主客观融合的软件非功能需求评价方法与流程
本发明属于软件
技术领域:
,涉及一种主客观融合的软件非功能需求评价方法。
背景技术:
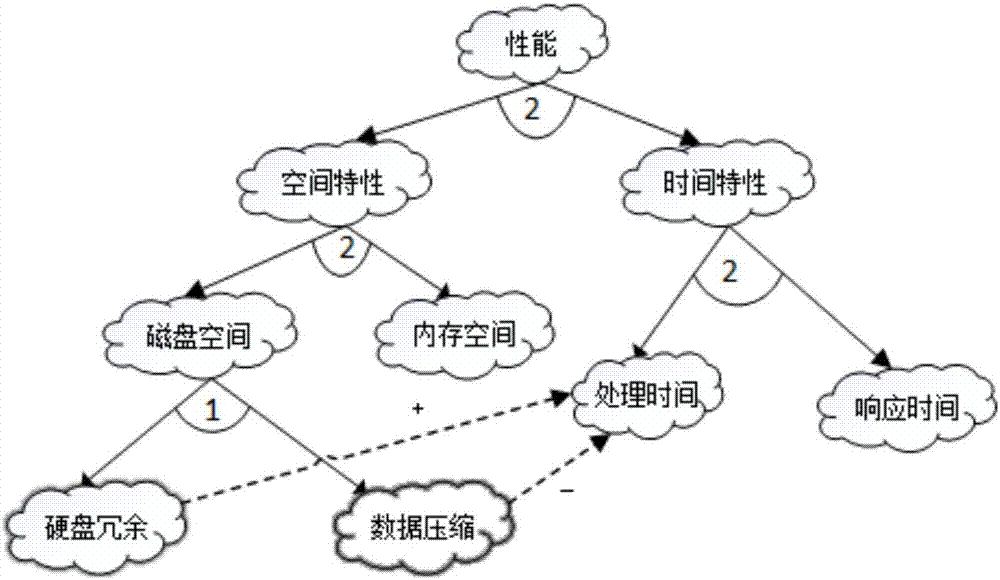
:近年来,软件非功能需求的相关研究已成为需求工程中一块很重要的研究领域和学术热点,但是目前软件需求的大部分方法都是针对功能需求的,对于非功能需求的描述和评价缺乏有效的方法。在许多软件尤其是大型软件中,软件非功能需求甚至是强制性需求,如电信软件中的性能和可靠性、电子商务软件中的安全性等。charette指出,“真正的现实系统中,在决定系统的成败或关键的因素中,满足非功能需求比满足功能需求更为重要”。自从boehm等人开创了面向产品的方法和chung等人开创了面向过程的方法以来,对软件非功能属性的研究取得了重要进展。随着软件需求正由简单转向为复杂、软件的规模由中小规模转向为大型以及软件开发环境由传统、封闭、静态拓展为开放、动态、多变,对软件非功能需求的理论研究也由宏观角度转向微观角度,从而更好地分析问题、解决问题。zhu等人引入领域工程中foda模型中的特征概念到需求工程中qsig图中,提出了一种fq-qsig模型来处理大型软件中非功能需求间复杂的相关关系和权衡问题,为决策者提供一个优化的选择结果。wen等人提出了emimce模型来评价可信软件的非功能需求。uzunov等人提出了一个分解分布式软件结构系统的三层次框架,为基于互补分析过程的新设计水平的非功能需求的测定奠定了基础。文杏梓等人提出了可信软件非功能需求指标体系,并基于设计结构矩阵、矩阵变换及运算,形成基于非功能需求相互关系的邻接矩阵和可达矩阵,提出非功能需求贡献值的概念,建立了一个客观的软件非功能需求度量模型。罗新星等人提出了一种基于关键非功能需求的软件可信性度量模型。软件非功能需求的重要性以及实现非功能需求的困难已经为学术界和产业界所公认。实现的困难在本质上来源于软件非功能需求所固有的主观性、全局性、相对性以及软件非功能需求之间的相关关系。目前对非功能需求的定量评价研究,无论是从面向过程、面向方面还是面向产品的角度几乎都是单一地从主观或客观方面进行的。从整体上来说,非功能需求具有主观性,由于不具有明确的判定标准,使得对非功能需求的判定往往根据人的主观感受来决定,这必将会导致不同的人有着不同的观点和看法。如“性能”这一概念,不同的人会用不同的视角来对其进行解释和评判;再比如,“用户界面友好、使用方便”,界定“友好”和“方便”的准则也会因人而异。然而在某些具体的子需求中,可以通过客观的方式对其进行评判,如“性能”下“时间特性”的子需求“响应时间”和“处理时间”就可以通过具体的数值来反映和评价其优劣,此时专家的主观评价一般来说就不如实际数值能更切实地反映其优劣程度。另外,在非功能需求评价中,现有研究大多使用了三角模糊数或者梯形模糊数等模糊集理论,在一定程度上反映了非功能需求评价中的模糊性和不确定性。然而,由于模糊集仅包含隶属信息,所以不能全面地描述和刻画人们对事物认知的不确定程度;而且没有一种清晰的途径或方法去分配一个元素到一个集合的隶属度。在确定非功能需求属性的权重时,目前大多采用的是主观赋权法,对专家权重的考虑不足。基于此,本文对chung等人提出的sig图进行改进,提出了一个esig图模型,以图形化的方式描述和表示非功能需求,在esig图模型的基础上,提出了主客观融合的软件非功能需求评价方法。从主客观的角度将最底层非功能需求节点划分为主观属性节点和客观属性节点。对于能用实际数值表示和反映的属性节点划分为客观属性节点,根据实际数值得出评分值;对于具有模糊性、不确定性、无法或者很难使用实际数值得出评分值的属性节点,划分为主观节点,通过专家主观打分的方式得到评分值。对于能用具体数值表示和反映但无法确定其评分标准而不能得出评分值的属性节点,由专家根据实际数值辅助得出评分值。如已确定“响应时间”属性节点的数值是0.02ms,但无法确切地知道此数值所反映的优劣情况,那么专家就可以通过该数值给出一个评分值,或者由专家事先给定一个评分值对照表来确定其评分值。