一种基于模糊神经网络和图模型推理的动作识别方法与流程
本发明属于人体运动识别技术领域,具体涉及一种基于模糊神经网络和图模型推理的动作识别方法。
背景技术:
近年来,人体动作识别已经成为计算机视觉领域的核心问题。从早期受限条件下简单的动作识别发展到对真实自然场景下复杂动作的识别;从对单人动作的识别到对交互动作甚至是大规模群体动作识别。由于人体运动的复杂性和不确定性,动作识别仍然是一个非常具有挑战性的课题。许多动作识别方法侧重于设计有效的描述符或特征,通过特征匹配进行分类。以往的动作识别主要包含两个类别:特征表示和动作分类。特征表示始终是动作识别的关键任务。一般而言,动作序列特征表示通常分为全局表示和局部表示。全局特征记录总图像呈现,然而,全局特征经常受到遮挡、视点变化和噪声的干扰。基于全局的特征包括基于光流的呈现、基于剪影的描述符、基于边缘的特征和运动历史图像等。局部特征总是独立地描述补丁,并将补丁组合在一起构建时空模型。局部描述符可以更有效地呈现动作视频,尤其是对于噪声图像和部分遮挡图像的呈现。
技术实现要素:
本发明的目的是提供一种基于模糊神经网络和图模型推理的动作识别方法,克服了现有方法较高的计算成本,运动捕获数据较低的应用效率和对紧密匹配的运动的检索不能区分到位的问题。
本发明采用的技术方案是,一种基于模糊神经网络和图模型推理的动作识别方法,具体按照以下步骤实施:
步骤1:使用kinect设备拍摄单目及深度视频,拍摄速度为30帧每秒,构建有n个类别的人体运动视频序列数据库dvideo=(v1,v2,...,vi,...,vn);
步骤2:提取视频vi的每帧图像,得到帧图像fi=(fi1,...,fin),其中n表示视频vi的帧数,对fij进行预处理,通过背景差分和肤色模型获取出fij中运动轮廓,通过人体骨架提取法获得运动骨架;
步骤3:基于获得的帧图像fi=(fi1,...,fin)聚类获取运动序列代表性的帧rfi=(rfi1,…,rfic);所有视频运动类别所对应的代表性帧图像组成人体运动代表帧图像数据库drf={rfi},i=1,…,p,p代表数据库总运动序列数;
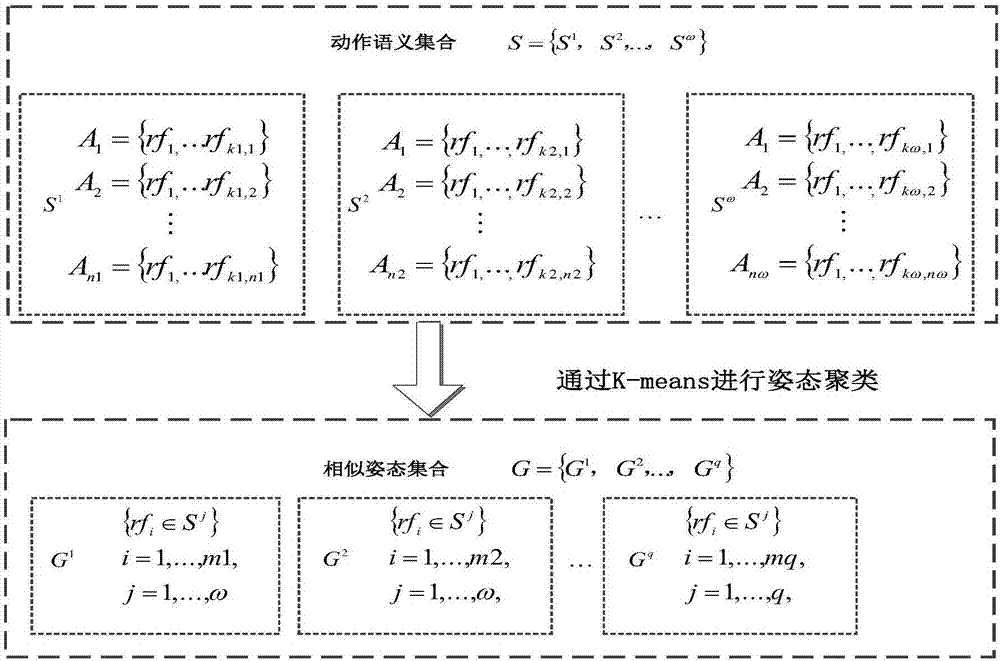
步骤4:基于所有获得的运动姿势关键帧骨架特征训练数据的分类,首先建立动作语义集s={s1,…,sω},其中ω是通过聚类后动作语义分类的个数;然后基于关键帧运动骨架特征聚类以形成相似的运动集合g={g1,…,gq},其中q是聚类组的个数;
步骤5:构建一个基于概率图模型的模糊神经网络系统进行运动语义推理,来识别由每个代表帧确定的身体姿态语义,使用概率图推理来分类动作语义序列;首先训练设计的fnn作为人体姿势分类器;其次,在训练完成的fnn基础上构建图模型;
步骤6:基于步骤5中构建的fnngm图模型结构,进行图模型推理,对动作语义序列进行分类;将{rf1:k}作为一个测量的图模型;系统状态序列为s={s1:k}和g={g1:k},基于图模型推理的对动作识别进行描述。
本发明的特点还在于,
步骤2具体按照以下步骤实施:
(21)使用kinect获取人体运动的rgb彩色与深度图像,去除rgb彩色与深度图像噪声,并对其进行图像校正处理;
(22)根据彩色图像背景的复杂程度采用不同方法去除背景,获得前景彩色图像;
(23)基于前景彩色图像且依据肤色模型对脸部及手部进行定位并将脸部及手部定位质心作为初始获取的关节点;
(24)基于学习得到的贝叶斯分类器对彩色图像前景中的运动人体进行部件分类识别;
