基于海量数据的企业间数据关联关系捕捉方法及其系统与流程
本发明涉及数据处理,更具体地说是指基于海量数据的企业间数据关联关系捕捉方法及其系统。
背景技术:
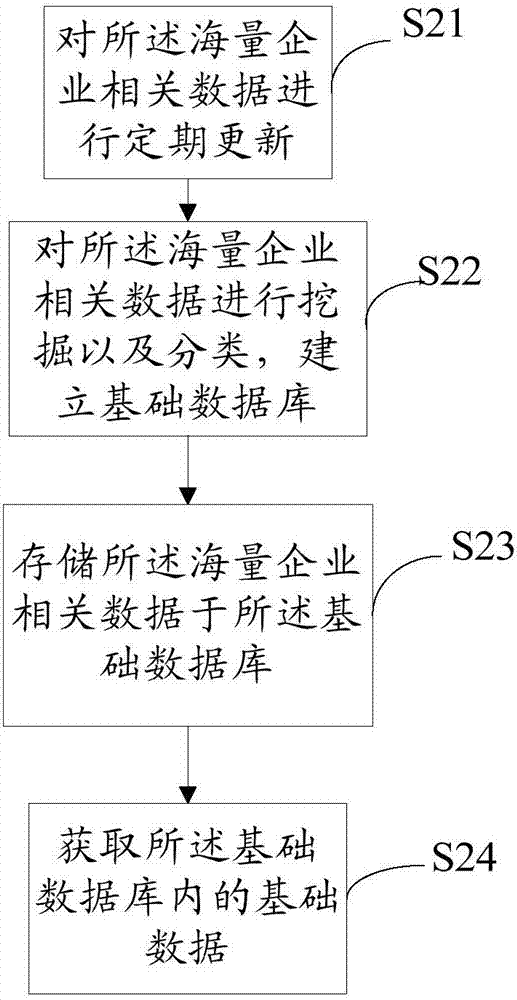
:随着科技的发展,越来越多的企业采用互联网公布数据的形式进行自身企业的宣传或者寻找投资对象,因此,企业在互联网上的数据越来越多,互联网上的企业数据库越来越庞大。在宣传或者寻找投资对象过程中,需要从互联网上的海量数据中寻找与企业间数据的关联关系,以此作为定位条件,准确定位到所需找的企业。但是,目前的寻找企业间数据关联关系只能通过人工筛选和分析,这导致很难对企业进行全方位的分析以及企业全息画像,而且人工筛选和分析效率低下,准确率也低。中国专利201510810811.2提供了一种基于关系数据库从大数据下检索相同主从关系数据的算法,是海量数据中进行数据比对的一种算法,采用“大而化小,先面后点”,利用分组遍历、中间表存储等算法逐步缩小数据比对范围,高效检索出相同的记录。上述发明针对企业数据中海量主从结构数据,快速检索出相同记录的方法适用于企业管控中的需要检索相同主从结构数据的各种情形,增强企业的管控能力,为企业营造更好的市场环境,提高企业竞争力。上述的专利采用的是快速检索出相同记录的方法,这种方式只能寻找类似的记录,准确度不高。因此,有必要设计一种基于海量数据的企业间数据关联关系捕捉方法,实现提高捕捉的准确度,且从海量数据中,对企业有效的数据进行自动关联以及自动分类,效率高。技术实现要素:本发明的目的在于克服现有技术的缺陷,提供基于海量数据的企业间数据关联关系捕捉方法及其系统。为实现上述目的,本发明采用以下技术方案:基于海量数据的企业间数据关联关系捕捉方法,所述方法包括:获取海量企业相关数据;对海量企业相关数据进行积累,形成基础数据;对获取的所述海量企业相关数据进行处理,形成处理数据;根据处理数据以及基础数据,获取训练集数据库;利用训练集数据库对新数据进行处理,获取企业间数据关联关系。其进一步技术方案为:对海量企业相关数据进行积累,形成基础数据的步骤,包括以下具体步骤:对所述海量企业相关数据进行定期更新;对所述海量企业相关数据进行挖掘以及分类,建立基础数据库;存储所述海量企业相关数据于所述基础数据库;获取所述基础数据库内的基础数据。其进一步技术方案为:对获取的所述海量企业相关数据进行处理,形成处理数据的步骤,包括以下具体步骤:对获取的所述海量企业相关数据进行清洗、归类、提取摘要以及提取关键字;对所述摘要和关键字建立索引;对所述信息、摘要以及关键字进行分类,获取分类结果;对分类结果进行实时匹配及统计,形成处理数据。其进一步技术方案为:根据处理数据以及基础数据,获取训练集数据库的步骤,包括以下具体步骤:根据处理数据以及基础数据,做成训练集;对处理数据进行抽样调查和调整;将调整后的处理数据存储至训练集内;对训练集进行训练;利用权值进行训练改进,形成训练集数据库。其进一步技术方案为:利用训练集数据库对新数据进行处理,获取企业间数据关联关系的步骤,包括以下具体步骤:利用训练集数据对训练集数据库进行训练,获取使用模型;采用使用模型对新数据进行分类和预测,获取企业间数据关联关系。本发明还提供了基于海量数据的企业间数据关联关系捕捉系统,包括获取单元、基础数据形成单元、处理数据形成单元、数据库获取单元以及关系获取单元;所述获取单元,用于获取海量企业相关数据;所述基础数据形成单元,用于对海量企业相关数据进行积累,形成基础数据;所述处理数据形成单元,用于对获取的所述海量企业相关数据进行处理,形成处理数据;所述数据库获取单元,用于根据处理数据以及基础数据,获取训练集数据库;所述关系获取单元,用于利用训练集数据库对新数据进行处理,获取企业间数据关联关系。