本文扩展了基础的犹豫模糊集理论,将自然语言的评价融合到了犹豫模糊集中,提出了一种基于犹豫模糊语言信息偏好关系的属性权重确定方法。其中,专家的权重采用熵权法确定,熵权法是一种主观赋权法。该属性权重确定方法属于一种主客观综合赋权法,体现了主客观融合的思想,能够很好地表示非功能需求属性的不确定性和相对重要性,同时很好地反映了各专家对属性偏好程度的差异。在对属性优劣的评判过程中,本文使用了盲数理论的知识,盲数理论能够充分地反映客观信息和决策者个人认知水平的模糊性、灰性、随机性以及不确定性。技术实现要素:为实现上述目的,本发明提供一种主客观融合的软件非功能需求评价方法,从根本上提高了评价的合理性与可信性。本发明所采用的技术方案是,主客观融合的软件非功能需求评价方法,按照以下步骤进行:步骤1,主客观属性节点的划分,将建立的非功能需求esig图中的最底层节点中由专家直接评分的节点分类为主观属性节点,其余节点划分为客观属性节点;步骤2,确定专家的权重向量和属性权重向量,由专家给出的犹豫模糊偏好关系构造犹豫模糊偏好关系矩阵,并根据专家权重向量确定算法和属性权重向量确定算法分别确定专家的权重向量和属性权重向量;步骤3,确定最底层属性节点的评分矩阵,专家对主观属性节点进行打分,对于客观属性节点的评分根据具体的数据确定,最后根据专家意见的不确定性量化算法得出最底层属性节点的评分矩阵;步骤4,计算最底层属性节点对应的上层属性节点的未确知测度值;步骤5,确定属性节点的最终评分值,将属性节点的未确知测度与对应的属性节点的权重进行合成便可得出该属性节点的最终得分,自底向上逐层求解便可得出系统的非功能需求属性评分值。进一步的,所述步骤1中,非功能需求esig图的建立方法为:1)为明确表示分解路径和方向,将原sig图符号中表示分解的线段加上有向标识,用实线箭头表示,方向从父节点指向子节点;2)为表示节点间的促进或者冲突关系,使用虚线箭头加“+”号和“-”号的方式分别表示“促进”和“抑制”影响,方向从影响节点指向被影响节点;3)使用“单弧加数字”的方式表示父子节点的分解关系,单弧内的数字表示为了满足父节点而需要的子节点的个数。进一步的,所述步骤2中,专家权重向量确定算法具体为:1)采用ahfa算子,将专家dk给出的属性集ai中的所有犹豫模糊偏好值合成为整体犹豫模糊偏好值2)根据犹豫模糊数的得分函数,计算得到整体犹豫模糊偏好值的得分表示专家dk对属性集ai中属性ai偏好程度的得分值;3)计算专家dk的得分水平向量ei,ei=(ei1,ei2,…,eim)其中,eij表示向量(ei1,ei2,…,eim)中任意一个元素,eim是向量ei中的一个元素,表示所有专家对属性ai得分值的算术平均值,表示所有专家对属性ai得分值的最大值,ei反映了专家dk对属性集ai所做出的偏好程度的水平;4)计算熵值zi其中,不确定性程度用熵值表示,熵值越小,专家评分水平越高,可信度越高;反之,熵值越大,可信度越低,zij无具体含义,仅为计算熵值,e是自然对数的底;5)计算专家权重ωi,并确定专家权重向量ω:ω=(ω1,ω2,…,ωs)其中,且满足0<ωi<1,zi的含义是熵值。进一步的,所述步骤2中,属性权重向量确定算法具体为:11)设p为算法的迭代次数,δ为步长,且满足0≤ξ=pδ≤1,τ为群体共识性水平,令分别得到各专家给出的犹豫模糊偏好关系的完美积极一致性犹豫模糊偏好关系12)采用ahfwa算子将所有的个体完美积极一致性犹豫模糊偏好关系合成为总体犹豫模糊偏好关系即(i,j=1,2,…,m)其中,为中第t小的元素,ωk为专家dk的权重;13)判断所有的个体完美积极一致性犹豫模糊偏好关系是否达到可接受的一致性程度;计算各专家的个体完美积极一致性犹豫模糊偏好关系到总体犹豫模糊偏好关系的距离,即若对所有k=1,2,…,s,τ为群体共识性水平;说明是可接受的,则转步骤15);否则转步骤14);14)修正非一致性犹豫模糊偏好关系,令其中,式中,和分别为和中第t小的元素,令p=p+1,转步骤12);15)令采用ahfa算子,将属性集ai的所有犹豫模糊偏好关系值hij(j=1,2,…,m)合成为整体犹豫模糊偏好值hi;16)根据犹豫模糊数的得分函数,得到整体犹豫模糊偏好值hi的