一种基于多元化地理信息点的融合方法与流程
本发明涉及一种基于多元化地理信息点的融合方法,属于地理信息处理技术领域。
背景技术:
近年来,随着网络的大规模发展,各种信息资源的数量急剧增长,计算机对地理名称、坐标信息等各种自然语言处理应用的普及,人们需要一个快速且准确的方法来计算多个地理信息点之间的信息相似度。尤其,短文本相似度的计算具有十分重要的作用,它的应用能够极大地提高识别多个地理信息点的精度。另外,地图中的经纬度信息对于邻近区域的查询具有很大的便利,建立地理信息点的融合方法对查询起到非常重要的作用。
对于约占人类信息80%左右的地理信息来说,由于具有分布性、多样性、复杂性的特点,给地理信息的共享和操作带来了许多不便。大部分地理信息是表示在不同地图上的,面对浩如烟海的地理信息,能够快速、准确、高质量地从中抽取出用户所关心、真正有用的信息这一需求日益迫切,然而,对于提取到的地理信息处理手段较弱,导致信息排查困难和信息利用率低下。同时,目前地理信息资源的提供者对数据的描述值停留在数据的表明层次上,数据之间缺乏必要的关联,从而直接影响到用户获取信息的速度和效率。快速并高质量的融合方法可以将大量地理信息进行分类处理,找出匹配的信息点,以及不匹配的信息点,从而通过这种方法来减轻工作量,方便人们对地理信息的充分利用。
由于越来越多的短文本应用的出现,比如电子文本,地理信息和地图信息,人们对短文本处理的需求日益迫切。但是对于短文本而言,因为相似的短文本并不一定有相同的词,自然语言的灵活性使得人们可以通过不同的措词表达相同的意思,所以现有的相似度计算方法应用效果并不很好,例如在对地理位置名称的数据处理中表现不佳。此外,传统的文本相似度计算过程中,对文本的表达方式通常去掉停用词,比如“的”,“是”,“中”等等,但是在对短文本的处理过程中,因为它们蕴含了一些句子的结构信息,所以一些停用词不能被忽略,这使得传统的文本相似度计算方法在处理短文本的文本相似度计算过程中不能得到很好的结果。
对文本相似度计算而言,常用的文本间相似度计算方法是余弦相似度方法,该方法将文本看作空间中的一个点并将其表示为向量形式,利用向量之间的夹角大小来定量地计算文本间相似度,该方法没有考虑文本间具有相同语义的特征词,不能充分体现文本之间的语义相似性。因此,现有相似度计算方法存在大量的缺点和疏漏。
技术实现要素:
本发明要解决的技术问题是提供一种基于多元化地理信息点的融合方法,通过在不同地理参考坐标系的地图中找到某个相同的区域,进行地理信息数据匹配并寻找出不同地图的地理信息是否有相同的信息点。
本发明的技术方案是:一种基于多元化地理信息点的融合方法,具体步骤为:
(a)、信息提取及预处理:在不同地理参考坐标系的地图中,首先进行地图坐标的变换,再找到某个相同区域的地理信息点,然后将提取到的地理信息按照地理名称、经纬度坐标等不同类别进行分类;
(b)、地理信息中的地理名称首先定义相似度:包括分词后的相似度处理、命名实体识别后的相似度处理、排列组合和加法运算四个步骤,根据计算两个相似度值得出的结果情况来判断,如果不相似,则匹配结束,多个地理信息点的地理名称不相同;如果相似或不确定,则进行多个地理信息点经纬度距离之间的匹配;
(c)、经纬度信息处理:通过计算多个地理信息点两两之间的经纬度距离来判断,如果两两之间的距离差值大于某一个门限δ,则这几个地理信息点不匹配;如果两两之间的距离差值小于某一个门限δ,则这几个地理信息点匹配。
(d)、相似度结果情况展示:根据得出的最终结果情况,在不同的地图上用不同的颜色标注出来,来判定是否为同一地理信息点。
所述步骤(b)中地理名称的相似度处理,具体包括如下步骤:
(b1)、根据文本分词后的结果计算得到一个相似度值;
(b2)、根据文本命名实体识别后的结果计算得到另一个相似度值;
(b3)、通过排列组合和加法运算来得出最终的结果情况;