其进一步技术方案为:所述基础数据形成单元包括更新模块、数据库建立模块、存储模块以及基础数据获取模块;所述更新模块,用于对所述海量企业相关数据进行定期更新;所述数据库建立模块,用于对所述海量企业相关数据进行挖掘以及分类,建立基础数据库;所述存储模块,用于存储所述海量企业相关数据于所述基础数据库;所述基础数据获取模块,用于获取所述基础数据库内的基础数据。其进一步技术方案为:所述处理数据形成单元包括处理模块、索引建立模块、分类模块以及匹配统计模块;所述处理模块,用于对获取的所述海量企业相关数据进行清洗、归类、提取摘要以及提取关键字;所述索引建立模块,用于对所述摘要和关键字建立索引;所述分类模块,用于对所述信息、摘要以及关键字进行分类,获取分类结果;所述匹配统计模块,用于对分类结果进行实时匹配及统计,形成处理数据。其进一步技术方案为:所述数据库获取单元包括训练集形成模块、调整模块、处理数据存储模块、训练模块以及改进模块;所述训练集形成模块,用于根据处理数据以及基础数据,做成训练集;所述调整模块,用于对处理数据进行抽样调查和调整;所述处理数据存储模块,用于将调整后的处理数据存储至训练集内;所述训练模块,用于对训练集进行训练;所述改进模块,用于利用权值进行训练改进,形成训练集数据库。其进一步技术方案为:所述关系获取单元包括模型获取模块以及分类预测模块;所述模型获取模块,用于利用训练集数据对训练集数据库进行训练,获取使用模型;所述分类预测模块,用于采用使用模型对新数据进行分类和预测,获取企业间数据关联关系。本发明与现有技术相比的有益效果是:本发明的基于海量数据的企业间数据关联关系捕捉方法,通过采集海量的企业相关数据,获取成本低,采用大数据技术进行数据处理,保证海量数据的安全存储,保证海量数据分布式处理,效率高,准确度随着数据的积累不断提升,以大数据技术驱动以及基于分布式并行计算架构解决海量数据的存储和计算的问题,使用机器学习和自然语言处理的理论,让机器智能处理企业相关信息,进行摘要、归类以及提取,实现提高捕捉的准确度,且从海量数据中,对企业有效的数据进行自动关联以及自动分类,识别效率高。下面结合附图和具体实施例对本发明作进一步描述。附图说明图1为本发明具体实施例提供的基于海量数据的企业间数据关联关系捕捉方法的流程图;图2为本发明具体实施例提供的形成基础数据的具体流程图;图3为本发明具体实施例提供的形成处理数据的具体流程图;图4为本发明具体实施例提供的获取训练集数据库的具体流程图;图5为本发明具体实施例提供的获取企业间数据关联关系的具体流程图;图6为本发明具体实施例提供的基于海量数据的企业间数据关联关系捕捉系统的结构框图;图7为本发明具体实施例提供的基础数据形成单元的结构框图;图8为本发明具体实施例提供的处理数据形成单元的结构框图;图9为本发明具体实施例提供的数据库获取单元的结构框图;图10为本发明具体实施例提供的关系获取单元的结构框图。具体实施方式为了更充分理解本发明的技术内容,下面结合具体实施例对本发明的技术方案进一步介绍和说明,但不局限于此。如图1~10所示的具体实施例,本实施例提供的基于海量数据的企业间数据关联关系捕捉方法,可以运用在企业的宣传或者寻找投资对象过程,实现提高捕捉的准确度,且从海量数据中,对企业有效的数据进行自动关联以及自动分类,效率高。如图1所示,是本实施例提供的基于海量数据的企业间数据关联关系捕捉方法,该方法包括:s1、获取海量企业相关数据;s2、对海量企业相关数据进行积累,形成基础数据;s3、对获取的所述海量企业相关数据进行处理,形成处理数据;s4、根据处理数据以及基础数据,获取训练集数据库;s5、利用训练集数据库对新数据进行处理,获取企业间数据关联关系。对于s1步骤,获取海量企业相关数据的步骤,具体是采用数据爬取技术,每天从互联网上采集和爬取企业相关数据。更进一步的,上述的s2步骤,对海量企业相关数据进行积累,形成基础数据的步骤,包括以下具体步骤:s21、对所述海量企业相关数据进行定期更新;s22、对所述海量企业相关数据进行挖掘以及分类,建立基础数据库;s23、存储所述海量企业相关数据于所述基础数据库;s24、获取所述基础数据库内的基础数据。