一种确定特殊学生群体上网特征的方法与流程
本发明属于信息技术领域,特别是涉及一种确定特殊学生群体上网特征的方法。
背景技术:
本发明属于信息技术领域。许多学生通过学校提供的网络服务连接到互联网,校园的网络计费系统会记录浏览器发出的每个url请求。本发明通过分析学生的网络记录提取出特殊学生群体的上网特征。特殊学生群体是指满足特定要求的学生群体,通常占全校学生的比例较小,如学业困难的学生、高智商学生或心理健康障碍的学生。通过分析特殊学生群体的上网特征可以帮助我们理解或识别这类学生,进而为其提供必要的服务。
利用学生上网记录来提取特殊学生群体的上网特征面临几个困难:
(1)特殊学生群体占全体学生的比例较小,其特征容易被其他学生掩盖;
(2)学生访问的网站数量庞大,不便于提取上网特征;
(3)少数学生访问的网站具有偶然性,从而使提取的上网特征不具有代表性。
技术实现要素:
有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是提供一种确定特殊学生群体上网特征的方法。
为实现上述目的,本发明提供了一种确定特殊学生群体上网特征的方法,包括以下步骤:
步骤一、对访问记录进行下抽样;
指定特殊学生群体为正样本,正常学生为负样本;从负样本中随机抽取和正样本数目相同的样本,使得正负样本数目相同;
步骤二、统计网站类别的访问频次;
首先创建一个目录表,该目录表给出所有网站对应的网站类别;然后根据该目录表统计出每个学生在不同网站类别的网站访问频次;
步骤三、对网站类别进行过滤;
将网站类别的频次作为特征,进行特征选择;
根据具体选用的信息统计准则,将步骤二所生成的每个学生在不同类别的网站访问频次信息与学生的分类信息进行计算,然后选择与学生的分类信息之间相关性好的若干个特征;
步骤四、去除高偶然性的网站;
所述步骤三按以下步骤进行:
步骤301:从候选特征子集中取出一个特征x,并计算f(x,y);
步骤302:判断f(x,y)与t1的关系;若f(x,y)>t1,则将该特征加入已选特征子集;否则,去除该特征;
步骤303:判断候选特征子集是否为空;若不为空,则转到步骤301;否则,输出已选特征子集。
较佳的,所述步骤四按以下步骤进行:
设置一个阈值t2,判断在某个网站类别上有访问量的比例是否小于t2,如果在某个网站类别上有访问量的比例小于t2,则去除该特征,否则结束;t2≥0。
较佳的,为了提高准确度,所述步骤301前,还执行归一化操作:
设定上网特征里面有一类为访问网站的频次a,b学生在这类上的取值的分别为a1,a2,a3,a4......,这些数组成一个数组求到最大值amax,最小值amin.那么对a1的归一化结果就是a1’=(a1-amin)/(amax-a1)。
本发明的有益效果是:本发明通过将具体网站映射成网站类别解决了网络数目过大的问题,采用信息统计准则过滤不重要的学生特征,通过对样本进行下抽样解决了特征学生群体比例较小的问题,通过去除偶然性高的网站类别提高了上网特征的代表性。
附图说明
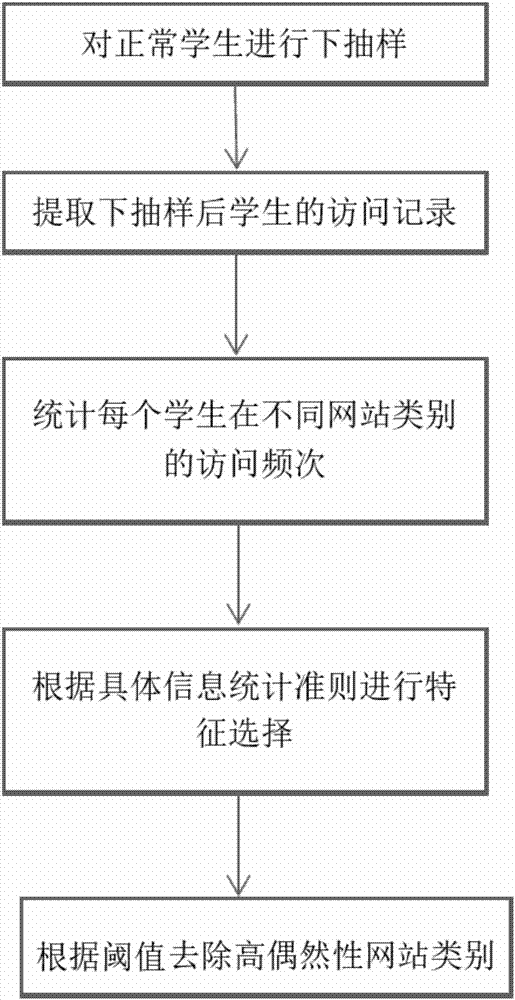
图1是本发明一具体实施方式的流程示意图。
图2是基于信息统计准则进行特征选择的流程示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明:
如图1、图2所示,一种确定特殊学生群体上网特征的方法,包括以下步骤:
步骤一、对访问记录进行下抽样;
指定特殊学生群体为正样本,正常学生为负样本;由于正负样本不均衡,正样本较少,那么可以对负样本进行下抽样,即从负样本中随机抽取和正样本数目相同的样本,使得正负样本数目相同;
具体过程:首先对正常学生进行下抽样;然后再将下抽样后得到的那些学生的访问记录提取出来。
步骤二、统计网站类别的访问频次;
统计不同网站类别的网站访问频次,将其作为特征进行后续操作;
首先创建一个目录表,该目录表给出所有网站对应的网站类别;然后根据该目录表统计出每个学生在不同网站类别的网站访问频次;
步骤三、对网站类别进行过滤;
即将网站类别的频次作为特征,进行特征选择的过程;根据一些基于信息统计的准则,如皮尔逊相关系数或互信息,来评价特征的好坏;可以根据实际情况设置一个阈值t1,若f(x,y)>t1,则保留该特征;其中f表示所选信息统计准则,x表示某个特征,y表示学生分类信息;
具体过程:根据具体选用的信息统计准则,将步骤二所生成的每个学生在不同类别的网站访问频次信息与学生的分类信息进行计算,然后选择与学生的分类信息之间相关性好的若干个特征;
步骤四、去除高偶然性的网站;
所述步骤三按以下步骤进行:
步骤301:初始化;候选特征子集初始化为所有特征;
步骤302:从候选特征子集中取出一个特征x,并计算f(x,y);
步骤303:判断f(x,y)与t1的关系;若f(x,y)>t1,则将该特征加入已选特征子集;否则,去除该特征;
步骤304:判断候选特征子集是否为空;若不为空,则转到步骤302;否则,输出已选特征子集,算法结束。
本实施例中所述步骤四按以下步骤进行:
设置一个阈值t2,判断在某个网站类别上有访问量的比例是否小于t2,如果在某个网站类别上有访问量的比例小于t2,则去除该特征,否则结束;t2≥0。
所述步骤301前,还执行归一化操作:
设定上网特征里面有一类为访问网站的频次a,b学生在这类上的取值的分别为a1,a2,a3,a4......,这些数组成一个数组求到最大值amax,最小值amin.那么对a1的归一化结果就是a1’=(a1-amin)/(amax-a1)。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!