一种基于语义的特定任务文本关键词提取方法与流程
本发明属于自然语言处理领域,涉及信息抽取技术,具体是一种基于语义的特定任务文本关键词提取方法。
背景技术:
随着社会化媒体的飞速发展,人们每时每刻都接收和处理来自于物理世界和信息世界的大量信息。但是,这些信息数量大、结构复杂以及无意义信息多等特点,导致人们不可能对每一条接收到的信息都进行加工和处理,识别其中有价值的部分。因此,如何从文本中获取有用的信息是实现快速、准确地处理信息的关键。
在现实世界中,关键词是对有用信息最直观的表示,所以如何从文本中获取人们关注的关键词成为当前迫切需要解决的问题。从文本中获取人们关注的关键词,一方面可以帮助人们快速地理解信息的内容,另一方面还可以为文本挖掘、自然语言处理、知识工程等领域提供重要的技术支持,具有非常广泛的应用。例如,在营销领域,从顾客对某个产品的评论中提取关键词,可以揭示顾客所关注的方面,为生产更契合顾客需求的产品提供必要的支撑;在舆情监控领域,从网上言论中提取关键词,可以掌握舆情发展的最新态势,为政府部门的舆论监控与引导提供必要的支持。
技术实现要素:
本发明针对上述问题,提出了一种基于语义的特定任务文本关键词提取方法;考虑待提取关键词文本与特定任务的语义关系,通过计算语义相似度来衡量候选关键词与特定任务的语义相关度,再考虑待提取关键词文本的结构特征,以词语网络图的形式表示文本的词语结构,最后利用网络重要度算法,结合词语的文本结构特征和与特定任务的语义特征,从词语网络图中提取重要度高的词语。
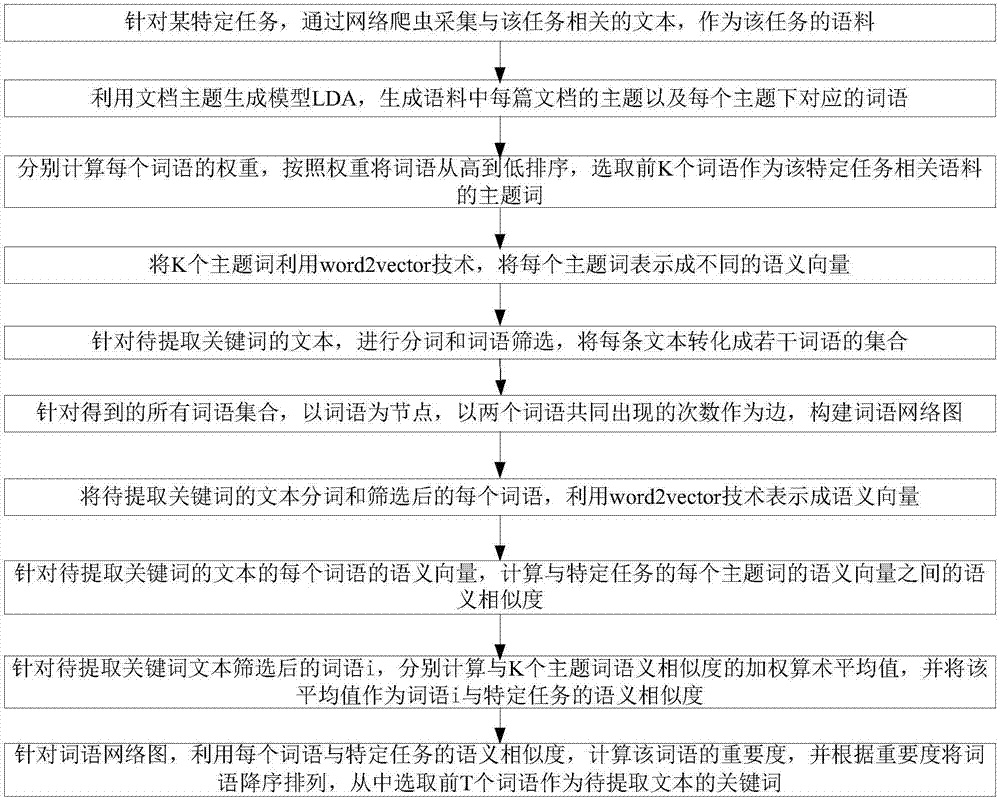
具体步骤如下:
步骤一、针对某特定任务,通过网络爬虫采集与该任务相关的文本,作为该任务的语料;
步骤二、利用文档主题生成模型lda,生成语料中每篇文档的主题以及每个主题下对应的词语;
步骤三、分别计算每个词语的权重,按照权重将词语从高到低排序,选取前k个词语作为该特定任务相关语料的主题词;
其中,weightr表示词语r的权重;wtdr表示通过lda模型计算出的词语r在文档d中的代表主题的概率,c表示词语r出现的文档数量。
步骤四、将k个主题词利用word2vector技术,将每个主题词表示成不同的语义向量;
步骤五、针对待提取关键词的文本,进行分词和词语筛选,将每条文本转化成若干词语的集合;
分词的过程中对每一个词语进行词性标注;
词语筛选包括对分词后的词语进行词性筛选和词频筛选;
步骤六、针对得到的所有词语集合,以词语为节点,以两个词语共同出现的次数作为边,构建词语网络图;
步骤七、将待提取关键词的文本分词和筛选后的每个词语,利用word2vector技术表示成语义向量;
步骤八、针对待提取关键词的文本的每个词语的语义向量,计算与特定任务的每个主题词的语义向量之间的语义相似度。
两个词语向量di和dj之间的语义相似度计算公式如下:
di是指待提取关键词的文本筛选后的词语i表达成的词语语义向量;dj是指特定任务的词语j表达成的词语语义向量;wik表示词语语义向量di中第k个元素的值,wjk表示词语语义向量dj中第k个元素的值,n代表语义向量的维度,即包含的元素个数。
步骤九、针对待提取关键词文本筛选后的词语i,分别计算与k个主题词语义相似度的加权算术平均值,并将该平均值作为词语i与特定任务的语义相似度;