对于上述s21步骤,对海量企业相关数据进行定期更新,起到积累数据的作用。对于上述s22步骤,具体是使用机器学习技术,通过对互联网上海量企业相关数据进行挖掘以及分类,以此来建立基础数据数据库。对于上述的s23步骤,具体是使用大数据hdfs技术分布式存储海量企业相关数据。上述的s24步骤,基础数据库内的基础数据是由海量企业相关数据进行积累以及处理后的数据。更进一步的,上述的s3步骤,对获取的所述海量企业相关数据进行处理,形成处理数据的步骤,包括以下具体步骤:s31、对获取的所述海量企业相关数据进行清洗、归类、提取摘要以及提取关键字;s32、对所述摘要和关键字建立索引;s33、对所述信息、摘要以及关键字进行分类,获取分类结果;s34、对分类结果进行实时匹配及统计,形成处理数据。上述的s31步骤,具体是基于自然语言处理的理论和技术,对采集返回的海量企业相关数据进行清洗、归类、提取摘要以及提取关键字。对于上述s32步骤,具体是对采用自然语言处理的理论与技术处理后的摘要和关键字,建立索引。上述的s33步骤,具体采用的是使用k最近邻(k-nearestneighbor,knn)分类对上述的信息、摘要以及关键字进行分类,获取分类结果。上述的s34步骤,具体采用的是使用大数据spark对分类结果的进行实时匹配及统计,以此形成处理数据。上述的s1步骤至s3步骤,均是基于成熟的大数据技术对从互联网上获取到的海量企业相关数据进行处理,保证海量数据的安全存储,保证海量数据分布式处理,效率高,准确度随着数据的积累不断提升。并且以大数据技术驱动,基于分布式并行计算架构,解决海量数据的存储以及计算的问题,使用机器学习和自然语言处理的理论,让机器智能处理企业相关信息,进行摘要、归类以及提取等。基于互联网公开信息收集和处理,不存在敏感信息,数据获取成本较低。更进一步的,上述的s4步骤,根据处理数据以及基础数据,获取训练集数据库的步骤,包括以下具体步骤:s41、根据处理数据以及基础数据,做成训练集;s42、对处理数据进行抽样调查和调整;s43、将调整后的处理数据存储至训练集内;s44、对训练集进行训练;s45、利用权值进行训练改进,形成训练集数据库。上述的s41步骤,利用基础数据库内的基础数据以及分类、匹配和统计后的处理数据进行综合和匹配,以此作为训练集,以明确基础数据与处理数据的关联关系,便于捕捉新数据的关联关系。上述的s42步骤,主要是为了提高基础数据与处理数据之间关联关系的准确度,因此,需要人工对处理数据进行抽样调查和调整,以确保处理数据的准确度,从而确保关联关系的准确度。上述的s43步骤,主要是为了更正训练集内的处理数据,以调整后的处理数据为准,与基础数据进行综合,形成准确度较高的数据关联关系。对于上述的s45步骤,随着数据的累计,采用权值的方式进行训练改进,权值的方式主要是和该样本距离小的邻居权值大。具体而言,权值设置过小会降低分类精度,若设置过大,且测试样本属于训练集中包含数据较少的类,则会增加噪声,降低分类效果。因此,权值要设置妥当,才可以提高企业间数据关联关系捕捉的准确度,通常,k值的设定采用交叉检验的方式(以k=1为基准),经验规则:k一般低于训练样本数的平方根。更进一步的,上述的s5步骤,利用训练集数据库对新数据进行处理,获取企业间数据关联关系的步骤,包括以下具体步骤:s51、利用训练集数据对训练集数据库进行训练,获取使用模型;s52、采用使用模型对新数据进行分类和预测,获取企业间数据关联关系。上述的s51步骤,对训练集数据库进行训练,有利于提高训练集数据库的真实度,以此提高企业间数据关联关系捕捉的准确度。对于上述的s52步骤,以训练后的训练集数据库作为使用模型,利用使用模型对新数据进行分类和预测,获取企业间数据关联关系,从而实现自动分类,同时随着数据量的累积,准确率越来越高。