基于几何代数的视频分析处理的统一模型建模方法与装置与流程
本发明属于视频图像技术领域,尤其涉及一种基于几何代数的视频分析处理的统一模型建模方法与装置。
背景技术:
时空兴趣点是视频的一类局部不变特征,由于其具有独特性和可描述性而被应用于视频行为识别上。
然而,现有的大多数时空兴趣点检测算法通过增加时间轴对二维图像的局部特征检测算法进行扩展,导致只能捕捉到视频中模糊的运动信息,所提取到的时空兴趣点仅仅是视频三维立体中外观信息变化显著的点,但没能体现时域上丰富的运动变化,其抗变换能力、抗干扰能力和计算的高效性等方面表现较差。此外,现有的大多数时空兴趣点检测算法都是基于传统欧式几何模型进行的,所谓的传统欧式几何模型就是指我们常见的立体模型——xyz三个维度,它将视频看成就是一个立方体,xyt相当于xyz,所以将时间轴t跟空间中的xy相同对待的。由于视频中存在表观信息(即包括像素点、边缘、纹理这些信息)、运动信息等不同维数的几何体,传统欧式几何模型无法对这些具有不同维数的几何体以及它们之间的关系建立统一的模型进行分析与处理。此外,我们知道视频的空间域和时间域是有区别的,二者之间存在时空相关性,不能同等对待处理,简单地将二维图像的特征检测算法扩展到视频上割裂了视频像素点在时空域上的相关性;而且只能捕捉到视频模糊的运动信息,只有包含清晰的运动信息的兴趣点才能为视频行为识别提供必要的信息。
那么,若需要一种时空兴趣点检测算法,能充分反映视频的时空域相关性,进而真正地提取到在空域上包含独特的表观信息同时在时域上体现清晰的运动变化的兴趣点,需要先建立一个为空间中不同维数的几何体以及它们之间的关系提供统一数学描述的模型。
技术实现要素:
本发明提供一种基于几何代数的视频分析处理的统一模型建模方法与装置,旨在利用该建模方法对视频的表观信息和运动信息这些具有不同维数的几何体以及它们之间的关系建立统一的模型,来对视频进行分析和处理。
本发明提供了一种基于几何代数的视频分析处理的统一模型建模方法,所述建模方法包括:
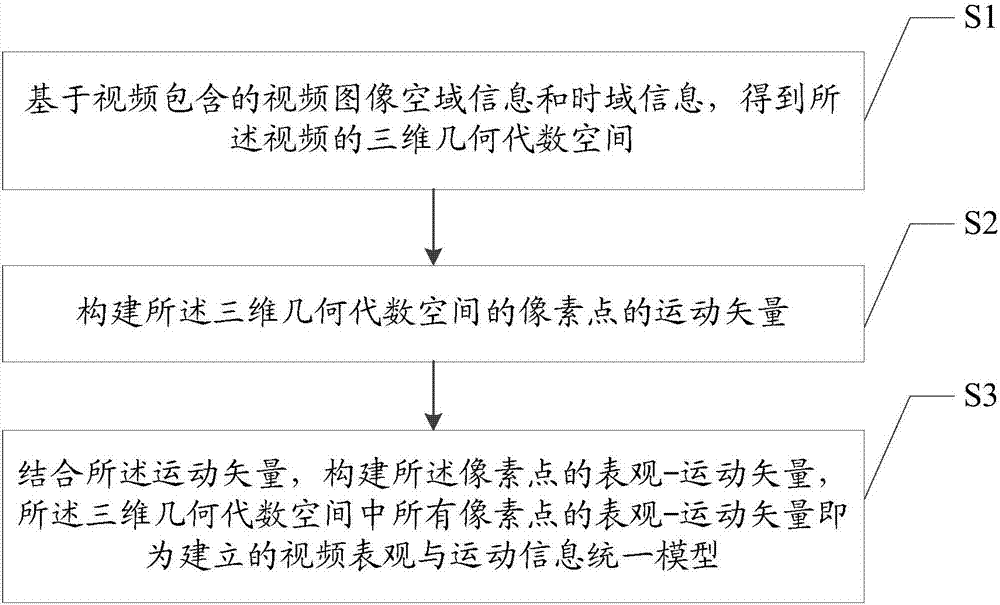
基于视频包含的视频图像空域信息和时域信息,得到所述视频的三维几何代数空间;
构建所述三维几何代数空间的像素点的运动矢量;
结合所述运动矢量,构建所述像素点的表观-运动矢量,所述三维几何代数空间中所有像素点的表观-运动矢量即为建立的视频表观与运动信息统一模型。
进一步地,所述构建所述三维几何代数空间的像素点的运动矢量,包括:
构建三维几何代数空间
vp=pr-p;
其中,p为所述三维几何代数空间
进一步地,所述像素点的表观-运动矢量记为f′(p),
f′(p)=f(p)+vp;
其中,vp表示视频图像中p处的像素点的运动矢量,f(p)表示视频图像中p处的像素点的像素值。
本发明还提供了一种基于几何代数的视频分析处理的统一模型建模装置,所述建模装置包括:
预处理模块,用于基于视频包含的视频图像空域信息和时域信息,得到所述视频的三维几何代数空间;
运动矢量构建模块,用于构建所述三维几何代数空间的像素点的运动矢量;
表观-运动矢量构建模块,用于结合所述运动矢量构建所述像素点的表观-运动矢量,所述三维几何代数空间中所有像素点的表观-运动矢量即为建立的视频表观与运动信息统一模型。