(b4)、判断多个地理信息文本是否相似。
所述步骤(b1)中计算句子相似度包括下列步骤:
(b11)、给定一个句子x1,经过汉语分词系统分词后,得到的所有词yi构成句子x1的向量表示,分词后的向量表示x1=[y1,y2,......,yn];给定句子x2,同理,分词后的向量表示x2=[y1,y2,......,ym];
(b12)、x1中词的个数是x1的向量长度,用len(x1)表示;同理,x2的向量长度表示为len(x2);
(b13)、将x1、x2中所有的所有词yi进行合并,对于重复出现的词只保留一个,由此得到两个向量之和,称为x1、x2的并集,表示x=x1ux2=[y1,y2,......,ym,yn],则并集长度len(x)<=len(x1)+len(x2);
(b14)、依次计算x1和x2的集合x中的y1、y2、......、ym、yn在x1中每一个词的相似度(值为0到1之间),并将所有结果中的最大值称为yi在x1中的语义分数,用zi表示;x中每个分词的语义分数组成的一个向量称为x1基于x的语义向量,表示为w1=[z1,z2,...,zn],对于x中的每一个词yi,如果yi在x1中出现,则在语义向量w1中将yi的语义分数zi设为1;如果x1中不包含yi,则计算yi在x1中的语义分数zi=n(n为预先设定的阈值,无阈值设为0,本文中阈值为0.2);
(b15)、语义向量计算语义相似度的计算公式如下:
所述步骤(b3)中还包括下列步骤:
步骤(b31)、把步骤(b1)中和步骤(b2)中得到的多种地图的相似度值通过一个排列组合,全部排列起来;
步骤(b32)、把排列起来的相似度值通过加法运算,即全部相加;
步骤(b33)、把加起来的相似度值用一个门限m来控制。
所述步骤(b4)中还包括下列步骤:
(b41)、若加法后的相似度值小于门限m,则不相似,匹配结束,多个地理信息文本不相同;
(b42)、如果加法后的相似度值大于门限m或在门限m附近,认为相似或不确定,则进行多个地理信息点经纬度距离之间的匹配。
计算多个地理信息点两两之间的经纬度距离,是通过下列公式来计算的(计算的结果单位为米):
wgs84_a=6378137.0为赤道上到地球中心的地球半径距离,单位为米;
d=d×π÷180为角度转化成弧度,其中,d为角度;
rade1=rad(e1);
rade2=rad(e2);
a=rade1–rade2为两点纬度之差;
b=rad(n1)-rad(n2)为两点经度之差;
s=s1×wgs84_a
其中,e1表示a点纬度,n1表示a点经度,e2表示b点纬度,n2表示b点经度。
本发明的有益效果是:本发明的地理信息点的融合方法改变了人工查询方式的机械性和低效率;地理信息点的融合方法显著提高短文本查询的效率以及文本间语义相似度计算的准确性。
附图说明
图1是本发明实施例基于两种地图的地理信息点的融合方法流程图;
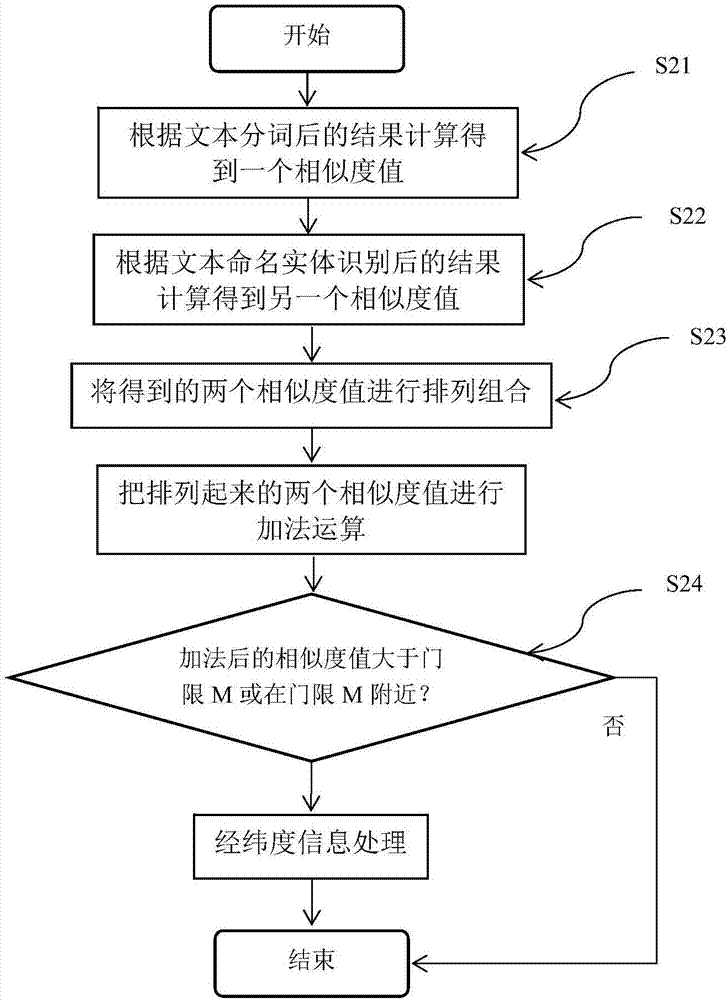
图2是本发明实施例中地理名称的相似度处理流程图;
图3是本发明实施例基于两种地图的地理信息点的融合方法的结构示意图。
具体实施方式
下面结合附图和具体实施方式,对本发明作进一步说明。
实施例1:一种基于多元化地理信息点的融合方法,具体步骤为:
(a)、信息提取及预处理:在不同地理参考坐标系的地图中,首先进行地图坐标的变换,再找到某个相同区域的地理信息点,然后将提取到的地理信息按照地理名称、经纬度坐标等不同类别进行分类;
(b)、地理信息中的地理名称首先定义相似度:包括分词后的相似度处理、命名实体识别后的相似度处理、排列组合和加法运算四个步骤,根据计算两个相似度值得出的结果情况来判断,如果不相似,则匹配结束,多个地理信息点的地理名称不相同;如果相似或不确定,则进行多个地理信息点经纬度距离之间的匹配;