得分wi,用wi来表示属性集ai中属性ai的权重,可得属性权重向量w=(w1,w2,…,wm),进行归一化处理,得w′=(w′1,w′2,…,w′m),且满足0<w′i<1,进一步的,所述步骤3中,专家意见的不确定性量化算法具体为:21)计算得到专家组d1,d2,…,ds的专家综合可信度分别为α1,α2,…,αs;22)对存在交叉现象的区间进行无交叉划分,重新建立区间序列并计算新区间的可信度,得到属性ai落在给定的标准评分区间的可能性,具体为将区间序列的端点值由小到大排列得到新的无交叉区间序列为[ki1,ki1],[ki2,ki2],…,[kil,kil],按照比例分配法计算新区间的可信度ηi1,ηi2,…,ηil,将结果用盲数fi(x)表示,一般形式为23)根据盲数fi(x)计算属性ai落在给定的标准评分区间的可能性,得到新的盲数fi′(x),一般形式为得到属性集ai的盲数矩阵:其中l为给定的标准区间个数,m为由专家打分确定评分值的属性个数。本发明的有益效果是提出的主客观融合的非功能需求评价算法更加符合软件非功能需求是由多数定性属性和一定定量属性组成的这一实际情况,从根本上提高了评价的合理性与可信性;提出的主客观融合的专家赋权算法更好地反映了专家评价结果的可信度问题,间接地提高了评价的可信性和有效性;提出的属性权重方法更好地反映了属性的模糊性、不确定性和主观性等;将非功能需求间的分解关系和相关关系作为整体来考虑,避免了无法定量地权衡系统整体优劣的问题,大大地提高了评价的有效性。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1是将“性能”作为父节点进行处理的sig图。图2是将“性能”作为父节点进行处理的esig图。图3是评价算法流程图。图4是部分非功能需求的esig图。具体实施方式下面将融合本发明实施例中,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。1.esig图模型建立:chung等人提出了非功能需求(non-functionalrequirements,nfrs)计划。非功能需求框架(nfr框架)是一种面向过程的方法,主要目标是对非功能需求进行表示、组织和分析。sig图是就非功能表示和描述采用的一套图形化的表示方法,能够简单直观的表示非功能需求,常用来表示品质属性和框架决策。如图1所示,sig图中将一个父节点分解为一组子节点,主要利用了两种分解关系:“and/or”(用单弧和双弧来表示)。非功能需求的依赖关系一方面是指相互协同促进关系,另一方面是指非功能需求中存在的冲突。sig图中存在四种依赖关系:强正相关(++),正相关(+),强负相关(--)和负相关(-)。如图1中的“磁盘冗余”对“处理时间”产生“正相关”的促进影响。sig图对nfr分解的关系描述上仅限于and/or的关系,随着分解的进行不足以表达nfr分解过程中的复杂关系;没有分解路径表示符号;随着nfr的分解,子目标数量增加,会形成大量的sig图,不能自由的对目标进行拆分。针对sig图存在的不足,对现有的sig图符号系统进行以下修改和补充,得到非功能需求的esig图模型:(1)为明确表示分解路径和方向,将原sig中表示分解的线段加上有向标识,用实线箭头表示,方向从父节点指向子节点;(2)为表示节点间的促进或者冲突关系,使用虚线箭头加“+”号和“-”号的方式分别表示“促进”和“抑制”影响,方向从影响节点指向被影响节点;(3)使用“单弧加数字”的方式表示父子节点的分解关系。单弧内的数字表示为了满足父节点而需要的子节点的个数。如图2所示,图2中“磁盘空间”节点被分解为“磁盘冗余”和“数据压缩”两个节点,单弧内的数字“1”表示只需要实现其中一个子节点就能满足“磁盘空间”这个父节点。“磁盘压缩”和“数据压缩”对“处理时间”分别有“促进”和“抑制”影响。其中,“硬盘冗余”、“数据压缩”和“响应时间”等需求的优劣可以通过具体的数值来得到表示其优劣程度的评分值,即可以使用客观的方式进行评价。esig图简单直观地描述了非功能需求间的关系,为后续的定量评价奠定了基础。2.