si-task表示待提取关键词的文本筛选后的词语i与该特定任务的语义相似度;si-j表示词语i与k个主题词中的第j个主题词的语义相似度;
步骤十、针对词语网络图,利用每个词语与特定任务的语义相似度,计算该词语的重要度,并根据重要度将词语降序排列,从中选取前t个词语作为待提取文本的关键词。
重要度用每个词语的权重来体现;计算公式如下:
ws(vi)表示节点vi的权重,{vm}i表示与节点vi有边相连的节点集合,d表示阻尼系数。fim表示节点vi和vm之间边的权重,ws(vm)表示节点vm的权重。z表示归一化因子,表示与节点vi相连的边的权重之和,计算公式如下所示:
本发明的优点在于:
1)、一种基于语义的特定任务文本关键词提取方法,利用外部语料对特定任务主题词进行语义扩充,实现对特定任务主题词语义特征的刻画,并用语义向量表示词语的语义特征,再综合考虑词语的语义特征和主题特征提取文本关键词。
2)、一种基于语义的特定任务文本关键词提取方法,既考虑了文本关键词与任务的契合关系,又考虑了待提取关键词文本的内部结构。一方面,通过计算候选词语与特定任务主题词的语义向量相似度,实现对候选关键词和任务主题词的语义相似度的刻画。另一方面,根据词语间的共现关系,考虑文本内部结构对候选词语权重的影响,在计算候选词语权重时加入与该节点共同出现的词语的权重。
附图说明
图1为本发明一种基于语义的特定任务文本关键词提取方法的原理图;
图2为本发明一种基于语义的特定任务文本关键词提取方法的流程图。
具体实施例
下面结合附图对本发明的具体实施方法进行详细说明。
本发明一种基于语义的特定任务文本关键词提取方法,首先考虑待提取关键词文本的语义特征,计算文本与特定任务主题词的语义相似度,再考虑待提取关键词文本的结构特征,构建词语网络图,最后利用搜索引擎网页排序技术计算每一个词语的重要度,并根据重要度提取网络图中重要度较高的词语。
如图1所示,具体为:首先,利用搜索引擎搜索某一特定任务相关语料,从与特定任务相关的语料中提取主题词,并利用语义表示技术,将主题词转换成语义向量;其次,利用分词工具对待提取关键词的文本进行预处理;以词语为节点,构建词语网络图,再利用语义表示技术,计算文本与特定任务的主题词之间的语义相似度。再基于词语相似度,利用搜索引擎网页排序技术计算每个词语的重要度,并根据重要度提取词语网络图中的重要词语。
如图2所示,具体实施步骤如下:
步骤一:针对某特定任务,通过网络爬虫采集与该任务相关的文本,作为该任务的语料;
特定任务相关的语料是在关键词提取任务开始之前通过网络爬虫技术采集到的。例如,对于“提取消费倾向的关键词”的任务,需要从互联网或者其他渠道采集与“消费倾向”相关的文本,作为与该任务相关的语料。
步骤二、利用文档主题生成模型lda,生成语料中每篇文档的主题以及每个主题下对应的词语;
针对特定任务相关的语料,利用lda(latentdirichletallocation)文档主题生成模型,生成每篇文档的n个主题以及每个主题下对应的m个词语。
