一种利用刻画因果依赖关系和时序影响机制增强答案质量排序的评判方法与流程
本发明涉及问答文本检索,尤其涉及一种利用刻画因果依赖关系和时序影响机制增强答案质量排序方法。
背景技术:
:问答检索是具有现实意义的重要
技术领域:
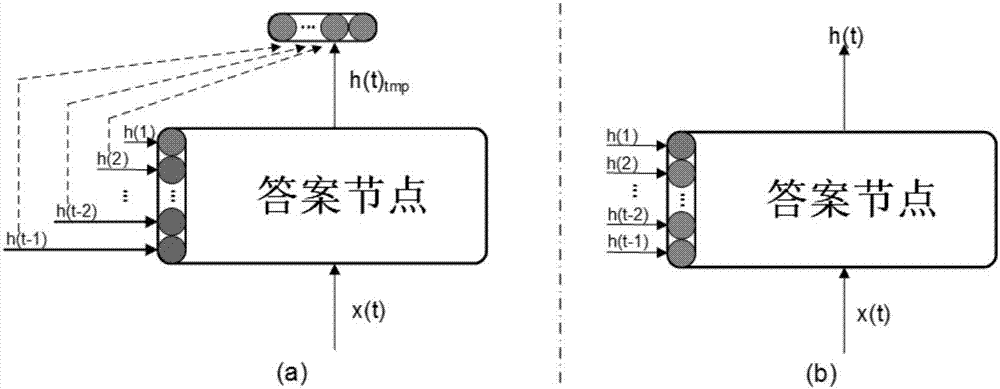
,而依据问答文本的语义关联性对其进行排序是这一领域中的一项重要技术。这项技术在检索过程中,对问题与其每一个候选答案的关联性高低进行排序,并将排序结果展现给用户,在答案质量排序应用中有巨大的价值。传统的答案质量排序方法,一般先为问答数据学习一个语义空间,再将问题与答案分别映射在该语义空间中,形成相应的特征向量。之后使用一个人工指定的关联性度量函数或者机器学习的方法计算问题和每一个候选答案间的关联性,最后再依照关联性高低对答案质量进行排序。这种方法将语义空间中的特征向量作为问答数据的表示,仅考虑问题答案之间的语义关联性(即本文中所说的“因果依赖关系”),而忽略了同一问题下候选答案之间的时序影响,因此难以挖掘答案之间原本存在的复杂影响机制。利用刻画因果依赖关系和时序影响机制增强答案质量排序方法能够有效弥补上述传统方法中的不足。本方法在传统的长短时记忆模型中引入了问答数据中常见的问题与答案之间的因果依赖关系以及答案与答案之间的时序影响机制。相比一般的答案质量评判方法,本发明不仅局限于问题和答案之间的语义关联度,还进一步发掘答案之间基于时序的相互影响,揭示高质量答案的形成规律。技术实现要素:本发明的目的在于解决现有技术中存在的问题,并提供一种利用刻画因果依赖关系和时序影响机制增强答案质量排序的评判方法。本发明所采用的具体技术方案如下:利用刻画因果依赖关系和时序影响机制增强答案质量排序的评判方法,包括如下步骤:1)构建排序用的问答训练数据集:将每个问题及其按照时间先后顺序排序的答案作为训练数据集;2)对训练样本进行分词操作并去除训练样本中的噪音,使用paragraph2vec模型对处理后的问答数据进行无监督学习,得到文本表达模型,并利用文本表达模型分别构建问题与答案在语义空间中的隐性表达;3)基于问题和答案在语义空间中的隐性表达,将问题与答案之间的因果依赖关系和答案与答案之间的时序影响机制引入长短时记忆模型进行学习,得到问答排序模型;4)使用学习后所得到的问答排序模型对新问题下的候选答案进行排序:基于问题和答案在语义空间中的隐性表达,使用问答排序模型对问题与每一个答案的关联性进行评分,根据关联性评分的高低对问题的候选答案进行分数排序,最后输出答案质量排序结果。上述步骤可具体采用如下实现方式:所述的步骤1)包括:1)对于任意问题qi∈q,i∈{1,2,…n},其中n为问题集q中问题的数量,从答案集a中得到其候选答案ai,1,ai,2,ai,3…ai,k分别对应的发布时间ti,1,ti,2,ti,3…ti,k,其中k为问题qi下候选答案的数量;2)按照时间先后顺序对ti,1,ti,2,ti,3…ti,k进行排序,得到时间序列t1,t2,t3…tk,同时根据时间ti,1,ti,2,ti,3…ti,k的先后顺序对答案进行排序,发表时间较早的答案排在靠前的位置;3)每个问题与其候选答案构成一个数据样本,表示为的多元组。所述的步骤2)包括:1)使用分词工具对所得到的问答数据进行分词处理,对分词结果中不同词{w1,w2,w3…wn}的出现频率{f1,f2,f3…fn}进行统计;2)针对统计结果,设定最高阈值fl与最低阈值fu,对于wi∈{w1,w2,w3…wn},如果fi<fl或者fi>fu,则从数据中删除单词wi;3)若wi为停止词,则从数据中删除单词wi;4)使用paragraph2vec对训练集中的所有问答数据进行无监督学习,得到问题和答案的特征表达向量,问题和答案分别被表示为vq∈rd和va∈rd,其中d为文本在语义特征空间的维数。