主客观融合的非功能需求评价算法针对具体的软件非功能需求建立esig图模型后,首先将图模型中的最底层节点划分为主观属性节点和客观属性节点;然后,专家根据esig图给出对各属性节点的犹豫模糊偏好关系,从而确定专家的权重向量与属性的权重向量;接着,专家对最底层主观属性节点评分,最底层客观属性节点根据实际数值得出评分值;最后,计算最底层节点对应的上层属性节点的未确知测度,进而可确定对应的上层属性节点的评价得分与等级。依据同样的方法,可确定其它上层属性节点的未确知测度,自底向上逐层进行,进而可确定该软件非功能需求的最终评价得分与等级。整个评价算法的流程如图3所示。犹豫模糊集作为模糊集的一种推广形式,允许元素到某个集合的隶属度用[0,1]中多个可能的取值来表示,这使人们能够更好地表达对不同目标的偏好的犹豫度。可见,犹豫模糊集能够更加细致合理地描述软件非功能需求属性的不确定性。定义1,犹豫模糊集设非空集合x={x1,x2,…,xm},则从x到[0,1]的一个子集的函数称为犹豫模糊集,记作:ha(x)={<x,ha(x)>|x∈x}(1)其中:ha(x)为区间[0,1]中几个可能的数的集合,表示x∈x属于集合a的可能的程度。为便于讨论,称ha(x)为犹豫模糊元。定义2,犹豫模糊偏好关系方案集{a1,a2,…,am}上的犹豫模糊偏好关系h为一个矩阵,h=(hij)m×m,其中,为犹豫模糊数,表示方案ai对aj的所有可能的偏好程度,而且其需要满足的条件为am表示第m个方案集,hij表示矩阵h中第i行第j列元素,i,j=1,2,…,m,表示hij中值的个数,表示犹豫模糊数hij中的第s个元素。在实际评价中,专家使用自然语言而不是绝对的数值来表达对属性的偏好程度是更为简单易行、更为合理的方式。因此,本文给出了0.1~0.9标度犹豫模糊偏好关系的定义(见定义3),将自然语言分别对应于0.1~0.9标度(表1)来表示专家对属性的偏好程度。表10.1~0.9标度定义3,0.1~0.9标度犹豫模糊偏好关系属性集a={a1,a2,…,am}上的犹豫模糊偏好关系g为一个矩阵,g=(gij)m×m,其中,gij为犹豫模糊数,表示评价指标ai对aj用0.1~0.9标度表示的所有的偏好程度,ai表示第i个属性;且满足:假设,对于属性ai和aj某专家“至少强烈偏好”于ai,则此时用自然语言表示的偏好关系为hij={强烈偏好,非常强烈偏好,极端偏好},即hij={p2,p3,p4}。对应的0.1~0.9标度犹豫模糊偏好关系hij={0.7,0.8,0.9}。设ai={a1,a2,…,am}为esig图中某非功能需求属性节点分解的子节点及对其存在“促进”和“抑制”影响的节点组成的属性集。设专家集d={d1,d2,…,ds},专家集中除了不同领域的专家外,还应当包括需求分析师、软件设计师、程序员和用户等整个软件生命周期中的主要参与者。设为专家dk给出的犹豫模糊语言偏好关系对应的0.1~0.9标度犹豫模糊偏好关系。k在dk中表示共s个专家中的第k个专家,h(k)表示第k个专家给出的犹豫模糊语言偏好关系对应的0.1~0.9标度犹豫模糊偏好关系。2.1专家权重向量确定算法当有多位专家参与评价时,由于各专家自身知识背景和偏好不同,对评价问题的熟悉程度也不同,因此,对评价结果的影响程度是不同的。在以往的评价过程中,大多是直接给出专家的权重,或者采用简单的算术平均来综合各专家的意见,不能较好地反映各专家评价水平的差异,可能会对评价结果造成较大偏差。本文在犹豫模糊偏好关系的基础上引入熵权法来确定专家的权重,很好地反映了专家对非功能需求属性偏好的差异。定义4,ahfwa算子设hj(j=1,2,…,n)为一列犹豫模糊数,调整的犹豫模糊加权算术平均(adjustedhesitantfuzzyweightedaveraging,ahfwa)算子为映射hn→h,即其中,为hj中第t小的值;ω=(ω1,ω2,…,ωn)t为hj(j=1,2,…,n)的权重向量,且ωj∈[0,1],特别地,当ω=(1/n,1/n,…,1/n)t时,则ahfwa算子退化为调整的犹豫模糊算术平均(adjustedhesitantfuzzyaveraging,ahfa)算子,即其中,为hj中第t小的值。