上述的s51步骤至s52步骤,可参照下述实施例:#将训练集代入到knn模型中;clf=kneighborsclassifier(n_neighbors=3);clf.fit(x_train,y_train);#使用测试集衡量模型准确度;clf.score(x_test,y_test);#设置新数据;new_data=np.array([[5000,40000]]);#对新数据进行分类预测;clf.predict(new_data)。如上述的例子而言,训练集数据库的数据如下表所示:点号数据数据数据类别11.02.03.0121.02.13.1130.92.22.9143.46.78.9253.07.08.7263.36.98.8272.53.310.0382.42.98.03新数据如下表所示:点号数据数据数据类别12.15.57.2021.12.54.2034.13.59.20分类后的新数据如下表所示:点号数据数据数据类别11.12.54..2122.15.57.2234.13.59.23上述的基于海量数据的企业间数据关联关系捕捉方法,通过采集海量的企业相关数据,获取成本低,采用大数据技术进行数据处理,保证海量数据的安全存储,保证海量数据分布式处理,效率高,准确度随着数据的积累不断提升,以大数据技术驱动以及基于分布式并行计算架构解决海量数据的存储和计算的问题,使用机器学习和自然语言处理的理论,让机器智能处理企业相关信息,进行摘要、归类以及提取,实现提高捕捉的准确度,且从海量数据中,对企业有效的数据进行自动关联以及自动分类,识别效率高。如图6所示,是本实施例提供的基于海量数据的企业间数据关联关系捕捉系统,其包括获取单元1、基础数据形成单元2、处理数据形成单元3、数据库获取单元4以及关系获取单元5。获取单元1,用于获取海量企业相关数据。基础数据形成单元2,用于对海量企业相关数据进行积累,形成基础数据。处理数据形成单元3,用于对获取的所述海量企业相关数据进行处理,形成处理数据。数据库获取单元4,用于根据处理数据以及基础数据,获取训练集数据库。关系获取单元5,用于利用训练集数据库对新数据进行处理,获取企业间数据关联关系。获取单元1具体是采用数据爬取技术,每天从互联网上采集和爬取企业相关数据。更进一步的,基础数据形成单元2包括更新模块21、数据库建立模块22、存储模块23以及基础数据获取模块24。更新模块21,用于对所述海量企业相关数据进行定期更新。数据库建立模块22,用于对所述海量企业相关数据进行挖掘以及分类,建立基础数据库。存储模块23,用于存储所述海量企业相关数据于所述基础数据库。基础数据获取模块24,用于获取所述基础数据库内的基础数据。更新模块21对海量企业相关数据进行定期更新,起到积累数据的作用数据库建立模块22具体是使用机器学习技术,通过对互联网上海量企业相关数据进行挖掘以及分类,以此来建立基础数据数据库。存储模块23具体是使用大数据hdfs技术分布式存储海量企业相关数据。上述的基础数据库内的基础数据是由海量企业相关数据进行积累以及处理后的数据。更进一步的,处理数据形成单元3包括处理模块31、索引建立模块32、分类模块33以及匹配统计模块34。处理模块31,用于对获取的所述海量企业相关数据进行清洗、归类、提取摘要以及提取关键字。索引建立模块32,用于对所述摘要和关键字建立索引。分类模块33,用于对所述信息、摘要以及关键字进行分类,获取分类结果。匹配统计模块34,用于对分类结果进行实时匹配及统计,形成处理数据。处理模块31具体是基于自然语言处理的理论和技术,对采集返回的海量企业相关数据进行清洗、归类、提取摘要以及提取关键字。索引建立模块32具体是对采用自然语言处理的理论与技术处理后的摘要和关键字,建立索引。分类模块33具体采用的是使用k最近邻(k-nearestneighbor,knn)分类对上述的信息、摘要以及关键字进行分类,获取分类结果。匹配统计模块34具体采用的是使用大数据spark对分类结果的进行实时匹配及统计,以此形成处理数据。