(25)依据分类识别结果判定肢体各刚体结构部位类别,再根据各刚体部件的链接关系确定出各关节点,依次联接各关节点形成平面人体骨架结合各个关节点深度数据将平面骨架变换成三维立体骨架。
步骤3具体按照以下步骤实施:
(31)给定运动序列fi,使用模糊c均值fcm聚类方法生成代表帧rfi;
(32)使用四元数来呈现身体姿态,计算两帧间距离;设fi为第i帧中的运动描述符,f1和f2之间的距离计算为:
d(f1,f2)=(f1-f2)(f1-f2)t
使用聚类方法来生成c个聚类中心,选择距离聚类中心最短距离的一些帧作为代表帧,代表帧可表示为rfi={rfk}k=1:c,其中rfk对应于第k个聚类中心。
步骤4具体按照以下步骤实施:
(41)从获取的所有运动代表帧中任意选择q个关键帧骨架运动特征作为初始聚类中心;
(42)根据每个聚类对象的均值,计算任意一个关键帧rfi与聚类中心rfk的距离d(rfi,rfk),rfk代表第k个聚类中心,其欧氏距离为:
(43)重新计算每个聚类的均值,按照运动特征数据点到新质心的距离对数据进行分组,并计算每组的均值作为新质心;当均值与原质心相等,也就是说新质心与原质心相等时算法停止计算,如果条件不满足d(rfi,rfk)<ε,则返回(42),重复执行。
步骤5具体按照以下步骤实施:
(51)训练设计的fnn作为人体姿势分类器,使用数据(rfi,gj),i=1...n,j=1...p对fnn进行训练;
(52)在训练完成的fnn基础上构建图模型,具体分析过程如下:
fnngm的参数定义为l=(ps,as,bg,brf),其中ps=[pi]1′w是先验概率矩阵,w是动作语义的数量,as=[aij]w′w是语义状态转换矩阵,
其中s={s1,...,sw}和g={g1,...,gp}分别是动作语义集和相似姿态集合;
估计fnngm的初始参数如下:基于s和g中的rfi数量,计算图形模型参数:
首先,先验概率的计算为:
其中
其次,估计语义交易可能性aij为:
其中,
第三,观测可能性
最后,计算观测可能性
其中
步骤(51)具体按照以下步骤实施:
(511)构建一个模糊神经网络模型,模糊系统使用的规则如下:
假设:
则:
其中:
其中,
同时,输出yi计算为:
(512)所述(511)构建的模糊神经网络模型分为四层:输入层、模糊层、模糊规则层和输出层;在输入层中没有计算操作,在模糊层使用公式(1)计算模糊隶属度,然后根据公式(2)得到规则推理结果,最终通过公式(3)计算输出,得到语义分类结果;
(513)使用数据(rfi,gj),i=1...n,j=1...p对模糊神经网络fnn进行训练,步骤如下:
a.误差计算
其中yd是期望输出,yc是实际输出,e=yd-yc,e是期望输出与实际输出之间的误差;
b.系数修正
其中
c.参数修正
其中
步骤6具体按照以下步骤实施:
(61)给定检测量{rf1:k},以更新隐藏状态信号s={s1:k}和g={h1:k},根据贝叶斯规则,计算p(s1):
将s0和p(s1|s0)设置为初始系统输入,根据公式(8),(9),(11)得到p(s1);
(62)预测c使用检测量更新为:
保证a输出结果在区间[0,1]中,此外,通过测量结果,滤波方程可以重新写为:
基于滤波方程公式(13),进一步得到最大可能状态路径:
最终获得语义序列最大可能性状态值:
