基于社团发现的主题模型构建方法与流程
本发明涉及一种基于社团发现的主题模型构建方法,尤其涉及内部蕴含社会网络的社交型短文本数据主题挖掘的技术。
背景技术:
在当前的网络环境下,随着各种线上平台的丰富,大量的社交型数据被产生出来,社交网络俨然已经成为了一个进行信息挖掘的数据源泉。在此场景下产生的数据,大部分又以短文本的形式呈现。相对于长文本,短文本表达的语义简练,传递信息的速度快,是信息传播的一个明显发展趋势。短文本正在成为当今社会最重要的信息载体之一。
目前在对这些数据的分析方法中,通过主题模型挖掘文本内涵的语义信息是一种很有效的方式。经典的主题模型算法,如plsa、lda等主要基于双模式和词共现关系对文本进行语义分析。这类算法在对长篇的文档进行处理时效果是显著的,而在针对短文本时,因为词共现关系不足,使算法面临数据稀疏性问题,会严重影响模型质量。
现阶段学术界针对这种短文本的主题模型主要有下面五种处理方案:1)采用简单的拼接,把短文本直接连在一起;2)用引入外界资料库的方法将短文本聚合成长文本;3)从一种启发式的方法来实现,如基于推特内容的标签信息、内容发送的时间流信息或者发送内容的作者等对文本进行扩展;4)对文本的主题采用宽松的假设,假设一个短文本中只包含一个主题;5)对建模对象进行改变。比较有代表性的是yan等人在2013年提出的btm模型。
以上方案或强行抹去了文档的边界或受到外界资料的干扰等,具有诸多不足之处。
技术实现要素:
本发明提出一种基于社团发现的主题模型(即tmcd模型,topicmodelbasedoncommunitydetection)构建方法,该方法可针对社交型数据集构建主题模型,即采用社会发现算法为社交型短文本数据的主题挖掘提供解决方案。tmcd模型从数据中内在蕴含的社团关系的角度出发,以社团发现算法为基础进行短文本的自扩展,解决了数据稀疏性问题。
为解决上述问题,本发明所公开的基于社团发现的主题模型构建的方法的技术方案包括如下步骤:
步骤1、基于短文本数据提取蕴含的关系网络;
步骤2、采用社团发现算法将关系网络划分成多个社团;
步骤3、将各社团中提取的短文本进行扩充以得到具有词共现关系的长文档,
并将得到的多个长文档构成长文档集合;
步骤4、针对长文档集合进行主题挖掘,得到基于社团发现的tmcd主题模型。
进一步的,步骤1中关系网络的提取过程是:采用短文本数据中的主体作为结点,通过主体间交互关系进行关联并抽象形成边,将得到的结点和边共同形成一关系网络。
进一步的,以主体间交互关系的密切程度作为边的权重,以关联的主被动关系作为边的方向。
进一步的,步骤2中所述的社团发现算法包括凝聚、分裂、标签传播和全局探索中的一种或多种。
进一步的,步骤3中是采用自扩展方法对短文本进行扩充。
进一步的,所述短文本数据是内部蕴含着社会网络的社交型数据,所述关系网络是社会网络。
本发明所公开的基于社团发现的主题模型构建方法,为社交型短文本数据的主题挖掘提供了新的解决方案,具有以下有益效果:
(1)该方法通过挖掘数据内部蕴含的社团网络关联来作为文本分类依据,在此基础上完成对短文本的扩充,进而解决短文本主题挖掘中数据稀疏性的问题,为此类社交型短文本数据集主题模型构建提供了解决方案。
