready”状态的时间进行预测和训练;训练结果会得到一个阈值n。如果一条load指令等待下游节点“ready”的时间小于阈值n,认为是“taken”的结果,该结果会保存在指令槽的预测位214当中;如果一条load指令等待下游节点“ready”的时间大于阈值n,认为是“non-taken”的结果,该结果会保存在指令槽的预测位214当中。
推测执行:这个步骤是基于预测的结果。如果一条load指令等待下游的时间总是小于阈值,那么预测位214保存的结果是“taken”,那么该指令不用等待下游节点反馈的“ready”状态,就可以同时向下游节点201和片上缓存spm节点205发送带有令牌的消息。其中,通过网络209从上游节点203发送给下游节点201的消息,是向该下游节点发送令牌信息。通过网络211从上游节点203发给spm节点205的消息,是带有令牌信息的取load数据请求的数据包。当spm节点205把load数据取出后,通过网络212向下游节点发送带有令牌信息的load数据。
令牌确认:当下游节点201收到来自上游节点203的令牌消息和来自spm节点205的load数据之后,会把两者之间的令牌进行比较,如果令牌一致并且此时下游节点201的指令源数据槽也空闲的话,该load数据接收成功。下游节点201通过网络210向上游节点203发送“推测执行确认”消息,表明本次推测执行成功。
也需要考虑推测执行不成功的情况,也就是当下游节点201收到来自上游节点203的令牌消息和来自spm节点205的load数据之后,发现自己的指令源数据槽还没有空闲,那么此时丢弃来自spm节点205的load数据和来自上游节点203的令牌消息,不向上游节点反馈任何确认消息。本次推测执行失败。等到该下游节点指令源数据槽空闲之后,还是按照传统数据流结构当中的方式传递load数据。并且上游节点203根据实际的执行情况调整它内部的预测部件当中的预测值。
从时间轴213可以看出,推测执行成功的话,可以把原本3段串行的步骤变成2段并行的步骤,大大缩短了访存(load)指令的数据传输延迟。
请继续参阅图3,示出了本发明的优化系统中数据流架构每个节点需要增加的部件,具体包括:
(1)load计数器301:用于表示这条load指令从所有的源操作数都ready到目的操作数“ready”之间的时间差;其中,目的操作数“ready”是来自下游节点的反馈;每条load指令需要单独设置。
(2)预测位302:由2个比特位组成,2’b11表示taken,2’b00表示non-taken;中间的2’b10和2’b01属于过渡状态;每条load指令需要单独设置。
(3)阈值存储寄存器303:每个节点设置一个;这个阈值的数值通过软件profiling的方式得到。
(4)令牌管理部件304:每次有load指令需要采用推测执行方式的时候,该部件负责发放令牌;在数据流架构当中,令牌由两部分组成,即节点号和令牌编号;针对每个节点设置。
(5)令牌确认部件305:每次当节点接收到来自片上缓存节点的load数据包和来自上游节点的令牌数据包之后,需要在节点内针对两个令牌进行比较,如果一致并且下游节点的源操作数指令槽空闲的话,表示推测执行成功;如果令牌不一致或者下游节点的源操作数指令槽不空闲的话,表示推测执行失败。
当load计数器的数值大于阈值存储寄存器时,预测位加1;当load计数器的数值小于阈值存储寄存器时,预测位减1。针对预测位的加法和减法都采用饱和计算的方式。
当一条load指令执行的时候,根据预测位的数值决定其执行流程。
如图4所示,上游节点401当中,一条load指令的目标操作数字段408,要把load数据发送到下游节点409当中指令槽421的源操作数字段410。
如果上游节点401的load指令对应的预测位403的数值为2’b11,表示要针对这条load指令采用推测执行的方式。由令牌管理部件405产生本次load指令对应的令牌。
上游节点401针对load指令产生数据包的时候会加入令牌管理部件405产生的令牌,通过网络414向spm节点411发送带有令牌消息的数据包;spm节点411接收到带有令牌的数据包之后,会按照正常的步骤取出load数据,然后把load数据和对应的令牌通过网络412发送给下游节点409。
下游节点409可能会先收到通过网络412传递的来自spm节点411的带有令牌的数据包,也可能先收到通过网络415传递的来自上游节点401的令牌数据包。当两个数据包都收到之后,下游节点409会针对通过令牌确认部件416对两个数据包当中的令牌进行比较确认。
在下游节点409当中,如果令牌比对通过,同时对应load指令的目标指令槽421也“ready”的话,该指令槽421可以接收来自spm节点411的load数据,本次推测执行成功;如果对应load指令的目标指令槽421没有“ready”的话,丢弃来自spm节点411的load数据,本次推测执行失败;
在下游节点409当中,如果load指令的目标指令槽421成功接收了推测执行的load数据,下游节点409需要向上游节点401发送确认消息422,表示本次推测执行成功。如果在下游节点409当中,load指令的目标指令槽421没有成功接收推测执行的load数据,下游节点409不需要向上游节点401发送任何消息。等到该指令槽421“ready”之后,采用传统的执行方式向上游节点401发送“ready”消息,上游节点401等到指令槽的源操作都准备好之后,向spm节点411发送load请求,spm节点411把load数据发送给下游节点409。
在上游节点401当中,如果收到了来自下游节点409的推测执行成功的确认消息422,更新预测位403,进行饱和加1的操作;如果上游节点401发出了推测执行的消息但是没有收到来自下游节点的推测执行成功的确认消息反而收到的是“ready”消息,上游节点401同样需要更新预测位403,进行饱和减1的操作。
另外,在上游节点401当中,如果load指令对应的预测位403的数值是2’b10,2’b01,2’b00的话,表示该load指令不采用推测执行的方式,而是采用传统的load数据传递方式。即三段式握手模式,如图1所示。
本领域普通技术人员可以理解:附图只是一个实施例的示意图,附图中的模块或流程并不一定是实施本发明所必须的。
本领域普通技术人员可以理解:实施例中的装置中的模块可以按照实施例描述分布于实施例的装置中,也可以进行相应变化位于不同于本实施例的一个或多个装置中。上述实施例的模块可以合并为一个模块,也可以进一步拆分成多个子模块。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!