一种基于神经网络概率消歧的网络文本命名实体识别方法与流程
本发明涉及网络文本的处理及分析,尤其涉及一种基于神经网络概率消歧的网络文本命名实体识别的方法。
背景技术:
网络使得信息的采集、传播的速度和规模达到空前的水平,实现了全球的信息共享与交互,它已经成为信息社会必不可少的基础设施。现代通信和传播技术,大大提高了信息传播的速度和广度。但与之俱来的问题和“副作用”是:汹涌而来的信息有时使人无所适从,从浩如烟海的信息海洋中迅速而准确地获取自己最需要的信息,变得非常困难。如何从海量的网络文本中分析出互联网用户所关注的人物、地点、机构等命名实体,成为网上营销、群体情感分析等各种上层应用提供重要的支持信息。这使得面向网络文本的命名实体识别成为网络数据处理与分析中的一项重要的核心技术。
人们处理命名实体识别的方法研究主要分为两类,基于规则的方法(rule-based)和基于统计的方法(statistic-based)。随着机器学习理论的不断完善和计算性能的极大提高,基于统计学的方法更加受到人们青睐。
目前,命名实体识别应用的统计模型方法主要包括:隐马尔可夫模型、决策树、最大熵模型、支持向量机、条件随机场以及人工神经网络。人工神经网络在命名实体识别方面可以的到比条件随机场、最大熵模型等模型取得更好的结果,但实用仍以条件随机场、最大熵模型为主,如专利号cn201310182978.x使用条件随机场并结合命名实体库提出了对微博文本的命名实体识别方法及装置、专利号cn200710098635.x提出了一种利用字特征使用最大熵模型建模的命名实体识别方法。人工神经网络难以实用的原因在于人工神经网络在命名实体识别领域常需要将词转化成词向量空间中的向量,因此对于新生词汇无法得到对应的向量,所以无法得到大规模的实际应用。
基于上述现状,针对网络文本的命名实体识别主要存在以下问题:第一,网络文本因存在大量网络词汇、新生词汇、错别字,无法训练出包含所有词的词向量空间以训练神经网络。第二,网络文本存在的语言形式任意、语法结构不规范、错别字多等现象导致其命名实体识别准确率下降。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供一种增量提取词特征而不需要重新训练神经网络、同时概率消歧识别的基于神经网络概率消歧的网络文本命名实体识别方法,该方法通过训练神经网络,获取神经网络对词语所属命名实体类型的预测概率矩阵,对神经网络输出的预测矩阵再以概率模型进行消歧,提高了网络文本命名实体识别的准确性和准确率。
技术方案:为实现上述目的,本发明采用的技术方案为:
一种基于神经网络概率消歧的网络文本命名实体识别方法,将无标签语料分词,利用word2vec提取词向量,将样本语料转换成词特征矩阵并窗口化,构建深度神经网络进行训练,在神经网络的输出层加入softmax函数做归一化处理,得到每个词对应命名实体类别的概率矩阵。将概率矩阵重新窗口化,利用条件随机场模型进行消歧,得到最后的命名实体标注。
具体包括以下步骤:
步骤1,通过网页爬虫获取无标签语料,从语料库获取有命名实体标注的样本语料,利用自然语言工具对无标签语料进行分词。
步骤2,对已分词好的无标签语料和样本语料通过word2vec工具进行词向量空间的训练。
步骤3,将样本语料中的文本按照已训练的word2vec模型转换成代表词特征的词向量,并对词向量窗口化,将窗口w乘词向量长度d的二维矩阵作为神经网络的输入。将样本语料中的标签转成one-hot形式作为神经网络的输出。神经网络的输出层采用softmax函数进行归一化,使神经网络的分类结果为词汇属于非命名实体及各类命名实体的概率,调整神经网络中的结构、深度、节点数、步长、激活函数、初始值参数以及选取激活函数训练神经网络。
步骤4,将神经网络输出的预测矩阵重新窗口化,将待标注词的上下文预测信息作为条件随机场模型中待标注词的实际分类的关联点,根据训练语料利用em算法,计算出各边的期望值,训练出对应的条件随机场模型。