进一步地,所述运动矢量构建模块具体用于:
构建三维几何代数空间
vp=pr-p;
其中,p为所述三维几何代数空间
进一步地,所述像素点的表观-运动矢量记为f′(p),
f′(p)=f(p)+vp;
其中,vp表示视频图像中p处的像素点的运动矢量,f(p)表示视频图像中p处的像素点的像素值。
本发明与现有技术相比,有益效果在于:本发明提供了一种基于几何代数的视频分析处理的统一模型建模方法与装置,先构建三维几何代数空间的像素点的运动矢量,再结合所述运动矢量构建像素点的表观-运动矢量,三维几何代数空间中所有像素点的表观-运动矢量即为建立的视频表观与运动信息统一模型;本发明利用几何代数这一简单高效的数学工具,对视频的表观信息与运动信息这些具有不同维数的几何体以及它们之间的关系建立了统一的模型,以便基于该模型提出一种时空兴趣点的检测算法,来提取在空域上包含独特的表观信息同时在时域上体现清晰的运动变化的兴趣点。
附图说明
图1是本发明实施例提供的一种基于几何代数的视频分析处理的统一模型建模方法的流程示意图;
图2是本发明实施例提供的一种基于几何代数的视频分析处理的统一模型建模装置的模块示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
由于现有技术中存在无法对视频的表观信息与运动信息这些具有不同维数的几何体以及它们之间的关系建立统一模型的技术问题。
为了解决上述技术问题,本发明提出一种基于几何代数的视频分析处理的统一模型建模方法与装置,先构建三维几何代数空间的像素点的运动矢量,再结合所述运动矢量,构建所述像素点的表观-运动矢量,该表观-运动矢量即为建立的视频表观与运动信息统一模型;通过建立该模型,可以将表观信息和运动信息集成在一个几何代数矢量中,从而保证视频中的表观信息和运动信息能被有效地利用和分析。
请参阅图1,为本发明实施例中基于几何代数的视频分析处理的统一模型建模方法的流程示意图,该建模方法包括:
步骤s1,基于视频包含的视频图像空域信息和时域信息,得到所述视频的三维几何代数空间;
在本发明实施例中,建模是在一个视频中进行,该视频中包含的视频图像(视频帧)序列可以表示为一个三维立体结构,包含空域信息和时域信息,需要说明的是,视频中的表观信息和运动信息均可以用三维立体结构中的几何代数表示。鉴于几何(clifford)代数对矢量数据和几何信息的运算的简洁性,本文采用三维几何代数作为数学框架对视频进行建模,下面将阐述几何代数框架下的视频图像序列的表示模型。
设r3是视频包含的视频图像序列的空域信息和时域信息组成的三维欧式空间,它的规范正交基为{e1,e2,e3},那么这些规范正交基通过几何张成上r3的几何代数空间为
{1,e1,e2,e3,e1∧e2,e2∧e3,e1∧e3,e1∧e2∧e3}(1)
其中,“∧”表示几何代数外积计算的符号,e1∧e2,e2∧e3及e1∧e3是由三个正交基e1、e2及e3得到的三个独立的二重外积,这三个二重外积几何意义上分别表示了
则视频序列f可以表示为:
f=f(p)(2)
其中,
设
p1p2=p1·p2+p1∧p2(3)
