一种基于规则与词典的监狱犯人短信自动审核方法与流程
本发明涉及一种基于规则与词典的监狱犯人短信自动审核方法,属于短文本分析的技术领域。
背景技术:
随着科技的发展与信息时代的到来,人们每天接触的消息量越来越大,从消息中选取有用的信息就变得重要起来。这些消息中有不少的部分是以短文本的形式存在的,这就促进了短文本分析的产生与发展。短文本具有无语境、信息浓缩度高的特点,使得短文本分析的难度大大增加。
虽然短文本分析的发展迅速,但是对于监狱服刑人员短信的审核仍然缓慢,其中一个重要的原因就是用户数量少。如今的机器学习在各方面的应用都很多,也有对于监狱服刑人员短信审核的应用,如svm、rnn等。但由于监狱短信不通过率低,正负样本差距过大,使得机器学习的效果不尽人意。
现有技术中的垃圾短信拦截技术已经较为成熟,智能手机多都会自带垃圾短信拦截功能,一些手机软件如360手机卫士、来电通、安卓优化大师、手机管家等都有拦截垃圾短信的功能。垃圾短信拦截的方法一般基于词典与黑白名单实现,也可加入用户反馈机制,以更新词典及黑白名单。但是,垃圾短信拦截技术主要是针对广告的拦截,目的性单一,其词典一般都与广告相关,如果用于监狱短信审核,不能满足监狱要求的多样性,词典也需重构。
技术实现要素:
针对现有技术的不足,本发明提供一种基于规则与词典的监狱犯人短信自动审核方法。
发明概述:
本发明解决的问题主要是短文本的多分类问题,将依据监狱短信规定对短信审核的过程转换为对短信进行层层分类的过程,一旦分为规定中的一类,则短信被拦截;本发明解决的另一问题是,避免了由于狱警审核短信的工作量大,短信审核结果难以符合监狱规定的现象。本发明的技术方案为:
一种基于规则与词典的监狱犯人短信自动审核方法,包括步骤如下:
1)对短信内容进行预处理;
对短信内容进行中文分词;现有技术中中文分词的方法有多种,可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
2)利用短信审核规则对短信内容进行初步审核;所述短信审核规则包括:
2.1)重复短信:对同一监狱犯人在两天内发送或接收的内容重复的短信进行拦截;
2.2)无内容短信:对无短信内容的短信进行拦截;
2.3)外文限制:对包含外文的短信进行拦截;
2.4)数字限制:对于短信内数字数量过大的短信进行拦截;
2.5)钱财限制:对于涉及钱财数目过大的短信进行拦截;涉及钱财数目过大的判断方法为:a、利用正则表达式判断短信内涉及的钱财数目是否超过规定;b、判断中文分词后得到的词组是否包含有关钱财的字眼;如果规定钱财数量不得超过一千元,正则表达式包括@"\d{4}千元"、@"\d万元"等。所述短信审核规则根据监狱犯人收发短信的相关规定编写。
3)利用ngram判断短信是否通顺;
3.1)设短信s由词w1,w2,…,wn顺序排列组成,则短信s出现的概率
p(s)=p(w1w2…wn)=p(w1)p(w2|w1)...p(wn|w1w2...wn-1)(2.1);
式(2.1)中越往后的词的可能性越多,概率无法计算,假设每个词出现的概率只与前一个词有关,将问题进行简化;
3.2)简化式(2.1)得:p(s)=p(w1)p(w2|w1)...p(wn|wn-1)(2.2);
3.3)计算p(wi|wi-1),