步骤5,识别时,首先将待识别文本按照已训练的word2vec模型转换成代表词特征的词向量,若word2vec模型中不包含对应的训练词汇,则采用增量学习、获取词向量、回溯词向量空间的方法将该词转换为词向量,并对词向量窗口化,将窗口w乘词向量长度d的二维矩阵作为神经网络的输入。然后将神经网络得到的预测矩阵重新窗口化放入训练好的条件随机场模型中进行消歧,获得待识别文本中最终的命名实体标注。
优选的:所述word2vec工具的参数如下:词向量长度选择200,迭代次数25次,初始步长0.025,最小步长0.0001,选用cbow模型。
优选的:所述神经网络的参数如下:隐藏层2层,隐藏节点数150个,步长0.01,batchsize选取40,激活函数使用sigmoid函数。
优选的:将样本语料中的标签转成one-hot形式的方法:将样本语料中的”/o”、”/n”、”/p”标签相应的转化为命名实体标签”/org-b”、”/org-i”、”/per-b”、”/per-i”、”/loc-b”、”/loc-i”,在转换成one-hot的形式。
优选的:词向量窗口化的窗口大小为5。
优选的:神经网络训练时,从样本数据中抽取十分之一的词汇不参与神经网络的训练,作为神经网络的衡量标准。
本发明相比现有技术,具有以下有益效果:
可以增量提取出不需要重新训练神经网络的词向量,利用神经网络预测并用概率模型消歧,使得该方法在网络文本的命名实体识别中拥有更好的实用性、准确性和准确率。在网络文本的命名实体识别任务中,本发明根据其存在网络词汇、新生词汇的特性,提供了一种不改变神经网络结构的词向量增量学习方法,为应对网络文本中语法结构不规范、错别字多的问题,采用了概率消歧的方法。因此本发明的方法在网络文本命名实体识别任务中可产生较高的准确率。
附图说明
图1是根据本发明训练一个基于神经网络概率消歧的网络文本命名实体识别装置的流程图。
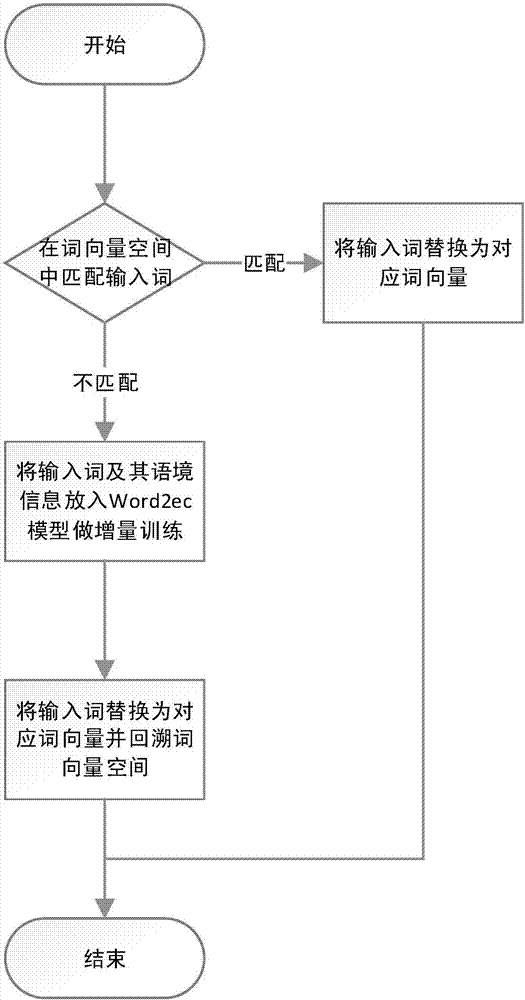
图2是根据本发明将词转化为词特征的流程图。
图3是根据本发明文本处理以及神经网络结构的示意图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
一种基于神经网络概率消歧的网络文本命名实体识别方法,将无标签语料分词,利用word2vec提取词向量,将样本语料转换成词特征矩阵并窗口化,构建深度神经网络进行训练,在神经网络的输出层加入softmax函数做归一化处理,得到每个词对应命名实体类别的概率矩阵。将概率矩阵重新窗口化,利用条件随机场模型进行消歧,得到最后的命名实体标注。
具体包括以下步骤:
步骤1,通过网页爬虫无标签网络文本,并从各语料库下载有命名实体标注的语料作为样本语料,利用自然语言工具对无标签语料进行分词。
步骤2,对已分词好的无标签语料和样本语料通过word2vec工具进行词向量空间的训练。
步骤3,将样本语料中的文本按照已训练的word2vec模型转换成代表词特征的词向量,作为神经网络的输入。将样本语料中的标签转成one-hot形式作为神经网络的输出,因为在文本处理任务中,一个命名实体可能被分割成多个词汇,所以为了保证识别出命名实体具完整性,标注形式采用iob模式进行标注。
词汇为何类命名实体不能仅凭词汇本身判定,还需要依靠词汇所处上下文信息决定,因此在建立神经网络时,我们引入窗口的概念,即在判断词汇的时候,将词汇及其固定长度上下文的特征信息都作为神经网络的输入,神经网络的输入不再是词特征向量的长度d,而是窗口w乘词特征长度d的二维矩阵。
神经网络的输出层采用softmax函数进行归一化,使神经网络的分类结果为词汇属于非命名实体及各类命名实体的概率。调整神经网络中的结构、深度、节点数、步长、激活函数、初始值参数以及选取激活函数训练神经网络。
