基于集成学习的SAR目标鉴别方法与流程
本发明属于雷达
技术领域:
,特别涉及一种sar目标鉴别方法,可用于对车辆目标识别与分类提供重要信息。
背景技术:
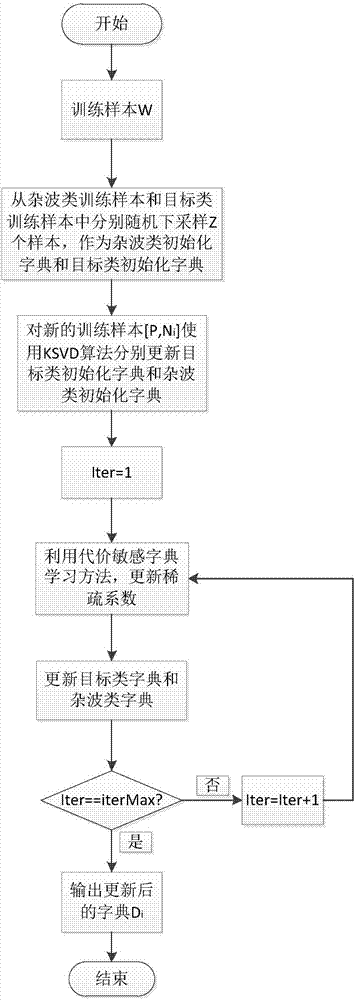
:合成孔径雷达sar利用微波遥感技术,不受气候和昼夜影响,具有全天候、全天时的工作能力,并具有多频段、多极化、视角可变和穿透性等特点。随着越来越多的机载和星载sar的出现,带来大量不同场景下的sar数据,对sar数据一个重要的应用就是自动目标识别atr,复杂场景下的目标鉴别也成为目前研究方向之一。sar目标鉴别是指从训练数据集中学习得到的一个分类器,这个分类器可以用于预测未知样本的类别标号。现有文献中已提出了很多的sar目标鉴别方法,比如:基于纹理、形状、对比度等传统特征的二次距离鉴别方法、基于梯度直方图特征的svm鉴别方法、基于词袋模型特征的svm鉴别方法等等。这些传统的sar目标鉴别方法在sar训练数据集类别分布相对平衡时性能较好,但是当sar训练数据集类别分布不平衡时性能较差。又因为在实验中sar训练数据集中目标样本数远少于杂波样本数,传统方法的目标检测率较低,而在sar目标鉴别过程中通常更加关注目标的检测率,即在实际应用中倾向于将目标分对,尽量降低目标的漏检率。然而传统的sar目标鉴别方法并不适用于训练数据类别不平衡这种情况下的sar目标鉴别。上述的传统的分类方法在不平衡的sar数据集上其分类效果存在以下不足:1.由于传统分类方法基本都是以训练数据总体分类精度最大为分类准则,当训练样本类别分布不平衡时,目标类数据在训练数据集中占很小的比例,分类器通常是倾向于将目标类判定为杂波类,因此对目标类样本的检测率较低,从而导致sar目标鉴别的性能较差。2.由于在sar目标鉴别过程中,通常更加关注目标类的准确率,当训练样本类别分布不平衡时,传统的分类方法训练所得的分类器会对杂波类样本产生很高的检测率,但是对目标类样本的检测率却很低,由于面对不平衡数据集的sar目标鉴别时,不仅要维持杂波类原有的分类精度,更要大大提高目标类的分类精度,因此现有的这些传统sar目标鉴别方法并不能满足这个要求。技术实现要素:本发明的目的在于针对已有sar目标鉴别方法的不足,提出一种基于集成学习的sar目标鉴别方法,以提高在训练数据类别不平衡时的目标鉴别性能。为实现上述目的,本发明的技术方案包括如下:(1)对给定的训练切片和测试切片分别提取词包模型特征,得到训练切片的词包模型特征和测试切片的词包模型特征其中,表示目标类训练切片,表示杂波类训练切片,表示目标类测试切片,表示杂波类测试切片,是目标类训练切片的词包模型特征,是杂波类训练切片的词包模型特征,是目标类测试切片的词包模型特征,是杂波类测试切片的词包模型特征,p1表示目标类训练切片数目,p2表示杂波类训练切片数目,k1表示目标类测试切片数目,k2表示杂波类测试切片数目,h表示词包模型特征的维数。(2)利用(1)中所得的训练切片的词包模型特征w训练n个代价敏感的字典,得到训练后的字典d1,...,di...,dn,i=1,...,n:2a)从训练样本中的杂波类样本随机下采样n个子集{n1,...,ni,...,nn},每个子集中的样本个数与训练样本中目标样本个数p1相同;2b)当前循环次数为i′,i′=1,...,n′,n′为学习字典的最大循环次数,其值与随机下采样的子集个数n相同;选择集合{n1,...,ni,...,nn}中第i=i′个子集ni,与目标类训练样本一起再构成新的训练样本ti=[p,ni];2c)利用新的训练样本ti=[p,ni]进行代价敏感的字典学习,得到第i个字典di;2d)将当前循环次数i′与最大循环次数n′进行比较,若i′≤n′,则令i′=i′+1,返回到2b),若i′>n′,则停止循环,得到所有字典d1,...,di...,dn;(3)利用(1)中所得的训练切片的词包模型特征w训练m个支持向量机svm,得到训练后的模型m1,...,mj...,mm,j=1,...,m;(4)利用(2)得到所有的字典d1,...,di...,dn和(3)中得到所有的模型m1,...,mj...,mm对测试样本v进行分类,得到测试样本的分类决策值(5)根据(4)中测试样本的分类决策值利用最大投票法进行分类,即将第k个样本的分类决策值ek与分类阈值t=(n+m)/2进行比较:如果ek≥t,则第k个测试样本为目标类,否则为杂波类。