所述的步骤3)包括:1)基于传统长短时记忆模型,使模型的结构单元接收当前时间节点t前所有时间节点的隐输出h(i),其中1≤i≤t-1;模型的结构单元再通过设置权重系数αi,将所接收的隐输出加权求和,得到新的向量m(t),其定义如下:其中αi∈[0,1]并且α1预先进行初始化,其他的αi进而初始化为(1-α1)/(t-2);m(t)将作为当前时间节点的隐输入,参与当前时间节点结构单元中各个门的计算;2)在模型训练过程中,模型在第一个时间节点读入一个训练样本中的问题向量vqi,将该节点作为问题节点,问题节点产生其对应的隐输出h(1);模型在之后的每一个时间节点都读入该训练样本中的一个答案向量这些节点作为答案节点,答案节点产生其对应的隐输出h(t),t≥2;对于每一个答案节点,其接收的信息来源分为以下三种:第一种为答案向量第二种为问题节点的隐输出h(1);第三种为当前答案节点之前的所有答案节点的隐输出h(2),h(3)…h(t-1);其中,模型通过接收隐输出h(1)保留问题与答案之间的因果依赖关系,接收隐输出h(2),h(3)…h(t-1)得到答案与答案之间的时序影响机制;3)模型训练过程中,α1保持初始值不变,对于其他的αi,在训练的过程中按照如下公式进行更新:其中h(t)tmp为当前答案节点在所有αi(2≤i≤t-1)更新前的隐输出;4)构建关联度匹配函数s(q,a):s(q,a)=σ(qtma)其中m为问题与答案的关联性度量矩阵,q为问题节点的隐输出,a为答案节点的隐输出,σ(·)为sigmoid函数;在关联度匹配函数基础上,定义损失函数l(t)如下:l(t)=max{0,γ-s(q,abest)+s(q,a′)}其中,abest为问题q的最佳答案,a′为其他的候选答案,γ为超参数;使用随机梯度下降算法求解损失函数,得到模型的参数,该优化等价于如下无约束优化问题:其中,θ为模型中所有参数,λ为正则项的超参数。所述的步骤4)包括:1)给定一个问题与该问题下按照时序发表的答案,将问题与答案按序读入模型;2)根据评分结构对答案进行排序,其结果即为答案质量排序结果。相比一般的答案质量评判方法,本发明进一步发掘答案与答案之间基于时序的相互影响,揭示高质量答案的形成规律。本发明在答案质量排序中所取得的性能较传统的基于文本和语义关联度的评判方法更好。附图说明图1是基于因果依赖关系和时序影响机制的长短时记忆模型的神经单元结构图;图2是基于因果依赖关系和时序影响机制的长短时记忆模型答案节点权重α更新示意图;图3是利用刻画因果依赖关系和时序影响机制增强答案质量排序方法示意图。具体实施方式下面结合附图和具体实施方式对本发明做进一步阐述和说明。如图3所示,利用刻画因果依赖关系和时序影响机制增强答案质量排序的评判方法,包括如下步骤:1)构建排序用的问答训练数据集:将每个问题及其按照时间先后顺序排序的答案作为训练数据集。具体通过如下子步骤实现:1.1)对于任意问题qi∈q,i∈{1,2,…n},其中n为问题集q中问题的数量,从答案集a中得到其候选答案ai,1,ai,2,ai,3…ai,k分别对应的发布时间ti,1,ti,2,ti,3…ti,k,其中k为问题qi下候选答案的数量;1.2)按照时间先后顺序对ti,1,ti,2,ti,3…ti,k进行排序,得到时间序列t1,t2,t3…tk,同时根据时间ti,1,ti,2,ti,3…ti,k的先后顺序对答案进行排序,发表时间较早的答案排在靠前的位置;1.3)每个问题与其候选答案构成一个数据样本,表示为的多元组。2)对训练样本进行分词操作并去除训练样本中的噪音,使用paragraph2vec模型对处理后的问答数据进行无监督学习,得到文本表达模型,并利用文本表达模型分别构建问题与答案在语义空间中的隐性表达。具体通过如下子步骤实现:2.1)使用分词工具对所得到的问答数据进行分词处理,对分词结果中不同词{w1,w2,w3…wn}的出现频率{f1,f2,f3…fn}进行统计;2.2)针对统计结果,设定最高阈值fl与最低阈值fu,对于wi∈{w1,w2,w3…wn},如果fi<fl或者fi>fu,则从数据中删除单词wi;2.3)若wi为停止词,则从数据中删除单词wi;2.4)使用paragraph2vec对训练集中的所有问答数据进行无监督学习,得到问题和答案的特征表达向量,问题和答案分别被表示为vq∈rd和va∈rd,其中d为文本在语义特征空间的维数。3)改造传统的长短时记忆模型的结构,得到基于因果依赖关系和时序影响机制的长短记忆模型,基于问题和答案在语义空间中的隐性表达,将问题与答案之间的因果依赖关系和答案与答案之间的时序影响机制引入长短时记忆模型进行学习,得到问答排序模型。