其中,#(wi-1,wi)为语料库中wi-1和wi前后相邻出现的次数,#(wi-1)为语料库中wi单独出现的次数;所述的语料库是指由监狱提供的被监狱审核通过的短信组成的语料库;
3.4)将p(wi|wi-1)与阈值p对比,当p(wi|wi-1)≥p时,进入步骤4),否则,拦截短信;
判断一个句子是否合理,是否通顺,可以通过计算其出现的概率来判断;ngram模型就是依据上述方法来判断语句的生成概率的,我们用训练好的ngram来计算短信的生成概率,当概率小于阈值时,判定短信是不合理的,或者是不通顺的,对相应的短信进行拦截。
4)利用朴素贝叶斯模型对短信内容进行分类;
采用朴素贝叶斯分类的方式对短信内容进行审核;朴素贝叶斯并不直接判断短信是否通过,而是先对短信进行多分类,判断该短信内容所涉及的主题,如关心家人、索要物品、聊家常、抱怨或吵架等。一条短信可能有多个主题,若其中的某个主题违反监狱规定,则判为不通过,如此可大大减少正负样本数量差距过大造成的影响;
首先,对监狱提供的所有短信进行主题标签的人工标定,短信和与短信对应的主题标签共同构成朴素贝叶斯模型的先验样本m0;根据先验样本m0建立关键词典,对先验样本m0的所有短信进行中文分词后,将分得的词组按不同的主题存储在关键词典中;关键词典涵盖监狱犯人短信内容涉及的各个方面和监狱规定的所有方面(规则中已含的除外)。
计算关键词典中的词w为主题i的概率为pi(w),
pi(s)=1-(1-pi(w1))(1-pi(w2))...(1-pi(wn))+pi(w1)pi(w2)...pi(wn)(3.1)
则新的短信s不通过的概率为:
p(s)=σpi(s),i为禁止通过主题;(3.2)
当p(s)大于阈值w时,拦截该短信。
根据本发明优选的,阈值w以最大化f1值的方法确定。
进一步优选的,阈值w∈(0.25,0.4)。
根据本发明优选的,所述基于规则与词典的监狱犯人短信自动审核方法,还包括增量学习的步骤;
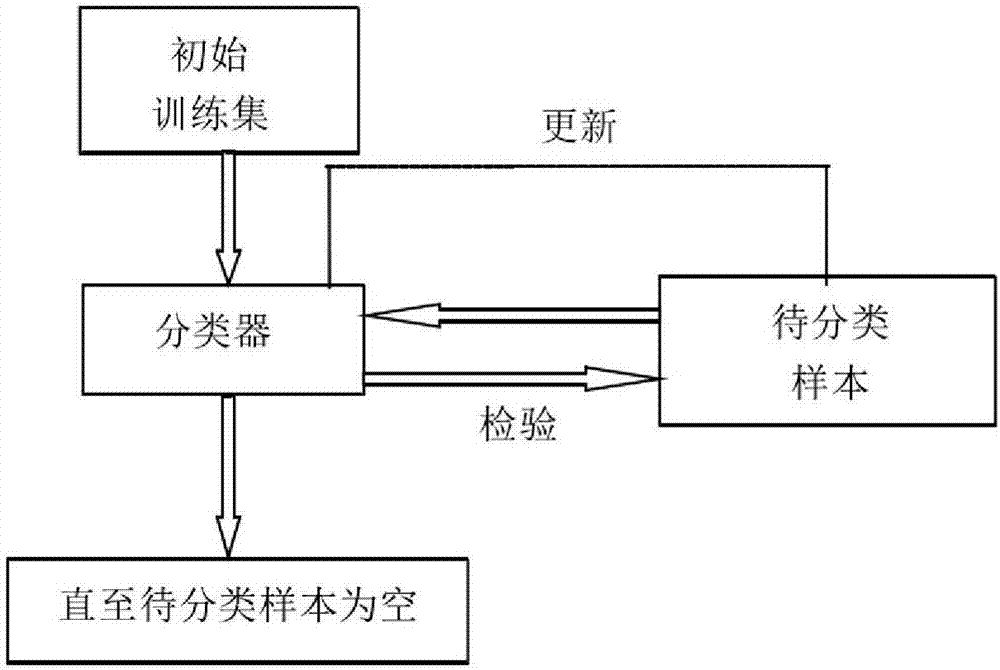
当新的样本加入时,原来的后验概率就成为先验概率,贝叶斯学习是利用新样本信息来修正老信息的连续动态过程。当后验信息与先验信息同分布时,可以利用后验信息作为进一步审核的先验信息。
设pi(w|i0)为关键词w所在短信为主题i的先验概率密度,其中i0为先验信息,即先验样本m0所含的信息,当新的短信s加入时,新的短信s所含信息为新增信息q,对应的后验概率密度为:
式(3.2)全面权衡了先验信息i0和新增信息q,即:
后验信息i1=先验信息i0+新增信息q;
将新的短信s及与其对应的主题标签加入先验样本m0中构成样本m1,m1即为朴素贝叶斯模型新的先验样本。
根据本发明优选的,所述步骤2.4)中判断数字数量过大的标准是,短信中数字的数量超过7个或数字个数占短信总字符个数的比例大于30%。
根据本发明优选的,对短信内容进行中文分词的步骤之前还包括去噪的步骤;对训练样本进行人工筛选;根据监狱相关规定,将训练样本中明显审核错误的短信的主题标签进行更改,人工重新判定短信是否拦截。由于监狱短信样本存在正负样本比例差距大、噪声大,样本中错误的数据多的问题,去噪成为必不可少的步骤。
根据本发明优选的,对短信内容进行中文分词之后,还包括更新停用词表并添加用户词典的步骤。根据中文分词结果及监狱规定,更新停用词表并添加用户词典(其中,“停用词表”和“用户词典”是中文分词方法中的常规概念),以此来减少无用的词汇和增加有意义的词汇,使用优化后的分词软件对短信进行分词,分词结果更优。