在本发明中,使用gensim中的lda工具进行主题词的提取,根据以下网址提取主题词,http://radimrehurek.com/gensim/models/ldamodel.html;其中,文档主题数n取10,每个主题下对应的词语数m取10。每篇文档都通过lda算法表示成了由n×m个词语组成的集合。
步骤三、分别计算每个词语的权重,按照权重将词语从高到低排序,选取前k个词语作为该特定任务相关语料的主题词;
其中,weightr表示词语r的权重,wtdr表示通过lda模型计算出的词语r在文档d中的代表主题的概率,c表示词语r出现的文档数量。
本发明中k取10。
步骤四、将k个主题词利用word2vector技术,将每个主题词表示成不同的语义向量;
本步骤使用gensim中的word2vector工具将词语转化成语义向量,参考具体网址如下:http://radimrehurek.com/gensim/models/word2vec.html。
步骤五、针对待提取关键词的文本,进行预处理,将每条文本转化成若干词语的集合;
预处理包括以下两个方面的内容
首先,对待提取关键词的文本进行分词。分词的目的是为了将待提取关键词的文本转化成一个个词语。根据汉语语言的特点,能反映文本语义信息的词语都是实词。因此,在分词的过程中需要对每一个词语进行词性标注。
然后,对分词之后的结果进行两种特殊处理,一种是词性筛选,另一种是词频筛选。
词性筛选是指将分词结果中的名词、形容词、动词保留下来,将其他词性的词语去掉。词频筛选是指将分词结果中的低频词和高频词去掉。
低频词很可能是只在少数新闻评论中出现的,不具有代表性。高频词有两种可能:一种是大部分新闻评论都出现的词语;另一类是错误分词以后产生的分词碎片。
进行词性和词频筛选之后可以提高本发明处理数据的精度。
步骤六、针对得到的所有词语集合,以词语为节点,以两个词语共同出现的次数作为边,构建词语网络图;
将待提取关键词的文本转化成词语网络图,对于待提取关键词的文本,本步骤利用一个长度为l的滑动窗口,从第一个词语开始,向后滑动。滑动窗口的长度是指其覆盖的词语的数量,本发明中l取4。若两个词语共同出现在一个滑动窗口中,则这两个词语共同出现的次数加1。
例如,一个待提取关键词的文本经过预处理后得到的结果为“高速公路,司机,超速,行驶,受到,交警,处罚”,基于上述结果构建词语网络图。对于结果中的每个词语,在网络图中都是一个节点。利用长度l=4的滑动窗口,从第一个词语“高速公路”开始,滑动窗口覆盖“高速公路,司机,超速,行驶”这4个词语,则这四个词语中每两个词语的共同出现次数加1。然后滑动窗口向后滑动1个词语,覆盖“司机,超速,行驶,受到”,则这四个词语中每两个词语的共同出现次数加1。以此类推,直到滑动窗口到达文档最后一个词语,则停止计算。
步骤七、将待提取关键词的文本分词和筛选后的每个词语,利用word2vector技术表示成语义向量;
本步骤仍然使用gensim中的word2vector工具将词语转化成语义向量,参考网址如下:http://radimrehurek.com/gensim/models/word2vec.html。
步骤八、针对待提取关键词的文本的每个词语的语义向量,计算与特定任务的每类主题词的语义向量之间的语义相似度。