定义5,犹豫模糊元的得分函数设h(x)为定义在x∈x上的一个犹豫模糊元,则称为犹豫模糊元h(x)的得分函数,其中lh表示犹豫模糊元h(x)中元素的个数。算法1,专家权重向量确定算法step1,采用ahfa算子,即根据式(5)将专家dk给出的属性集ai中的所有犹豫模糊偏好值合成为整体犹豫模糊偏好值step2,根据犹豫模糊数的得分函数,即根据式(6)计算得到整体犹豫模糊偏好值的得分表示专家dk对属性集ai中属性ai偏好程度的得分值。step3,计算专家dk的得分水平向量ei。ei=(ei1,ei2,…,eim)(7)其中,eij表示向量(ei1,ei2,…,eim)中任意一个元素,eim是向量ei中的一个元素,表示所有专家对属性ai得分值的算术平均值,表示所有专家对属性ai得分值的最大值。ei反映了专家dk对属性集ai所做出的偏好程度的水平。step4,计算熵值zi。其中,不确定性程度用熵值表示,熵值越小,专家评分水平越高,可信度越高;反之,熵值越大,可信度越低。zij没有具体含义,仅为计算熵值。e是自然对数的底。step5,计算专家权重ωi,并确定专家权重向量ω。ω=(ω1,ω2,…,ωs)(9)其中,且满足0<ωi<1,zi的含义是熵值。2.2属性权重向量确定算法在实际评价中,如果试图通过分配给不同待评价属性一些绝对数值作为评价意见,将会导致同一个评价者在评价过程中由于难于区分数值间差异而造成评价意见的不稳定性,同时,会大大增加专家的工作量。因此使用自然语言进行评价是一个更合理的方式。由于不同的决策者具有不同价值体系和考量,从而群体间的不一致是不可避免的。这就需要群体达成共识,群体共识是指群体中多数成员同意而少数不同意的成员认为他们有合理的可能性来施加影响的决策。群体共识是解决群体决策问题的必由之路,因为它能够确保最终得到的解被群体中的所有人所支持。本文提出的属性权重向量确定算法不仅是一种主客观综合赋权法,同时是一种自动的群体共识达成算法。因为该算法能自动地达成群体共识,不需要专家之间频繁地沟通与交流,可以为专家节省大量的时间,使用起来方便快捷。定义6,完美积极一致性犹豫模糊偏好关系设h=(hij)m×m为一个犹豫模糊偏好关系,则称为h=(hij)m×m对应的完美积极一致性犹豫模糊偏好关系,此处为便于表示,设c=(1-a)(1-b),则其中,和分别为hik(x)和hkj(x)中第t小的元素,t=1,2,…,l;算法2,属性权重向量确定算法step1.设p为算法的迭代次数,δ为步长,且满足0≤ξ=pδ≤1,τ为群体共识性水平。令根据式(10)分别得到各专家给出的犹豫模糊偏好关系的完美积极一致性犹豫模糊偏好关系step2.采用ahfwa算子将所有的个体完美积极一致性犹豫模糊偏好关系合成为总体犹豫模糊偏好关系即其中,为中第t小的元素,ωk为专家dk的权重。step3.判断所有的个体完美积极一致性犹豫模糊偏好关系是否达到可接受的一致性程度。具体为:计算各专家的个体完美积极一致性犹豫模糊偏好关系到总体犹豫模糊偏好关系的距离,即若(对所有k=1,2,…,s;τ为群体共识性水平)说明是可接受的,则转step5;否则转step4。step4.修正非一致性犹豫模糊偏好关系。具体为:令其中,式中,和分别为和中第t小的元素。令p=p+1,转step2。step5.令采用ahfa算子,即根据式(5)将属性集ai的所有犹豫模糊偏好关系值hij(j=1,2,…,m)合成为整体犹豫模糊偏好值hi。step6.根据犹豫模糊数的得分函数,即根据式(6)计算得到整体犹豫模糊偏好值hi的得分wi。用wi来表示属性集ai中属性ai的权重。可得属性权重向量w=(w1,w2,…,wm),进行归一化处理,得w′=(w′1,w′2,…,w′m)(14)且满足0<w′i<1,2.3专家意见的不确定性量化算法定义7,盲数概念设g(i)为一系列的灰区间ai(此处含义与上文定义不同)构成的区间型灰数集合,则ai∈g(i),若i=1,2,…,n,f(x)为定义在g(i)上的灰函数,且若ai≠aj,且则称函数f(x)为一个盲数。称αi为f(x)的ai值的可信度,称α为f(x)的总可信度,称n为f(x)的阶数。