(c)、经纬度信息处理:通过计算多个地理信息点两两之间的经纬度距离来判断,如果两两之间的距离差值大于某一个门限δ,则这几个地理信息点不匹配;如果两两之间的距离差值小于某一个门限δ,则这几个地理信息点匹配。
(d)、相似度结果情况展示:根据得出的最终结果情况,在不同的地图上用不同的颜色标注出来,来判定是否为同一地理信息点。
所述步骤(b)中地理名称的相似度处理,具体包括如下步骤:
(b1)、根据文本分词后的结果计算得到一个相似度值;
(b2)、根据文本命名实体识别后的结果计算得到另一个相似度值;
(b3)、通过排列组合和加法运算来得出最终的结果情况;
(b4)、判断多个地理信息文本是否相似。
所述步骤(b1)中计算句子相似度包括下列步骤:
(b11)、给定一个句子x1,经过汉语分词系统分词后,得到的所有词yi构成句子x1的向量表示,分词后的向量表示x1=[y1,y2,......,yn];给定句子x2,同理,分词后的向量表示x2=[y1,y2,......,ym];
(b12)、x1中词的个数是x1的向量长度,用len(x1)表示;同理,x2的向量长度表示为len(x2);
(b13)、将x1、x2中所有的所有词yi进行合并,对于重复出现的词只保留一个,由此得到两个向量之和,称为x1、x2的并集,表示x=x1ux2=[y1,y2,......,ym,yn],则并集长度len(x)<=len(x1)+len(x2);
(b14)、依次计算x1和x2的集合x中的y1、y2、......、ym、yn在x1中每一个词的相似度(值为0到1之间),并将所有结果中的最大值称为yi在x1中的语义分数,用zi表示;x中每个分词的语义分数组成的一个向量称为x1基于x的语义向量,表示为w1=[z1,z2,...,zn],对于x中的每一个词yi,如果yi在x1中出现,则在语义向量w1中将yi的语义分数zi设为1;如果x1中不包含yi,则计算yi在x1中的语义分数zi=n(n为预先设定的阈值,无阈值设为0,本文中阈值为0.2);
(b15)、语义向量计算语义相似度的计算公式如下:
所述步骤(b3)中还包括下列步骤:
步骤(b31)、把步骤(b1)中和步骤(b2)中得到的多种地图的相似度值通过一个排列组合,全部排列起来;
步骤(b32)、把排列起来的相似度值通过加法运算,即全部相加;
步骤(b33)、把加起来的相似度值用一个门限m来控制。
所述步骤(b4)中还包括下列步骤:
(b41)、若加法后的相似度值小于门限m,则不相似,匹配结束,多个地理信息文本不相同;
(b42)、如果加法后的相似度值大于门限m或在门限m附近,认为相似或不确定,则进行多个地理信息点经纬度距离之间的匹配。
实施例2:如图1所示,下面进一步详细说明本发明的基于多元化地理信息点的融合方法。
所述基于两种地图的地理信息点的融合方法的具体步骤如下:
步骤s1,信息提取及预处理,是在不同地理参考坐标系的地图中,首先进行地图坐标的变换,再找到某个相同区域的地理信息点,然后将提取到的地理信息按照地理名称、经纬度坐标等不同类别进行分类;
步骤s2,地理信息中的地理名称首先定义相似度,包括分词后的相似度处理、命名实体识别后的相似度处理、排列组合和加法运算四个步骤,根据计算两个相似度值得出的结果情况来判断,如果不相似,则匹配结束,多个地理信息点的地理名称不相同;如果相似或不确定,则进行多个地理信息点经纬度距离之间的匹配;
步骤s3,经纬度信息处理,通过计算两个地理信息点之间的经纬度距离来判断,如果两个地理信息点之间的距离差值大于门限δ=100m,则这两个地理信息点不匹配;如果两个地理信息点之间的距离差值小于门限δ=100m,则这两个地理信息点匹配。
步骤s4,相似度结果情况展示,根据得出的最终结果情况,在所选择的两个地图上用不同的颜色展现出来,来判定是否为同一地理信息点;如果最终结果是匹配,则在两个地图上用红色标记出来;如果最终结果是不匹配,则在两个地图上用蓝色标记出来。