本发明考虑提取的关键词与特定任务的语义关系,首先利用语义表示技术将候选关键词和特定任务的主题词转化成语义向量,然后计算候选关键词和特定任务主题词语义向量之间余弦相似度,用余弦相似度作为候选关键词与特定任务的语义相似度,以实现与特定任务相关的关键词提取。
余弦相似度是信息检索中常用的相似度的计算方式,假如有两个词语i和j,词语i表达成文件向量di=(wi1,wi2,...,win),词语j表达成dj=(wj1,wj2,...,wjn),则这两个词语的余弦相似度计算公式为:
di是指待提取关键词的文本筛选后的词语i表达成的词语语义向量;dj是指特定任务的词语j表达成的词语语义向量;wik表示词语语义向量di中第k个元素的值,wjk表示词语语义向量dj中第k个元素的值,n代表语义向量的维度,即包含的元素个数。
余弦相似度最小值为0,最大值为1,其几何意义是计算两文件或词语向量在高纬度空间中的夹角,夹角越小,余弦相似度越大(角度为0°时,相似度为1);夹角越大,余弦相似度越小(角度为90°时,相似度为0)。
对于待提取关键词的文本预处理后的每个词语,本步骤利用余弦相似度计算公式计算这个词语与特定任务的每个主题词之间的语义相似度。例如,特定任务的10个主题词,对于待提取关键词的文本预处理后的每个词语,本步骤需要分别计算该词语与特定任务的10个主题词的语义相似度,得到10个余弦相似度的值。
步骤九、针对待提取关键词文本筛选后的词语i,分别计算与k类主题词语义相似度的加权算术平均值,并将该平均值作为词语i与特定任务的语义相似度;
计算公式如下所示:
si-task表示待提取关键词的文本筛选后的词语i与该特定任务的语义相似度;si-j表示词语i与k个主题词中的第j个主题词的语义相似度;weightj表示第j个主题词的权重;k表示特定任务的主题词的数量。
步骤十、针对词语网络图,利用每个词语与特定任务的语义相似度,计算该词语的重要度,并根据重要度将词语降序排列,从中选取前t个词语作为待提取文本的关键词。
提取构建的词语网络图中的重要词语,首先计算词语网络图中每个词语的重要度,并根据重要度对词语进行降序排列,从中选出重要度较高的t个词语作为待提取文本的关键词,本发明中t取10:
本步骤中计算词语网络图中每个词语的重要度的方法是利用搜索引擎网页排序算法—pagerank算法基础上进行了改进,计算网络图中词语的重要度,并根据重要度提取关键词。具体步骤如下:
根据词语网络图,利用如下公式对每个词语的权重进行迭代计算。
ws(vi)表示节点vi的权重,{vm}i表示与节点vi有边相连的节点集合,d表示阻尼系数,取值范围为0到1,代表从图中某一特定点指向其他任意点的概率,一般取值为0.85。fim表示节点vi和vm之间边的权重,ws(vm)表示节点vm的权重。z表示归一化因子,表示与节点vi相连的边的权重之和,计算公式如下所示:
本发明使用networkx中的pagerank计算包迭代计算词语网络图中的节点权重,参考网址如下:http://networkx.github.io/。
本发明利用语义表示技术和搜索引擎网页排序技术,综合考虑词语在文本中的语义特征和结构特征,适用于面向特定任务的文本关键词提取,实现从文本中获取重要信息的功能,为文本挖掘、自然语言处理、知识工程等领域提供重要的技术支持。
- 还没有人留言评论。精彩留言会获得点赞!