本发明为复杂场景下sar训练数据集类别不平衡时的车辆目标鉴别方法,相比于传统的sar目标鉴别方法,本发明在训练分类器时针对训练数据中目标类样本数目少于杂波类样本数目而导致分类器的分类结果倾向于杂波类的问题,采用集成学习方法,集成了基于代价敏感字典的稀疏表达分类器和支持向量机svm分类器,用集成后的分类器对测试样本进行测试,提升了复杂场景下sar训练数据集类别不平衡时的车辆目标鉴别性能。附图说明图1是本发明的实现流程图;图2是本发明中的代价敏感字典学习的子流程图;图3是本发明实验1使用的一组切片图像;图4是本发明实验2使用的一组切片图像;图5是本发明实验3使用的一组切片图像;图6是本发明实验4使用的一组切片图像;具体实施方式下面结合附图对本发明的实施例和效果作进一步详细说明:参见图1,本发明的实现步骤包括如下:步骤1,对给定的训练切片图像和测试切片图像提取词包模型特征。1a)从给定的minisar切片数据集中,得到训练切片图像和测试切片图像其中,表示目标类训练切片,表示杂波类训练切片,表示目标类测试切片,表示杂波类测试切片,p1表示目标类训练切片图像数目,p2表示杂波类训练切片图像数目,k1表示目标类测试切片图像数目,k2表示杂波类测试切片图像数目;1b)利用sar-sift局部特征描述符对训练切片图像i进行局部特征提取,得到训练切片图像的局部特征其中,是目标类训练切片图像的局部特征,是杂波类训练切片图像的局部特征;1c)利用sar-sift局部特征描述符对测试切片图像j进行局部特征提取,得到测试切片图像的局部特征其中,是目标类测试切片图像的局部特征,是杂波类测试练切片图像的局部特征;1d)对训练样本的局部特征x利用kmeans算法得到编码字典d;1e)利用编码字典d对训练样本的局部特征x进行特征编码,得到训练样本的局部特征编码系数其中,目标类训练切片图像的局部特征编码系数,是杂波类训练切片图像的局部特征编码系数,1f)对训练样本的局部特征编码系数a进行特征合并,得到训练样本的词包模型特征:其中,是目标类训练切片的词包模型特征,是杂波类训练切片的词包模型特征,h表示词包模型特征的维数;1g)利用编码字典d对测试样本的局部特征y进行特征编码,得到测试样本的局部特征编码系数其中,为目标类测试切片图像的局部特征编码系数,为杂波类测试切片图像的局部特征编码系数;1h)对测试样本局部特征编码系数b进行特征合并,得到测试样本的词包模型特征:其中,是目标类测试切片的词包模型特征,是杂波类测试切片的词包模型特征;步骤2,根据步骤1中的训练样本的词包模型特征w训练n个代价敏感的字典,得到训练后的字典。2a)从训练样本中的杂波类样本中随机下采样n个子集,得到集合{n1,...,ni,...,nn},每个子集中的样本个数与训练样本中目标样本个数p1相同;2b)设当前循环次数为i′,i′=1,...,n′,n′为学习字典的最大循环次数,其值与随机下采样的子集个数n相同;选择集合{n1,...,ni,...,nn}中第i=i′个子集ni,与目标类训练样本一起再构成新的训练样本ti=[p,ni];2c)利用新的训练样本ti=[p,ni]进行代价敏感的字典学习,得到第i个字典di;参见图2,本步骤的具体实现如下:2c1)从原始的目标类训练样本和杂波类训练样本中分别随机下采样z个样本,得到目标类初始化字典和杂波类初始化字典2c2)利用目标类训练样本p,使用ksvd算法对目标类字典进行更新,得到更新后的目标类字典为利用杂波类训练样本ni,使用ksvd算法对杂波类字典进行更新,得到更新后的杂波类字典为并令2c3)令iter=1为当前迭代次数,itermax为最大迭代次数;2c4)由新的训练样本ti和字典di,利用下面的优化模型求解稀疏系数λi:其中:λ1和λ2是正则化参数,||·||f表示f范数,||·||1表示1范数,||·||2表示2范数,⊙表示点乘,表示字典di的第h列原子,q表示代价惩罚矩阵;其中,表示将类别为的样本错判成类别为的代价,表示样本ts的类别,表示原子dr的类别,δ(·)是一个离散脉冲函数,即σ≥2表示代价常数;2c5)利用2c