具体地,所述步骤s1中,选择的两个地图是百度地图和高德地图,在两个地图中找到两个相同的邻近区域的地理信息点,包括下列步骤:
打开百度首页,点击地图,然后在百度地图的右上角,点击“地图api”,在api的页面,把鼠标移动到菜单项“工具”,在下拉菜单中选择“坐标拾取工具”,接着在搜索栏输入想要找到的某个区域“大理洱海”,然后“百度一下”,就会在地图上出现相应的标记,点击要抓取的某一个点,就能看到相应的坐标,再点击坐标右边的“复制”按钮就完成了第一个抓取地理信息点的工作;
打开高度地图,在右上角工具栏中选择标记,然后找到在百度地图中与之相同的区域“大理洱海”,定位后选择分享获取链接地址,接着在新建窗口中打开此地址,就能获取第二个经纬度信息了;
所述步骤s1中,将提取到的信息按照地理名称、经纬度坐标等不同类别进行分类,是通过建立excel表,地理名称类放一竖列,经纬度坐标类放一竖列,不同地理参考坐标系的地图名称放一行。
具体地,所述地理名称的相似度处理,如图2所示,包括下列四个步骤:
步骤s21,根据文本分词后的结果计算得到一个相似度值(介于0-1之间);
其中,文本分词使用的是ikanalyzer一个开源的,基于java语言开发的轻量级的中文分词工具包;以开源项目luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。
本发明实施例中,计算句子相似度,包括下列步骤:
(1)给定一个句子x1:大理祥和旅馆,经过汉语分词系统分词后,得到的所有词yi构成句子x1的向量表示。分词后的向量表示x1=[大,理,祥,和,旅,馆];给定句子x2:大理祥和客栈,同理,分词后的向量表示x2=[大,理,祥,和,客栈];
(2)x1中词的个数是x1的向量长度,用len(x1)=6表示;同理,x2的向量长度表示为len(x2)=5;
(3)将x1、x2中所有的所有词yi进行合并,对于重复出现的词只保留一个,由此得到两个向量之和,称为x1、x2的并集,表示x=x1ux2=[大,理,祥,和,旅,馆,客栈],则并集长度len(x)=7<=len(x1)+len(x2)=11;
(4)依次计算x1和x2的集合x中的大、理、祥、和、旅、馆、客栈,在x1:大理祥和旅馆中每一个词的相似度(值为0到1之间),并将所有结果中的最大值称为yi在x1中的语义分数,用zi表示。x中每个分词的语义分数组成的一个向量称为x1基于x的语义向量,表示为w1=[1,1,1,1,1,1,0.2];(对于x中的每一个词yi,如果yi在x1中出现,则在语义向量w1中将yi的语义分数zi设为1;如果x1中不包含yi,则计算yi在x1中的语义分数zi=n,n为预先设定的阈值,无阈值设为0,本文中阈值为0.2);同理,x2基于x的语义向量,表示为w1=[1,1,1,1,0.2,0.2,1]。
(5)语义向量计算语义相似度的计算公式如下:
由公式计算得出,大理祥和旅馆和大理祥和客栈的语义相似度是0.8304385591050395。
步骤s22,根据文本命名实体识别后的结果计算得到另一个相似度值(介于0-1之间);
其中,文本命名实体识别使用的是hanlp自然语言处理包开源。
本发明实施例中,计算句子相似度,包括下列步骤:
(1)给定句子x1:大理祥和旅馆,经过文本命名实体识别后,得到的所有词yi构成句子x1的向量表示。命名实体识别后的向量表示x1=[大理,祥和,旅馆];给定句子x2:大理祥和客栈,同理,命名实体识别后的向量表示x2=[大理,祥和,客栈];
(2)x1中词的个数是x1的向量长度,用len(x1)=3表示;同理,x2的向量长度表示为len(x2)=3;
(3)将x1、x2中所有的所有词yi进行合并,对于重复出现的词只保留一个,由此得到两个向量之和,称为x1、x2的并集,表示x=x1ux2=[大理,祥和,旅馆,客栈],则并集长度len(x)=4<=len(x1)+len(x2)=6;