本发明的有益效果是,本发明提出的方法分为两个阶段:系统学习和动作识别。在系统学习阶段,首先,提取运动数据集中动作的帧图像;其次,使用模糊c均值聚类算法对帧图像进行聚类获取运动的代表帧;设计一个模糊神经网络分类器来识别代表帧的运动姿态,代表帧的标记的姿态特征数据集被用作教师信号来训练模糊神经网络;最后,使用模糊神经网络图模型的概率图模型对代表帧序列进行分类。本发明的图模型是基于隐马尔可夫模型和模糊神经网络的组合。在动作识别阶段,自动提取待识别动作的代表帧特征,然后使用fnngm即模糊神经网络和图模型推理算法得到动作语义分类结果。本发明提出的方法能够更加准确、容易的进行动作识别。将本发明提出的算法与现有模型进行比较,验证该算法检索结果具有良好的精确性和有效性。
附图说明
图1是本发明的总体流程图;
图2为本发明步骤4的动作语义集和相似姿态集合的构建;
图3为本发明步骤(51)的用于识别的神经网络;
图4为本发明步骤(52)所构建的fnngm模型。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明中相关技术介绍如下:
(1)基于肤色模型手势分割技术:肤色为脸和双手区别于周围环境的最明显和简单的特征,所以通过确定准确的肤色区域阈值条件,就可以定位出人脸和双手区域。拍摄视频的图像颜色空间为rgb颜色空间,但在rgb空间人体的肤色受亮度影响相当大,使得肤色点很难从非肤色点中分离出来,同时,每个人的肤色,尤其是不同种族人的肤色都很不同,其主要是由于饱和度与亮度不同而造成的,而肤色在色度上的差异并不大。在色度空间中,hsv色彩空间采用色调h、饱和度s和亮度v三个维度来表示颜色,成功的将三个变量分别开来,所以使用h的阈值用来区分出肤色。ycbcr颜色空间将颜色的亮度用y分量区分出来,cb和cr分别表示蓝色和红色的浓度偏移量成份,所以附加上cb和cr的阈值条件共同实现肤色分割。
(2)模糊c均值聚类算法(fcm):在众多模糊聚类算法中,模糊c均值(fcm)算法应用最广泛且较成功,它通过优化目标函数得到每个样本点对所有类中心的隶属度,从而决定样本点的类属以达到自动对样本数据进行分类的目的。
(3)模糊神经网络(fnn):模糊神经网络就是具有模糊权系数或者输入信号是模糊量的神经网络。是模糊理论同神经网络相结合的产物,它汇集了神经网络与模糊理论的优点,集学习、联想、识别、信息处理于一体。
(4)四元数:四元数是由爱尔兰数学家威廉·卢云·哈密顿在1843年发现的数学概念。明确地说,四元数是复数的不可交换延伸。如把四元数的集合考虑成多维实数空间的话,四元数就代表着一个四维空间,相对于复数为二维空间。四元数都是由实数加上三个元素i、j、k组成,而且它们有如下的关系:q=xi+yj+zk+w其中满足i2=j2=k2=-1。
(5)baum-welch算法:baum-welch算法是一种对hmm模型做参数估计的方法,是em算法的一个特例。em算法包含两步:(1)expectation,计算隐变量的概率分布,并得到可观察变量与隐变量联合概率的log-likelihood在前面求得的隐变量概率分布下的期望。(2)maximization,求得使上述期望最大的新的模型参数。若达到收敛条件则退出,否则回到步骤(1)。
本发明方法如图1所示,具体按照以下步骤实施:
步骤1:使用kinect设备拍摄单目及深度视频,拍摄速度为30帧每秒,构建有n个类别的人体运动视频序列数据库dvideo=(v1,v2,...,vi,...,vn);
步骤2:提取视频vi的每帧图像,得到帧图像fi=(fi1,...,fin),其中n表示视频vi的帧数,对fij进行预处理,通过背景差分和肤色模型获取出fij中运动轮廓,通过人体骨架提取法获得运动骨架;
步骤2具体按照以下步骤实施:
(21)使用kinect获取人体运动的rgb彩色与深度图像,去除rgb彩色与深度图像噪声,并对其进行图像校正处理;