4)中的稀疏系数λi,通过求解下面的优化公式,更新字典di:通过拉格朗日乘子法求解上述优化公式,得到更新后的第h列原子:其中,表示稀疏系数λi中的第h行,(·)t表示转置操作,表示稀疏系数λi中的第l行,表示字典di中的第l列原子;2c6)根据2c5)中得到的更新后的字典原子得到更新后的字典:2c7)令将当前迭代次数iter与最大迭代次数itermax进行比较,若iter≥itermax,则令iter=iter+1,返回步骤2c4),否则,输出字典di;2d)将当前循环次数i′与最大循环次数n′进行比较,若i′≤n′,则令i′=i′+1,返回到2b),若i′>n′,则停止循环,得到所有字典d1,...,di...,dn,i=1,...,n。步骤3,根据步骤1中的训练样本的词包模型特征w训练m个支持向量机svm,得到训练后的模型。3a)从训练样本中的杂波类样本中随机下采样m个子集,得到集合{f1,...,fj...,fm,}每个子集中的样本个数与训练样本中目标样本个数p1相同;3b)设训练svm的当前循环次数为:j′=1,...,m′,m′为训练svm的最大循环次数,其值与随机下采样的子集个数m相同;从集合{f1,...,fj...,fm}中选择第j=j′个子集fj,并将其与目标类训练样本一起构成新的训练样本uj=[p,fj];3c)利用训练样本uj=[p,fj]训练一个支持向量机svm,得到第j个训练后的模型mj;3d)将当前循环次数j′与最大循环次数m′进行比较:若j′≤m′,则令j′=j′+1,返回到3b),若j′>m′,则停止循环,得到所有训练后的模型m1,...,mj...,mm,j=1,...m。步骤4,利用步骤2中得到的所有字典d1,...,di...,dn和步骤3中得到的所有模型m1,...,mj...,mm,对测试样本v进行分类。4a)利用步骤2中得到的字典d1,...,di...,dn对测试样本v进行稀疏表达分类;4a1)设循环次数为i′=1,...,n′,n′为最大循环次数,其值与字典个数一样;4a2)利用第i=i′个字典di对测试样本v进行稀疏表达分类:若第k个测试样本预测为目标类,则令字典di对第k个测试样本的分类结果若第k个测试样本预测为杂波类,则令字典di对第k个测试样本的分类结果4a3)根据4a2)中字典di对第k个测试样本的分类结果得到第i个字典di对所有测试样本v的分类结果4a4)将当前循环次数i′与最大循环次数n′进行比较,若i′≥n′,则令i′=i′+1,返回到4a2),否则,得到所有字典d1,...,di...,dn对测试样本v的分类结果:4b)利用步骤3中得到的训练后模型m1,...,mj...,mm对测试样本v进行支持向量机svm分类;4b1)设循环次数为j′=1,...,m′,m′为最大循环次数,其值与模型个数一样;4b2)利用第j=j′个模型mj对测试样本v进行支持向量机svm分类:若第k个测试样本预测为目标类,则令模型mj对第k个测试样本的分类结果若第k个测试样本预测为杂波类,则令模型mj对第k个测试样本的分类结果4b3)根据4b2)中模型mj对第k个测试样本的分类结果得到第j个模型mj对测试样本v的分类结果4b4)将当前循环次数j′与最大循环次数m′进行比较:若j′≥m′,则令j′=j′+1,返回到4b2),否则,得到训练后所有模型m1,...,mj...,mm对测试样本v的分类结果:4c)根据4a)中的字典d1,...,di...,dn对测试样本v分类结果和4b)中的训练后模型m1,...,mj...,mm对测试样本v的分类结果,得到第k个测试样本的分类决策值为:4d)根据4c)中第k个测试样本的分类决策值ek,得到所有测试样本v的分类决策值步骤5,根据步骤4中测试样本的分类决策值利用最大投票法进行分类,即将第k个样本的分类决策值ek与分类阈值t=(n+m)/2进行比较:如果ek≥t,则第k个测试样本为目标类,否则为杂波类。