根据本发明优选的,所述步骤2.5)中关钱财的字眼包括,“元”、“美元”、“英镑”、“人民币”、“汇款”。
根据本发明优选的,p∈(10^-6.2l,10^-6.6l),其中,l为短信长度。
本发明的有益效果为:
1.本发明所述基于规则与词典的监狱犯人短信自动审核方法,根据监狱相关规定制定规则方法,根据犯人短信建立专用词典,对监狱短信有很强的针对性;对于不同的监狱规定使用不通过的审核方法,多方式的使用及增量学习的加入,提高了了审核的适应性;利用多分类的方式进行审核,降低了正负样本比例差距过大造成的负面影响;
2.本发明所述基于规则与词典的监狱犯人短信自动审核方法,通过朴素贝叶斯多分类间接审核短信,避免了使用机器学习直接将短信分为通过与不通过两类,而是先进行多分类,对于违反监狱规定的类型进行拦截,有效解决了正负样本比例差距大的问题,降低了噪声的影响。
附图说明
图1为本发明所述基于规则与词典的监狱犯人短信自动审核方法的流程图;
图2为本发明所述增量学习的方法流程图。
具体实施方式
下面结合实施例和说明书附图对本发明做进一步说明,但不限于此。
实施例1
如图1所示。
一种基于规则与词典的监狱犯人短信自动审核方法,包括步骤如下:
1)对短信内容进行预处理;
对短信内容进行中文分词;中文分词使用的方法为基于字符串匹配的分词方法。
2)利用短信审核规则对短信内容进行初步审核;所述短信审核规则包括:
2.1)重复短信:对同一监狱犯人在两天内发送或接收的内容重复的短信进行拦截;
2.2)无内容短信:对无短信内容的短信进行拦截;
2.3)外文限制:对包含外文的短信进行拦截;
2.4)数字限制:对于短信内数字数量过大的短信进行拦截;
2.5)钱财限制:对于涉及钱财数目过大的短信进行拦截;涉及钱财数目过大的判断方法为:a、利用正则表达式判断短信内涉及的钱财数目是否超过规定;规定钱财数量不得超过一千元,正则表达式包括@"\d{4}千元"、@"\d万元"。b、判断中文分词后得到的词组是否包含有关钱财的字眼;所述短信审核规则根据监狱犯人收发短信的相关规定编写。
3)利用ngram判断短信是否通顺;
3.1)设短信s由词w1,w2,...,wn顺序排列组成,则短信s出现的概率
p(s)=p(w1w2…wn)=p(w1)p(w2|w1)...p(wn|w1w2…wn-1)(2.1);
式(2.1)中越往后的词的可能性越多,概率无法计算,假设每个词出现的概率只与前一个词有关,将问题进行简化;
3.2)简化式(2.1)得:p(s)=p(w1)p(w2|w1)...p(wn|wn-1)(2.2);
3.3)计算p(wi|wi-1),
其中,#(wi-1,wi)为语料库中wi-1和wi前后相邻出现的次数,#(wi-1)为语料库中wi单独出现的次数;所述的语料库是指由监狱提供的被监狱审核通过的短信组成的语料库;
3.4)将p(wi|wi-1)与阈值p对比,当p(wi|wi-1)≥p时,进入步骤4),否则,拦截短信;p=10^(-6.5l),其中,l为短信长度;
判断一个句子是否合理,是否通顺,可以通过计算其出现的概率来判断;ngram模型就是依据上述方法来判断语句的生成概率的,我们用训练好的ngram来计算短信的生成概率,当概率小于阈值时,判定短信是不合理的,或者是不通顺的,对相应的短信进行拦截。