由于专家的认知行为具有主观性和不确定性,在实际评价过程中,专家对属性优劣作出的评分值往往不是一个确定的点值,而最有可能是落在该点值附近且具有某一可信度的区间里。由于盲数是区间分布的可信度函数,因此用它来表达专家对属性优劣程度的判断是十分合理的。在运用盲数理论进行评价时,为了使决策结果更准确,引入“专家可信度”的概念。专家可信度即专家的可信任程度,体现了专家在该领域中的权威性。一般地说,专家可信度可用表示,值越大,表示专家可信度越高。这样,最值得人们信任的专家可信度为最不值得人们相信的专家可信度为设一组专家d1,d2,…,ds的可信度分别为令为专家di关于专家组d1,d2,…,ds的综合可信度,简称为专家di的综合可信度。设一组专家d1,d2,…,ds对属性ai给出的打分区间序列分别为[xi1,yi1],[xi2,yi2],…,[xis,yis],专家可信度为可根据算法2对专家意见的不确定性进行量化。算法3,专家意见的不确定性量化算法step1,根据式(16)计算得到专家组d1,d2,…,ds的专家综合可信度分别为α1,α2,…,αs。step2,对存在交叉现象的区间进行无交叉划分,重新建立区间序列并计算新区间的可信度,得到属性ai落在给定的标准评分区间的可能性。具体为:将区间序列的端点值由小到大排列得到新的无交叉区间序列为[ki1,ki1],[ki2,ki2],…,[kil,kil],按照比例分配法计算新区间的可信度ηi1,ηi2,…,ηil。将结果用盲数fi(x)表示,一般形式为step3,根据盲数fi(x)计算属性ai落在给定的标准评分区间的可能性,得到新的盲数fi′(x),一般形式为得到属性集ai的盲数矩阵其中l为给定的标准区间个数,m为由专家打分确定评分值的属性的个数。本文解决了以下问题:1.软件非功能需求是由多数定性的属性和少数定量属性组成的,而现有评价方法大多仅从客观或者主观单方面进行评价,为此,本文提出了一种主客观融合的评价方法;2.在对非功能需求的评价时,评价者的知识领域、个人偏好及对系统的熟悉程度等的不同使得其评价结果具有不同的可信度,故应当为专家设置权重。在现有文献的评价方法中或是直接由笔者给出专家权重,或是对专家主观赋权,或是对专家客观赋权,都不能较好地体现专家的权重问题,为此,本文提出了一种主客观融合的专家赋权算法;3.非功能需求评价中,不同的属性具有不同的权重,现有的评价方法虽然大多都考虑到了属性的模糊性、主观性和不确定性,使用了三角模糊数、梯形模糊数及灰色理论的来解决这一问题,然而这些方法仅表达了隶属情况,不能表达非隶属度和决策者的犹豫度,为此,本文提出了一种基于模糊偏好关系的属性权重确定方法;4.非功能需求属性间存在分解关系和相关关系,现有文献中提到的评价方法基本都是将分解关系与相关关系分开考虑,在综合这两种关系后可能无法定量地权衡系统整体优劣的问题,降低了评价结果的有效性和可信性。换句话说,如果将非功能需求间的分解关系和相关关系分开来考虑就无法定量地判断出应该选择哪个属性节点了,无法得知选择哪个节点对某属性总体来说是更好的。为此,在本文提出的评价方法中将非功能需求间的这两种关系作为一个整体来考虑。本文中所给出的esig图示例只是整个非功能需求很小的一部分,在实际的非功能需求中,需求的分解关系和相关关系是更为复杂的。提出的hfpr非功能需求模糊综合评价算法将非功能需求的分解关系和相关关系集成在一起考虑,能有效地判断属性的综合优劣。实例分析:以某“机票网上订购系统”的非功能需求为例建立esig图模型并进行评价,从而说明所提出的评价算法的合理性与有效性。由于非功能需求的分类没有统一的标准,所以不同的人建立的esig图模型也会有所不同。对“机票网上订购系统”的部分非功能需求建立的eisg图模型如图4所示。如图4所示,“s0”节点表示需要最终评价的系统非功能需求,“s3-5”表示图中第3层(根节点为第0层)从左往右数的第5个节点。为便于计算说明,本文仅以“时间”(s2-9节点)属性为例给出评价算法的整个过程。“时间”节点分解为“响应时间”和“处理时间”两个子节点,并且需同时实现这两个节点才能满足“时间”节点,“rsa加密”和“des加密”对“时间”存在“抑制”影响。