本发明的效果可通过以下实验数据进一步说明:实验1:(1)实验场景:本实验所用的测试切片图像来自于美国sandia实验室公开的minisar数据集中的图像minisar20050519p0006image004,所用的训练切片图像来自于美国sandia实验室公开的minisar数据集中的图像minisar20050519p0002image005、图像minisar20050519p0003image003和图像minisar20050519p0005image003,这些数据下载自sandia实验室的网站,切片图像示例如图3所示,其中图3(a)是目标类训练切片图像示例,图3(b)是杂波类训练切片图像示例,图3(c)是测试切片图像示例。(2)实验参数:取训练目标切片数p1=353,训练杂波切片数p2=1442,测试目标切片数k1=140,测试杂波切片数k2=599;从杂波类训练样本随机下采样8个子集,取正则化参数λ1=λ2=0.01,代价常数σ=2,目标样本类错分成杂波类样本的代价ctc=5,杂波类样本错分成目标类样本的代价cct=1,目标类字典原子数目和杂波类原子数目z=300,字典更新迭代最大次数itermax=5,svm分类器采用libsvm工具包,选择高斯核的svm分类器,设核参数g=10,惩罚系数c=10;(3)实验内容:(3.1)用现有的基于支持向量机svm的方法与本发明方法对训练样本类别分布非平衡下的sar数据进行对比实验;(3.2)用现有的基于稀疏表达分类src的方法与本发明方法对训练样本类别分布非平衡下的sar数据进行对比实验;(3.3)用现有的基于ksvd的稀疏表达分类ksvd-src的方法与本发明方法对训练样本类别分布非平衡下的sar数据进行对比实验;(3.4)用现有的基于代价敏感字典学习csdl的方法与本发明方法对训练样本类别分布非平衡下的sar数据进行对比实验。实验1的对比结果如表1所示,表1中的auc表示roc曲线下的面积,pc表示总体精度,pd表示检测率,pf表示虚警率。表1不同方法的对比结果不同方法aucpcpdpfsvm0.94510.89170.50000.0167src0.76170.79570.28570.0851ksvd-src0.92990.88090.63570.0618csdl0.96330.92020.83570.0601本发明0.97370.92500.86360.0606从表1中可见,本发明的auc和目标检测率pd最高,并且在检测率有较大幅度上升的同时虚警率上升幅度较小,说明在训练样本类别分布非平衡时,本发明的鉴别性能比现有的方法更好。实验2:(1)实验场景:本实验所用的测试切片图像来自于美国sandia实验室公开的minisar数据集中的图像minisar20050519p0002image005,所用的训练切片图像来自于美国sandia实验室公开的minisar数据集中的图像minisar20050519p0006image004、图像minisar20050519p0003image003和图像minisar20050519p0005image003,这些数据下载自sandia实验室的网站,切片图像示例如图4所示,其中图4(a)是目标类训练切片图像示例,图4(b)是杂波类训练切片图像示例,图4(c)是测试切片图像示例。(2)实验参数:取训练目标切片数p1=414,训练杂波切片数p2=1531,测试目标切片数k1=79,测试杂波切片数k2=510;从杂波类训练样本随机下采样8个子集;取正则化参数λ1=λ2=0.01,代价常数σ=2,目标样本类错分成杂波类样本的代价ctc=5,杂波类样本错分成目标类样本的代价cct=1,目标类字典原子数目和杂波类原子数目z=300,字典更新迭代最大次数itermax=5,svm分类器采用libsvm工具包,选择高斯核的svm分类器,取核参数g=10,惩罚系数c=10;(3)试验内容:同实验1相同。实验2的对比结果如表2所示:表2不同方法的对比结果不同方法aucpcpdpfsvm0.88200.89640.40510.0275src0.70970.73850.40510.2098ksvd-src0.87800.82510.42040.1137csdl0.90590.88460.54330.0627本发明0.94820.90270.81390.0835从表2中可见,本发明的auc和目标检测率pd最高,并且在检测率有较大幅度上升的同时虚警率上升幅度较小,说明在训练样本类别分布非平衡时,本发明的鉴别性能比现有的方法更好。