上述的获取单元1、基础数据形成单元2以及理数据形成单元均是基于成熟的大数据技术对从互联网上获取到的海量企业相关数据进行处理,保证海量数据的安全存储,保证海量数据分布式处理,效率高,准确度随着数据的积累不断提升。并且以大数据技术驱动,基于分布式并行计算架构,解决海量数据的存储以及计算的问题,使用机器学习和自然语言处理的理论,让机器智能处理企业相关信息,进行摘要、归类以及提取等。基于互联网公开信息收集和处理,不存在敏感信息,数据获取成本较低。另外,数据库获取单元4包括训练集形成模块41、调整模块42、处理数据存储模块43、训练模块44以及改进模块45。训练集形成模块41,用于根据处理数据以及基础数据,做成训练集。调整模块42,用于对处理数据进行抽样调查和调整。处理数据存储模块43,用于将调整后的处理数据存储至训练集内。训练模块44,用于对训练集进行训练。改进模块45,用于利用权值进行训练改进,形成训练集数据库。上述的训练集形成模块41利用基础数据库内的基础数据以及分类、匹配和统计后的处理数据进行综合和匹配,以此作为训练集,以明确基础数据与处理数据的关联关系,便于捕捉新数据的关联关系。调整模块42主要是为了提高基础数据与处理数据之间关联关系的准确度,因此,需要人工对处理数据进行抽样调查和调整,以确保处理数据的准确度,从而确保关联关系的准确度。处理数据存储模块43主要是为了更正训练集内的处理数据,以调整后的处理数据为准,与基础数据进行综合,形成准确度较高的数据关联关系。随着数据的累计,改进模块45采用权值的方式进行训练改进,权值的方式主要是和该样本距离小的邻居权值大。具体而言,权值设置过小会降低分类精度,若设置过大,且测试样本属于训练集中包含数据较少的类,则会增加噪声,降低分类效果。因此,权值要设置妥当,才可以提高企业间数据关联关系捕捉的准确度,通常,k值的设定采用交叉检验的方式(以k=1为基准),经验规则:k一般低于训练样本数的平方根。更进一步的,关系获取单元5包括模型获取模块51以及分类预测模块52。模型获取模块51,用于利用训练集数据对训练集数据库进行训练,获取使用模型。分类预测模块52,用于采用使用模型对新数据进行分类和预测,获取企业间数据关联关系。模型获取模块51对训练集数据库进行训练,有利于提高训练集数据库的真实度,以此提高企业间数据关联关系捕捉的准确度。分类预测模块52以训练后的训练集数据库作为使用模型,利用使用模型对新数据进行分类和预测,获取企业间数据关联关系,从而实现自动分类,同时随着数据量的累积,准确率越来越高。上述的模型获取模块51以及分类预测模块52的工作过程,可参照下述实施例:#将训练集代入到knn模型中;clf=kneighborsclassifier(n_neighbors=3);clf.fit(x_train,y_train);#使用测试集衡量模型准确度;clf.score(x_test,y_test);#设置新数据;new_data=np.array([[5000,40000]]);#对新数据进行分类预测;clf.predict(new_data)。上述的基于海量数据的企业间数据关联关系捕捉系统,通过采集海量的企业相关数据,获取成本低,采用大数据技术进行数据处理,保证海量数据的安全存储,保证海量数据分布式处理,效率高,准确度随着数据的积累不断提升,以大数据技术驱动以及基于分布式并行计算架构解决海量数据的存储和计算的问题,使用机器学习和自然语言处理的理论,让机器智能处理企业相关信息,进行摘要、归类以及提取,实现提高捕捉的准确度,且从海量数据中,对企业有效的数据进行自动关联以及自动分类,识别效率高。上述仅以实施例来进一步说明本发明的技术内容,以便于读者更容易理解,但不代表本发明的实施方式仅限于此,任何依本发明所做的技术延伸或再创造,均受本发明的保护。本发明的保护范围以权利要求书为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1