(2)该方法通过基于内容相似性的自扩展方法,在不引入外界帮助数据的情况下,解决了现有短文本主题建模解决方案中因简单拼接所有具有内容相关性和不具备内容相关性的文本而导致的强行抹去了文档的边界的问题或因为引入了外部辅助语料库而带来的外部噪音干扰问题,并从根本上避免了词共现关系不足对主题模型的影响。
附图说明
图1为主题模型中文档-主题-词语之间的关系示意图。
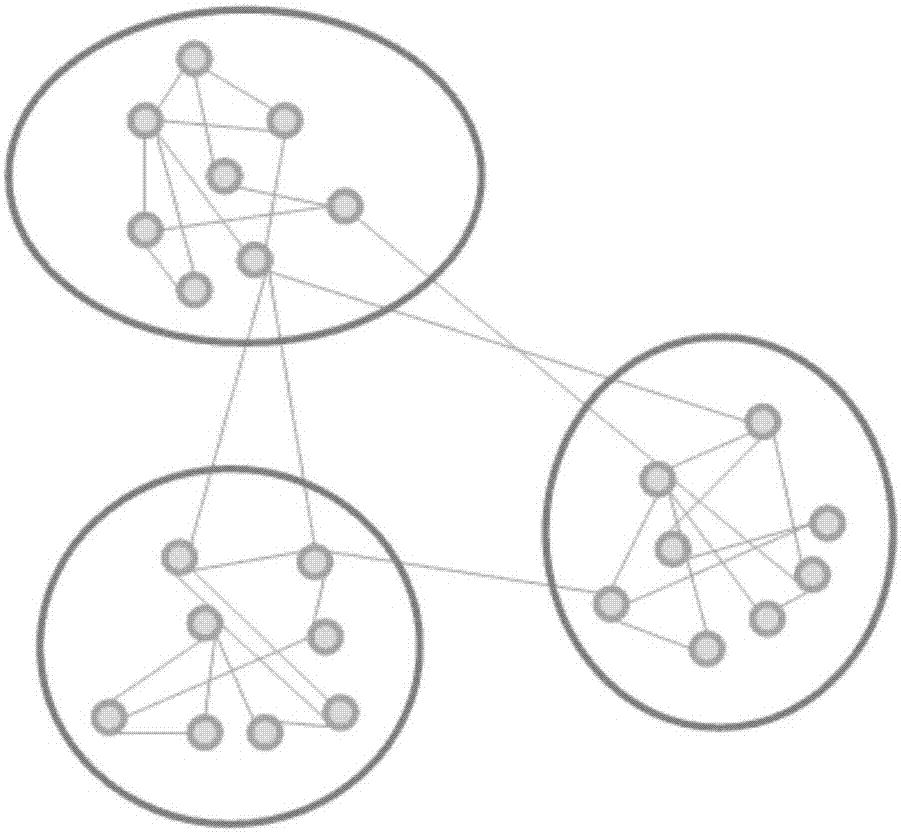
图2为社会网络示意图。
图3为实施例中针对社交型数据集的主题模型构建方法的流程图。
图4为图3中短文本扩充部分的流程图。
具体实施方式
为了更了解本发明的技术内容,特举具体实施例并配合所附图式说明如下。
如图1所示为主题模型中文档、主题、词汇之间的关系。在数据引入“主题”这一概念后,主题就可以作为联系文档与词的“桥梁”,通过观测文档与主题之间的概率分布以及主题与词汇之间的概率分布即可通过相关数学模型得到主体的分布情况。在获取主题与词关系时,词共现关系的多少会影响到观测结果的准确度,此准确度也会进一步影响最终主题模型的质量。对于长文本来说,在观测时有足够多的词共现关系作为支撑,而短文本则缺乏足够的词共现关系,也就是出现了数据的稀疏性问题。本发明提出的tmcd模型构建方法正是针对此问题的解决而展开的。
如图2所示,实施例中tmcd模型针对社交型数据,通过对数据集中的关键主体(即数据集中产生数据的对象,一般为联系人)和主体间的关联(即产生数据的传播途径)进行抽象后得到的主题模型,会呈现出一个明显的社会网络。这里的抽象是指把数据集中有实际意义的联系人和联系人之间的关系等抽象为社会网络中的结点和边。其中,抽象数据集中的主体对象为结点,如社交数据中以联系人为结点;抽象主体间关联为边,以关联的密切程度作为边的权重,如社交数据中联系人互发消息作为边,发消息的条数作为权重,以发消息的主被动关系作为边的方向。得到的社会网络的一个重要特征就是蕴含着社团结构,而社团结构是指社会网络通过一些算法作用可被划分为若干社团,且同一社团中的数据具有相似性。在划分的结果中,社团内部的结点关系较为密切,联系紧密,而社团间的结点联系比较稀疏。
如图3为实施例中一种针对社交型数据集的主题模型构建方法的流程图,该方法基于社团发现进行模型构建,包括如下步骤:
步骤1:根据社交型数据内部的主体和主体间数据的传播关系提取蕴含的社会网络。其中,社交型数据包含所有内部蕴含着社会网络的数据集,如:qq、微信等即时通信中联系人实时生成的信息构成的数据集,微博、知乎等在线社交平台由转发、评论数据产生的数据集等。具体提取过程如下:
1)采用抽象数据(即社交型数据)中的主体作为结点,其中,抽象数据中的主体包含可以作为构建的社会网络中结点的对象,如人、物或事件等;
2)通过主体间交互关系进行关联,抽象形成边,其中,交互关系包含所有可以在两个主体间形成有效关联的关系,如:由即时通信中消息的传递构成主体联系人的关联,在线社交平台中转发、评论、分享构成的主体关联等;
3)基于上述步骤抽象得到的结点和边形成一个明显的社会网络。