实验3:(1)实验场景:本实验所用的测试切片图像来自于美国sandia实验室公开的minisar数据集中的图像minisar20050519p0003image003,所用的训练切片图像来自于美国sandia实验室公开的minisar数据集中的图像minisar20050519p0006image004、图像minisar20050519p0005image003和图像minisar20050519p0002image005,这些数据下载自sandia实验室的网站,切片图像示例如图5所示,其中图5(a)是目标类训练切片图像示例,图5(b)是杂波类训练切片图像示例,图5(c)是测试切片图像示例。(2)实验参数:取训练目标切片数p1=334,训练杂波切片数p2=1414,测试目标切片数k1=159,测试杂波切片数k2=627;从杂波类训练样本随机下采样8个子集,取正则化参数λ1=λ2=0.01,代价常数σ=2,目标样本类错分成杂波类样本的代价ctc=5,杂波类样本错分成目标类样本的代价cct=1,目标类字典原子数目和杂波类原子数目z=300,字典更新迭代最大次数itermax=5,svm分类器采用libsvm工具包,选择高斯核的svm分类器,取核参数g=10,惩罚系数c=10;(3)实验内容:同实验1相同。实验3的对比结果如表3所示:表3不同方法的对比结果不同方法aucpcpdpfsvm0.83830.76910.76100.2281src0.50880.62470.28300.2887ksvd-src0.75850.72140.67920.2679csdl0.79440.69720.76730.3206本发明0.83890.63080.90250.4381从表3中可见,本发明的auc和目标检测率pd最高,并且在检测率有较大幅度上升的同时虚警率上升幅度较小,说明在训练样本类别分布非平衡时,本发明的鉴别性能比现有的方法更好。实验4:(1)实验场景:本实验所用的测试切片图像来自于美国sandia实验室公开的minisar数据集中的图像minisar20050519p0005image003,所用的训练切片图像来自于美国sandia实验室公开的minisar数据集中的图像minisar20050519p0006image004、图像minisar20050519p0003image003和图像minisar20050519p0002image005,这些数据下载自sandia实验室的网站,切片图像示例如图6所示,其中图6(a)是目标类训练切片图像示例,图6(b)是杂波类训练切片图像示例,图6(c)是测试切片图像示例。(2)实验参数:取训练目标切片数p1=378,训练杂波切片数p2=1736,测试目标切片数k1=115,测试杂波切片数k2=305;从杂波类训练样本随机下采样8个子集;取正则化参数λ1=λ2=0.01,代价常数σ=2,目标样本类错分成杂波类样本的代价ctc=5,杂波类样本错分成目标类样本的代价cct=1,目标类字典原子数目和杂波类原子数目z=300,字典更新迭代最大次数itermax=5,svm分类器采用libsvm工具包,选择高斯核的svm分类器,取核参数g=10,惩罚系数c=10;(3)实验内容:同实验1相同。实验4的对比结果如表4所示:表4不同方法的对比结果不同方法aucpcpdpfsvm0.90580.87380.65220.0426src0.68180.66670.15650.1410ksvd-src0.87330.84050.69570.1049csdl0.92470.86190.79130.1115本发明0.93150.84020.82260.1531从表4中可见,本发明的auc和目标检测率pd最高,并且在检测率有较大幅度上升的同时虚警率上升幅度较小,说明在训练样本类别分布非平衡时,本发明的鉴别性能比现有的方法更好。综上,本发明是基于集成学习的sar目标鉴别方法,解决了训练样本集类别分布非平衡下得sar的目标鉴别问题,有效的利用了高分辨sar图像丰富的细节信息以及不同类别的错分代价信息,并采用集成学习的方法进一步提升了复杂场景下的sar目标鉴别性能。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1