(22)根据彩色图像背景的复杂程度采用不同方法去除背景,获得前景彩色图像;
(23)基于前景彩色图像且依据肤色模型对脸部及手部进行定位并将脸部及手部定位质心作为初始获取的关节点;
(24)基于学习得到的贝叶斯分类器对彩色图像前景中的运动人体进行部件分类识别;
(25)依据分类识别结果判定肢体各刚体结构部位类别,再根据各刚体部件的链接关系确定出各关节点,依次联接各关节点形成平面人体骨架结合各个关节点深度数据将平面骨架变换成三维立体骨架。
步骤3:基于获得的帧图像fi=(fi1,...,fin)聚类获取运动序列代表性的帧rfi=(rfi1,…,rfic);所有视频运动类别所对应的代表性帧图像组成人体运动代表帧图像数据库drf={rfi},i=1,…,p,p代表数据库总运动序列数;
步骤3具体按照以下步骤实施:
(31)给定运动序列fi,使用模糊c均值fcm聚类方法生成代表帧rfi;
(32)使用四元数来呈现身体姿态,计算两帧间距离;设fi为第i帧中的运动描述符,f1和f2之间的距离计算为:
d(f1,f2)=(f1-f2)(f1-f2)t
使用聚类方法来生成c个聚类中心,选择距离聚类中心最短距离的一些帧作为代表帧,代表帧可表示为rfi={rfk}k=1:c,其中rfk对应于第k个聚类中心。
在步骤(32)中,人体运动捕获数据看作是由离散的时间点采样得到的人体运动姿态序列{x1,…,xn},每个采样点看作是一帧,其中每一帧姿态由所有关节点转角信息共同决定,所以,任意时刻,人体运动的姿态都可以表示为一个四元数矢量:q=xi+yj+zk+w(其中满足i2=j2=k2=-1,w是实数;使用n维四元数矢量来描述身体运动姿态,本发明在骨架中使用26个关节点状态信息来呈现一个身体动作,每一个关节点采用四元数来描述,其中n=26×4=104,因此得到104维四元数描述符特征向量,则任意一个关键帧可表示为:rfi=(a1,…,a104)。
步骤4:如图2所示,基于所有获得的运动姿势关键帧骨架特征训练数据的分类,首先建立动作语义集s={s1,…,sω},其中ω是通过聚类后动作语义分类的个数;然后基于关键帧运动骨架特征聚类以形成相似的运动集合g={g1,…,gq},其中q是聚类组的个数;
步骤4具体按照以下步骤实施:
(41)从获取的所有运动代表帧中任意选择q个关键帧骨架运动特征作为初始聚类中心;
(42)根据每个聚类对象的均值,计算任意一个关键帧rfi与聚类中心rfk的距离d(rfi,rfk),rfk代表第k个聚类中心,其欧氏距离为:
(43)重新计算每个聚类的均值,按照运动特征数据点到新质心的距离对数据进行分组,并计算每组的均值作为新质心;当均值与原质心相等,也就是说新质心与原质心相等时算法停止计算,如果条件不满足d(rfi,rfk)<ε,则返回(42),重复执行。
步骤5:构建一个基于概率图模型的模糊神经网络系统进行运动语义推理,来识别由每个代表帧确定的身体姿态语义,使用概率图推理来分类动作语义序列;首先训练设计的fnn作为人体姿势分类器;其次,在训练完成的fnn基础上构建图模型;
步骤5具体按照以下步骤实施:
(51)如图3所示,训练设计的fnn作为人体姿势分类器,使用数据(rfi,gj),i=1...n,j=1...p对fnn进行训练;
(511)构建一个模糊神经网络模型,模糊系统使用的规则如下:
假设:
则:
其中:
其中,
同时,输出yi计算为:
(512)所述(511)构建的模糊神经网络模型分为四层:输入层、模糊层、模糊规则层和输出层;在输入层中没有计算操作,在模糊层使用公式(1)计算模糊隶属度,然后根据公式(2)得到规则推理结果,最终通过公式(3)计算输出,得到语义分类结果;