对这4个节点按需要主观或客观评分进行划分,由于“rsa加密”和“des加密”对“时间”的抑制影响很难从它们的实际数值反映出来,故采用专家打分的方式给出评分值。因“响应时间”和“处理时间”可以通过时间数值的大小很好地反映其优劣,故使用客观的方式获得评分值。同理,对其它最底层节点进行划分。构造犹豫模糊偏好关系构建由3个专家组成的专家集d={d1,d2,d3},专家对s3-5,s3-6,s3-12,s3-13这4个属性进行两两比较后,用表1中表示偏好的自然语言表达了他们对这4个属性的偏好程度,构造的0.1~0.9标度犹豫模糊偏好关系分别为矩阵h1、h2和h3。确定专家的权重向量根据算法1确定专家的权重向量,求解过程如下。step1.根据式(5)将3个专家给出的所有犹豫模糊偏好值合成为整体犹豫模糊偏好值计算得到专家d1给出的所有犹豫模糊偏好值合成的整体犹豫模糊偏好值为同理可求得其他值。step2.根据犹豫模糊数的得分函数,即根据式(6)计算得到整体犹豫模糊偏好值的得分值计算得step3.根据式(7)计算专家dk的得分水平向量ei。计算得e1=(0.957,0.993,0.995,0.953)e2=(0.980,0.985,0.976,0.970)e3=(0.977,0.991,0.981,0.983)step4.根据式(8)计算熵值zi。计算得z1=0.099,z2=0.088,z3=0.066。step5.计算专家权重ωi,并确定专家权重向量ω。计算得ω=(0.275,0.31,0.415)。确定属性权重向量根据算法2确定属性权重向量,求解过程如下。step1.令(h(k))(p)=h(k)(k=1,2,3),p=1,根据式(10)分别得到各专家给出的犹豫模糊偏好关系对应的完美积极一致性犹豫模糊偏好关系计算得step2.根据下式:将所有的个体完美积极一致性犹豫模糊偏好关系合成为总体犹豫模糊偏好关系其中上式为现有技术属性权重向量确定算法中,采用ahfwa算子将所有的个体完美积极一致性犹豫模糊偏好关系合成为总体犹豫模糊偏好关系其中,为中第t小的元素,ωk为专家dk的权重。计算得step3.判断所有的个体完美积极一致性犹豫模糊偏好关系是否达到可接受的一致性程度。根据式(12)计算距离得不失一般性,令共识性水平τ=0.1。可知,此时和都大于0.1,因此需要修正这些个体犹豫模糊偏好关系,转step4。step4.修正非一致性犹豫模糊偏好关系。令ξ=0.7,根据式(13)分别构造新的个体犹豫模糊偏好关系令p=2,返回step2,最后可计算得到新的距离此时,所有的转step5。step5.令根据式(5)将所有犹豫模糊偏好关系值hij(j=1,2,3,4)合成为整体犹豫模糊偏好值hi。计算得h1={0.315,0.458,0.545},h2={0.485,0.537,0.694},h3={0.444,0.519,0.633},h4={0.391,0.503,0.597}。step6.根据式(6)计算得到整体犹豫模糊偏好值hi的得分wi,wi表示属性ai的权重。计算得w=(0.439,0.572,0.532,0.495),对w进行归一化得w′=(0.215,0.281,0.261,0.243)。确定节点的评分值矩阵将节点的得分区间定义为[-100,0]和[0,100]。对其它节点存在“抑制”影响的节点使用区间[-100,0]的给出评分值,将此区间细分为[-100,-75]、(-75,-50]、(-50,-25]和(-25,0]4个标准评分等级区间,节点的“抑制”影响越大,得分值越小。其他节点使用区间[0,100]给出评分值,同样地,将区间细分为[0,25]、(25,50]、(50,75]和(75,100]4个标准评分等级区间。打分可以跨区间进行,为便于计算,设区间的端点值为5的整数倍,评分区间为一个闭区间。专家们对客观属性节点“响应时间”和“处理时间”给出的评分区间对照表如表2所示。