步骤4,将神经网络输出的预测矩阵重新窗口化,将待标注词的上下文预测信息作为条件随机场模型中待标注词的实际分类的关联点,根据训练语料利用em算法,计算出各边的期望值,训练出对应的条件随机场模型。
步骤5,识别时,首先将待识别文本按照已训练的word2vec模型转换成代表词特征的词向量,若word2vec模型中不包含对应的训练词汇,则采用增量学习、获取词向量、回溯词向量空间的方法将该词转换为词向量。
(1)将待转换词汇在已训练的词向量空间中匹配。
(2)若待转换词汇在词向量空间中能够匹配,则直接将词汇转换成对应词向量。
(3)若word2vec模型中不包含对应词汇,则备份词向量空间,防止增量学习产生的词空间偏移导致神经网络模型精度的下降,载入word2vec模型,获取不匹配词汇所在句子获取不匹配词汇所在句子,将其放入word2vec模型中进行增量训练,并获取词汇的词向量,利用备份的词向量空间,回溯模型。
对词向量窗口化,将窗口w乘词向量长度d的二维矩阵作为神经网络的输入。然后将神经网络得到的预测矩阵重新窗口化放入训练好的条件随机场模型中进行消歧,获得待识别文本中最终的命名实体标注。
实例
从搜狗新闻网站爬虫网络文本,从数据堂语料库下载有命名实体语料作为样本语料,利用自然语言工具对爬虫网络文本进行分词,将分好词的语料与样本语料利用python中的gensim包通过word2vec模型进行词向量空间的训练,具体参数如下,词向量长度选择200,迭代次数25次,初始步长0.025,最小步长0.0001,选用cbow模型。
将样本语料的文本按照已训练的word2vec模型转换成代表词特征的词向量,若word2vec模型中不包含对应的训练词汇,则采用增量学习、获取词向量、回溯词向量空间的方法将该词转换为词向量。作为每个词的特征。将数据堂提供样本语料中的”/o”、”/n”、”/p”等标签相应的转化为命名实体标签”/org-b”、”/org-i”、”/per-b”、”/per-i”、”/loc-b”、”/loc-i”等,并转换成one-hot的形式作为神经网络的输出。
设定窗口大小为5,即在考虑当前词的命名实体类别时,将其本身和前后各两个词的词特征作为神经网络的输入,神经网络的输入为batchsize*1000的向量,从样本数据中抽取十分之一的词汇不参与神经网络的训练,作为神经网络的衡量标准,神经网络的输出层采用softmax函数进行归一化,使神经网络的分类结果为词汇属于非命名实体及各类命名实体的概率,暂时取概率最大值作为最终分类结果。调整神经网络中的结构、深度、节点数、步长、激活函数、初始值等参数,使神经网络取得较为良好的精确度,最终具体参数如下,隐藏层2层,隐藏节点数150个,步长0.01,batchsize选取40,激活函数使用sigmoid时可以产生良好的分类效果,准确度可以达到99.83%,最具代表性的人名、地名、机构名的f值可以达到93.4%、84.2%、80.4%。
将神经网络输出的预测矩阵取概率最大值作为最终分类结果的步骤移除,直接将概率矩阵重新窗口化,将待标注词的上下文预测信息作为条件随机场模型中待标注词的实际分类的关联点,根据训练语料利用em算法,计算出条件随机场各边的期望值,训练出对应的条件随机场模型,在使用条件随机场进行消歧后人名、地名、机构名的f值可以提升至94.8%、85.0%、82.0%。
通过上文的具体实施例可以看出,与传统的有监督的命名实体识别方法相比,本发明提供的基于神经网络概率消歧的文本命名实体识别方法,使用了一种可增量提取词特征而不产生词向量空间偏移的词向量转换方法,使神经网络可以应用在新词、错别字多的网络文本中。而且,本发明对神经网络输出的概率矩阵重新窗口化,采用条件随机场模型进行上下文消歧,可以较好的解决网络文本中错别字多、语法不规范的现象。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!