(4)依次计算x1和x2的集合x中的大理、祥和、旅馆、客栈,在x1:大理祥和旅馆中每一个词的相似度(值为0到1之间),并将所有结果中的最大值称为yi在x1中的语义分数,用zi表示。x中每个分词的语义分数组成的一个向量称为x1基于x的语义向量,表示为w1=[1,1,1,0.2];(对于x中的每一个词yi,如果yi在x1中出现,则在语义向量w1中将yi的语义分数zi设为1;如果x1中不包含yi,则计算yi在x1中的语义分数zi=n,n为预先设定的阈值,无阈值设为0,本文中阈值为0.2);同理,x2基于x的语义向量,表示为w1=[1,1,0.2,1]。
(5)语义向量计算语义相似度的计算公式如下:
由公式计算得出,大理祥和旅馆和大理祥和客栈的语义相似度是0.7894736842105263。
步骤s23,通过排列组合和加法运算来得出最终的结果情况,把s21和s22中得到的两个地图的相似度值通过一个排列组合,全部排列起来,然后把排列起来的相似度值通过加法运算,即两者相加得0.8304385591050395+0.7894736842105263=1.61991223,把加起来的相似度值用一个门限m来控制;
步骤s24,判断多个地理信息点的地理名称是否相似,如果加法后的相似度值小于门限m=1,则不相似,匹配结束,两个地理信息点的地理名称不相同;如果加法后的相似度值大于门限m=1或在门限m=1附近,认为相似或不确定,则进行两个地理信息点经纬度距离之间的匹配。由步骤s23加法后的相似度1.61991223得出,1.61991223>1,所以进行两个地理信息点经纬度距离之间的匹配。
具体地,所述步骤s3中,计算两个地理信息点之间的经纬度距离,是通过下列公式来计算的(计算的结果单位为米):
wgs84_a=6378137.0为赤道上到地球中心的地球半径距离,单位为米;
d=d×π÷180为角度转化成弧度,其中,d为角度;
rade1=rad(e1);
rade2=rad(e2);
a=rade1–rade2为两点纬度之差;
b=rad(n1)-rad(n2)为两点经度之差;
s=s1×wgs84_a
其中,e1表示a点纬度,n1表示a点经度,e2表示b点纬度,n2表示b点经度。
由计算得出,大理祥和旅馆和大理祥和客栈的经纬度距离小于门限δ=100m,所以,得出这两个地理信息点匹配;并在百度地图和谷歌地图中,用红色标记这两个点。
相应地,一种基于多元化地理信息点的融合方法,如图3所示,包括信息提取及预处理模块1、地理名称的相似度处理模块2、经纬度信息处理模块3和相似度处理结果展示模块4,信息提取及预处理模块1包括至少两条信息,经纬度信息处理模块2包括至少两条经纬度信息,其特征在于,其中:
所述信息提取及预处理模块1,用于在不同地理参考坐标系的地图中,首先进行地图坐标的变换,再找到某个相同区域的地理信息点,然后将提取到的地理信息按照地理名称、经纬度坐标等不同类别进行分类;
所述地理名称的相似度处理模块2,用于根据分词后的相似度处理、命名实体识别后的相似度处理,来进行排列组合和最后的加法运算,然后根据计算两个相似度值得出的结果情况来判断,如果不相似,则匹配结束,多个地理信息点的地理名称不相同;如果相似或不确定,则进行多个地理信息点经纬度距离之间的匹配。
所述经纬度信息处理模块3,用于通过计算多个地理信息点两两之间的经纬度距离来判断,如果两两之间的距离差值大于某一个门限δ,说明这几个地理信息点不匹配;如果两两之间的距离差值小于某一个门限δ,则这几个地理信息点匹配。
所述相似度结果情况展示模块4,根据得出的最终结果情况,在不同的地图上用不同的颜色展现出来,来判定是否为同一地理信息点。
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!