4)利用朴素贝叶斯模型对短信内容进行分类;
采用朴素贝叶斯分类的方式对短信内容进行审核;朴素贝叶斯并不直接判断短信是否通过,而是先对短信进行多分类,判断该短信内容所涉及的主题,如关心家人、索要物品、聊家常、抱怨或吵架等。一条短信可能有多个主题,若其中的某个主题违反监狱规定,则判为不通过,如此可大大减少正负样本数量差距过大造成的影响;
首先,对监狱提供的所有短信进行主题标签的人工标定,短信和与短信对应的主题标签共同构成朴素贝叶斯模型的先验样本m0;根据先验样本m0建立关键词典,对先验样本m0的所有短信进行中文分词后,将分得的词组按不同的主题存储在关键词典中;关键词典涵盖监狱犯人短信内容涉及的各个方面和监狱规定的所有方面(规则中已含的除外)。
计算关键词典中的词w为主题i的概率为pi(w),
pi(s)=1-(1-pi(w1))(1-pi(w2))...(1-pi(wn))+pi(w1)pi(w2)...pi(wn)(3.1)
则新的短信s不通过的概率为:
p(s)=σpi(s),i为禁止通过主题;(3.2)
当p(s)大于阈值w时,拦截该短信。
实施例2
如实施例1所述的基于规则与词典的监狱犯人短信自动审核方法,所不同的是,阈值w以最大化f1值的方法确定,w=0.32。
实施例3
如实施例1所述的基于规则与词典的监狱犯人短信自动审核方法,所不同的是,所述基于规则与词典的监狱犯人短信自动审核方法,还包括增量学习的步骤;
当新的样本加入时,原来的后验概率就成为先验概率,贝叶斯学习是利用新样本信息来修正老信息的连续动态过程,如图2所示。当后验信息与先验信息同分布时,可以利用后验信息作为进一步审核的先验信息。
设pi(w|i0)为关键词w所在短信为主题i的先验概率密度,其中i0为先验信息,即先验样本m0所含的信息,当新的短信s加入时,新的短信s所含信息为新增信息q,对应的后验概率密度为:
式(3.2)全面权衡了先验信息i0和新增信息q,即:
后验信息i1=先验信息i0+新增信息q;
将新的短信s及与其对应的主题标签加入先验样本m0中构成样本m1,m1即为朴素贝叶斯模型新的先验样本。
实施例4
如实施例1所述的基于规则与词典的监狱犯人短信自动审核方法,所不同的是,所述步骤2.4)中判断数字数量过大的标准是,短信中数字的数量超过7个。
实施例5
如实施例1所述的基于规则与词典的监狱犯人短信自动审核方法,所不同的是,对短信内容进行中文分词的步骤之前还包括去噪的步骤;对训练样本进行人工筛选;根据监狱相关规定,将训练样本中明显审核错误的短信的主题标签进行更改,人工重新判定短信是否拦截。由于监狱短信样本存在正负样本比例差距大、噪声大,样本中错误的数据多的问题,去噪成为必不可少的步骤。
实施例6
如实施例1所述的基于规则与词典的监狱犯人短信自动审核方法,所不同的是,对短信内容进行中文分词之后,还包括更新停用词表并添加用户词典的步骤。根据中文分词结果及监狱规定,更新停用词表并添加用户词典(其中,“停用词表”和“用户词典”是中文分词方法中的常规概念),以此来减少无用的词汇和增加有意义的词汇,使用优化后的分词软件对短信进行分词,分词结果更优。
实施例7
如实施例1所述的基于规则与词典的监狱犯人短信自动审核方法,所不同的是,所述步骤2.5)中关钱财的字眼包括,“元”、“美元”、“英镑”、“人民币”、“汇款”。
- 还没有人留言评论。精彩留言会获得点赞!