其中,·表示内积,∧表示外积。它表示两个矢量的几何积是由内积(p1·p2)和外积(p1∧p2)之和组成。
在
△p=p1-p2=(x1-x2)e1+(y1-y2)e2+(t1-t2)e3(4)
它表示一个从p2指向p1的矢量,它不仅是两个像素点距离的度量,而且也可以反映像素点在视频序列中的运动情况。
以上即为本发明实施例中视频的三维几何代数空间的介绍。
步骤s2,构建所述三维几何代数空间的像素点的运动矢量;
具体地,构建三维几何代数空间
vp=pr-p;(5)
其中,设
其中,
步骤s3,结合所述运动矢量,构建所述像素点的表观-运动矢量,所述三维几何代数空间中所有像素点的表观-运动矢量即为建立的视频表观与运动信息统一模型。
所述像素点的表观-运动矢量记为f′(p),
f′(p)=f(p)+vp(6)
其中,vp表示视频图像中p处的像素点的运动矢量,f(p)表示视频图像中p处的像素点的表观值,在本发明实施例中,f(p)表示视频图像中p处的像素点的像素值。
新定义的f′(p)是一个既含有标量信息又含有矢量信息的几何代数矢量,不仅反映了表观信息,而且还反映了运动方向和运动速度的变化情况。
基于上面的定义,视频表观与运动信息统一模型umam(unifiedmodelofappearanceandmotion),简记为f′,构建如下:
f′=f′(p)(7)
其中,f′(p)是像素点
请参阅图2,为本发明实施例中基于几何代数的视频分析处理的统一模型建模装置的模块示意图,该建模装置包括:
预处理模块1,用于基于视频包含的视频图像空域信息和时域信息,得到所述视频的三维几何代数空间;
运动矢量构建模块2,用于构建所述三维几何代数空间的像素点的运动矢量;
具体地,所述运动矢量构建模块2,用于构建三维几何代数空间g3的当前帧视频图像中p处的像素点指向下一帧视频图像中pr处的像素点的运动矢量vp,所述运动矢量vp为:
vp=pr-p;
其中,p为所述三维几何代数空间
表观-运动矢量构建模块3,用于结合所述运动矢量构建所述像素点的表观-运动矢量,所述三维几何代数空间中所有像素点的表观-运动矢量即为建立的视频表观与运动信息统一模型。
具体地,所述像素点的表观-运动矢量记为f′(p),
f′(p)=f(p)+vp;
其中,vp表示视频图像中p处的像素点的运动矢量,f(p)表示视频图像中p处的像素点的像素值。
本发明提供了一种基于几何代数的视频分析处理的统一模型建模方法与装置,由于视频中含有丰富的表观信息和运动信息,为了能有效地利用好这两种重要的视频信息,本发明是在几何代数基本模型的基础上建立的视频表观与运动信息统一模型(umam),该模型将表观信息和运动信息集成在一个几何代数矢量中,从而保证视频中的表观信息和运动信息能被有效地利用和分析。本发明利用几何代数这一简单高效的数学工具,对视频的表观信息与运动信息这些具有不同维数的几何体以及它们之间的关系建立了统一的模型,以便基于该模型提出一种时空兴趣点的检测算法,来提取在空域上包含独特的表观信息同时在时域上体现清晰的运动变化的兴趣点。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!