具体通过如下子步骤实现:3.1)为了在问答排序系统中引入因果依赖关系和时序影响机制,在传统长短时记忆模型的结构上进行修改,得到基于因果依赖关系和时序影响机制的长短时记忆模型,该模型的神经单元结构图如图1所示:其中,x(t)为当前时间节点的输入,{h(1),h(2),h(3)…h(t-1)}为前t-1个时间节点的隐输出,×与+分别为两个向量相应元素相乘和相加的操作,σ(·)为sigmoid函数,其定义为:tanh为tanh函数,其定义为:i(t),o(t),c(t),f(t),s(t)与h(t)定义如下:i(t)=σ[wixx(t)+wimm(t)+bi]o(t)=σ[woxx(t)+womm(t)+bo]c(t)=σ[wcxx(t)+wcmm(t)+bc]f(t)=σ[wfxx(t)+wfmm(t)+bf]s(t)=c(t)·i(t)+s(t-1)·f(t)h(t)=o(t)·tanh(s(t))其中w*x,w*m为参数矩阵,b*为偏移向量。不同于传统长短时记忆模型,本模型的结构单元会接收当前时间节点前所有时间节点的隐输出h(i),其中1≤i≤t-1。模型的结构单元会通过设置权重系数αi,将所接收的隐输出加权求和,得到新的向量m(t),定义如下:其中αi∈[0,1]并且初始化α1和其他α的过程不相同:α1为手工初始化,即人为设定α1的初始值;其他的α初始化为(1-α1)/(t-2)。m(t)将作为当前时间节点的隐输入,参与当前时间节点结构单元中各个门的计算。3.2)在模型训练过程中,模型在第一个时间节点读入一个训练样本中的问题向量vqi,称该节点为问题节点,问题节点产生其对应的隐输出h(1);模型在之后的每一个时间节点都会读入该训练样本中的一个答案向量这些节点被称为答案节点,答案节点产生其对应的隐输出h(t),t≥2。对于每一个答案节点,其接收的信息来源分为以下三种:a.答案向量b.问题节点的隐输出h(1);c.当前答案节点之前的所有答案节点的隐输出h(2),h(3)…h(t-1);其中,模型接收隐输出h(1)可以保留问题与答案之间的因果依赖关系,接收隐输出h(2),h(3)…h(t-1)可以得到答案与答案之间的时序影响机制;3.3)模型训练过程中,α1始终保持初始值不变。由于α1反映出问题与答案之间因果依赖关系的重要程度,为了探索其重要性,α1的初始值会按照0.01的步长从0.01到0.99进行调整,直到在评测指标上得到最好的结果。对于其他的αi,其反映了发表时间较早的答案对当前答案的时序影响程度,它们在训练的过程中会按照如下公式进行更新:其中h(t)tmp为当前答案节点再所有αi(2≤i≤t-1)更新前的隐输出。对于所有的答案节点,其α更新的过程如图2所示:其中(a)、(b)分别为α更新前和更新后,答案节点的计算过程。3.4)构建关联度匹配函数s(q,a):s(q,a)=σ(qtma)其中m为问题与答案的关联性度量矩阵,q为问题节点的隐输出,a为答案节点的隐输出,σ(·)为sigmoid函数;在关联度匹配函数基础上,定义损失函数l(t)如下:l(t)=max{0,γ-s(q,abest)+s(q,a′)}其中,abest为问题q的最佳答案,a′为其他的候选答案,γ为超参数;使用随机梯度下降算法求解损失函数,得到模型的参数,该优化等价于如下无约束优化问题:其中,θ为模型中所有参数,λ为正则项的超参数。4)使用学习后所得到的问答排序模型对新问题下的候选答案进行排序:基于问题和答案在语义空间中的隐性表达,使用问答排序模型对问题与每一个答案的关联性进行评分,根据关联性评分的高低对问题的候选答案进行分数排序,最后输出答案质量排序结果。具体通过如下子步骤实现:1)给定一个问题与该问题下按照时序发表的答案,将问题与答案按序读入模型;2)根据评分结构对答案进行排序,其结果即为答案质量排序结果。下面将上述方法应用于下列实施例中,以体现本发明的技术效果,实施例中具体步骤不再赘述。实施例本发明在百度知道中文数据集上进行答案质量排序实验。该数据集包含了100398个问题和308725个答案。每个问题只有一个最佳答案。每个问题的候选答案都有发表时间和被点赞数的标注。每一个问题或者答案被表达为300维的特征向量。为了客观地评价本发明的算法的性能,使用ndcg(normalizeddiscountedcumulativegain),p@1(precision@1),accuracy和mrr(meanreciprocalrank)对本发明进行评价。按照具体实施方式中描述的步骤,所得的实验结果如下:ndcgp@1accuracymrr0.92330.71570.80040.8155当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1