步骤2:采用社团发现算法将社会网络划分成多个社团结构。社团发现算法包括所有可以针对社会网络进行有效社团划分的算法,包括但不限于基于凝聚过程、分裂过程、标签传播和全局探索(包括谱分析)思路实现的算法,这也是大部分社团发现算法的设计思想,几乎涵盖所有可以有效划分的社团发现算法。
步骤3:依据社团结构划分结果对各社团中包含的短文本进行扩充。扩充方法主要包括如下子步骤:
1)提取各个划分出的社团下包含的多个结点所对应的短文本数据;
2)通过基于自扩展的传统扩充方法把短文本扩充为长文档;
3)基于上述步骤可以得到若干个(取决于划分出社团的数目)由社会网络中具有文本相似性的数据自扩充得到的包含丰富词共现关系的长文档,并将各社团扩充后得到的长文档构成一个长文档集合。
值得说明的是,基于自身数据集进行扩展,不引入外界帮助数据,具体可以直接拼接法为例作说明,即,将提取出的短文本直接进行连接,这种扩充方法本身不会考虑文本是否具有相似性,此场景下具体操作为把所有位于同一社团下多个结点所对应的文本扩充作为一个长的文档。
步骤4:针对长文档集合进行主题建模,并得到tmcd模型。使用传统的主题模型构建方法(如:lda、概率潜在语义分析plsa等),以文档中丰富的词共现关系得到词-主题的观测结果,再结合观测到的文档-主题结果,通过一定的数学方法(如:吉布斯采样等)完成主题分析和挖掘过程,得到针对社交型数据集的tmcd模型。该tmcd模型将直观的输出文档中包含的主题情况和对应关键词等信息,相较于直接把传统主题模型方法作用在短文本上,tmcd模型额外进行了基于社团发现的文本扩充过程,使得文本中有足够的词共现关系,从而大幅提高主题挖掘的结果的质量。
如图4所示为实施例中步骤3的第2)子步骤所述的短文本扩充部分的流程图,具体包括以下步骤:
s3-1为短文本提取操作,按照图3步骤2中社团划分的结果提取一个未扩充社团中所包含的多个结点,然后从每个结点的信息中提取对应的短文本数据;
s3-2为短文本扩充操作,把步骤3-1中提取的短文本通过基于自扩充方式进行扩展,此处以自扩充方式中的直接拼接法为例作说明,即把提取出的短文本直接进行连接,把所有位于此社团的文本扩充成一个长的文档;
s3-3为判断条件,判断是否所有短文本以按照社团划分结果进行了扩充操作。若有未进行扩充的社团则进入步骤3-1,否则进入步骤3-4;
s3-4为返回扩充后的长文档集,依据社团划分结果的短文本扩充步骤结束。
综上所述,实施例中,基于社会发现的主题模型构建的方法为社交型数据集的主题的挖掘提供了一种新的思路,该方法通过对社交型数据集内部蕴含的社团结构的发现,并以此为基础进行短文本的自扩充形成长的文档集,解决了直接在短文本上进行主题挖掘所面临的数据稀疏性问题,大幅度提高了主题模型的质量,为社交型数据集的主题模型提供了解决方案。
虽然本发明已在较佳的实施例揭露如上,然其并非用以限定本发明。本发明所属技术领域中具有通常知识者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰。因此,本发明的保护范围当视权利要求书所界定者为准。
- 还没有人留言评论。精彩留言会获得点赞!