表2“响应时间”和“处理时间”的评分区间对照表时间取值(单位:s)对应得分区间(-∞,10-7][75,100][10-7,10-5][50,75][10-5,10-3][25,50][10-3,+∞)[0,25]需求文档中指出,应满足在10000次测试中,“响应时间”落在时间区间(-∞,10-7]在9000次左右,落在时间区间[10-7,10-5]在1000次左右;“处理时间”落在时间区间(-∞,10-7]在8000次左右,落在时间区间[10-7,10-5]在2000次左右。所以得到“响应时间”和“处理时间”的评分值落在各等级区间的可能性函数分别为专家d1,d2,d3的可信度分别为专家对主观属性节点s3-5和s3-6给出的打分结果如表3所示。表3专家评分属性节点专家d1专家d2专家d3s3-5[-30,-20][-50,-40][-40,-20]s3-6[-35,-5][-55,-10][-25,-10]根据算法3对专家意见的不确定性进行量化,求解过程如下。step1.根据式(16)计算得到专家d1,d2,d3的专家综合可信度分别为α1,α2,α3。求得α1=0.308,α2=0.327,α3=0.365step2.对表3中存在交叉现象的区间进行无交叉划分,重新建立区间序列并计算新区间的可信度,得到的f1(x)为step3.计算属性落在给定的标准评分区间的可能性,计算得得到属性节点s3-5和s3-6评分值的盲数矩阵所以,这4个属性落在各评分等级区间的可能性函数fi′(x)组成的评分值盲数矩阵为计算未确知测度并确定得分将评分值盲数矩阵与对应的权重向量进行合成便可得到未确知测度值。由图4可知实现节点“s3-5rsa加密”或“s3-6des加密”其中之一便可实现“s2-9安全性”节点。如果选择“s3-5”节点,将属性权重重新归一化为同时将评分值盲数矩阵调整为此时,“s2-9”节点的未确知测度计算得如果选择“s3-6”节点,计算得到“s2-9”节点的未确知测度设分值向量μ=(-100,-75,-50,-25,25,50,75,100),将分值向量与未确知测度相乘即为最终得分。分别选择节点“s3-5”和“s3-6”,求得的上层节点“时间”属性的最终得分分别为同理,可求得“s2-10”节点的未确知测度为x2-10=(0,0,0,0,0,0,0.182,0.818)。如果选择节点“s3-6”,可得节点“s2-9”和“s2-10”落在各评分等级区间的可能性函数fi′(x)组成的评分值盲数矩阵为求得节点“s2-9”和“s2-10”的属性权重向量w1-4=(0.452,0.548)。进一步计算得到节点“s1-4”的未确知测度进而计算得到节点“s1-4”,即“性能”属性的最终得分同理,可求得其它属性节点的未确知测度,自底向上逐层计算,即可求得系统非功能需求的最终得分。结果分析说明从计算得到的“时间”属性的得分可知,选择节点“s3-5”时,“时间”属性的评分值更高,因此从对“时间”属性的影响来看,选择“rsa加密”是更为理想的。然而,对于整个系统的非功能需求来讲,选择“rsa加密”并不一定是较优的。因为该属性还是“安全性”属性的分解节点,对其有贡献作用,从而影响整个系统的非功能需求的优劣。同时,本文中所给出的esig图示例只是整个非功能需求很小的一部分,在实际的非功能需求中,需求的分解关系和相互影响关系是更为复杂的。从整个非功能需求的优劣来看,只有分别选择待选属性后重新计算,然后根据系统的得分才能更为全面地判断如何选择属性。同时,也可以根据具体需要从局部来考量做出权衡,灵活性好。现有技术中将需求间的分解关系和相关关系分开来考虑,在权衡时可能会出现无法确定优劣的问题。比如,假设“rsa加密”对“安全性”的贡献大于“des加密”,而“rsa加密”对“时间”的抑制影响也大于“des加密”。现有技术的方法就无法定量地判断出应该选择哪个属性节点了,因为无法得知这两个节点对“时间”的贡献及抑制影响的综合情况。而且现有研究中的方法大多仅仅从促进抑制影响的个数来考虑需求间的相关关系,不能切实地反映影响的程度。文本算法将非功能需求的分解关系和相关关系集成在一起考虑,能有效地判断属性的综合优劣,体现了算法在非功能需求评价问题中的先进性。以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1