(513)使用数据(rfi,gj),i=1...n,j=1...p对模糊神经网络fnn进行训练,步骤如下:
a.误差计算
其中yd是期望输出,yc是实际输出,e=yd-yc,e是期望输出与实际输出之间的误差;
b.系数修正
其中
c.参数修正
其中
(52)如图4所示,在训练完成的fnn基础上构建图模型,具体分析过程如下:
在模糊神经网络模型对每个代表帧确定的身体语义姿态进行识别之后,使用概率图推理对动作语义序列进行分类。首先要构建一个图模型结构,本发明中构建的fnngm模型图包括三层:测量信号层、运动姿势层和动作语义层。最低层是测量信号层,从最低层输入代表帧序列(rf1,...,rfk)。中间层是运动姿势层,在这一层呈现由fnn推断的离散姿态状态信号(g1,...gk)。最高层是动作语义层,根据中间层和最低层的信息,在该层中计算最终动作语义(s1,...,sk)。
fnngm的参数定义为l=(ps,as,bg,brf),其中ps=[pi]1′w是先验概率矩阵,w是动作语义的数量,as=[aij]w′w是语义状态转换矩阵,
其中s={s1,...,sw}和g={g1,...,gp}分别是动作语义集和相似姿态集合;
估计fnngm的初始参数如下:基于s和g中的rfi数量,计算图形模型参数:
首先,先验概率的计算为:
其中
其次,估计语义交易可能性aij为:
其中,
第三,观测可能性
最后,计算观测可能性
其中
基于初始参数估计,进一步使用baum-welch算法优化参数,对数似然值对应于参数学习的全局收敛性能,当对数似然值变得稳定时,意味着参数收敛到最优值。
步骤6:基于步骤5中构建的fnngm图模型结构,进行图模型推理,对动作语义序列进行分类;将{rf1:k}作为一个测量的图模型;系统状态序列为s={s1:k}和g={g1:k},基于图模型推理的对动作识别进行描述;
步骤6具体按照以下步骤实施:
(61)给定检测量{rf1:k},以更新隐藏状态信号s={s1:k}和g={h1:k},根据贝叶斯规则,计算p(s1):
将s0和p(s1|s0)设置为初始系统输入,根据公式(8),(9),(11)得到p(s1);
(62)预测c使用检测量更新为:
保证a输出结果在区间[0,1]中,此外,通过测量结果,滤波方程可以重新写为:
基于滤波方程公式(13),进一步得到最大可能状态路径:
最终获得语义序列最大可能性状态值:
另外,使用fnngm进行动作识别的算法如下:
输入:待识别动作
输出:识别结果:s*1:k;
1.获取训练动作数据集中的所有代表帧;
2.使用fcm自动提取代表帧特征;
3.获取动作语义集合s={s1,...,sw},相似姿势集合g={g1,...,gp}。
4.基于代表帧特征数据集,构建fnngm模型;
5.基于集合s和g,根据公式7-10获取fnngm的参数:λ={
πs,as,bg,brf},并使用baum-welch算法优化参数;
6.输入待识别动作,使用fcm提取代表帧{rf1:k};
7.设定先验分布:p(s0);
8.fort=1:k
9.根据贝叶斯规则,使用公式11计算p(st);
10.根据方程12计算p(st|gt),p(st|rft);
11.根据方程13计算p(st|g1:t,rf1:t);
12.根据方程14计算maxsp(s1:t|g1:t,rf1:t);
13.endfor
14.输出最大概率序列作为识别结果:s*1:k=argmaxsp(s1:t|g1:t,rf1:t)。
- 还没有人留言评论。精彩留言会获得点赞!