一种基于Lucene的支持表达式的自定义相关度排序算法的制作方法
本发明属于计算机技术领域,具体是一种基于lucene的支持表达式的自定义相关度排序算法。
背景技术:
目前,从海量信息中获取有用信息的关键技术是信息检索,信息检索的核心问题就是预测文档的相关度,并按照相关度对各文档进行排序。一般而言,排在最顶端的文档被认为最相关;因此,相关度的计算和排序算法就成为信息检索的核心。
典型的检索系统的排序技术主要有词频统计和词位置加权排序算法、基于用户反馈的directhit算法、pagerank超链接分析排序算法和hits排序算法。这些典型的相关度排序算法主要基于全文本分词或其在网络中的关注程度来对文档进行排序,适用于普遍的全文本搜索,不能满足用户特定的需求。
随着数据的爆炸式增长,大数据系统往往根据数据本身的特征,分为不同的字段进行存储,所以在文档检索排序时,单单使用全文本相关度排序已不能得到用户想要的结果,必须考虑更多的因素(即字段)进行排序,并应该为用户提供更为多样灵活的相关度排序算法。
技术实现要素:
本发明为了解决现有传统大数据系统字段间运算支持的函数种类缺乏多样性,字段间运算和自定义排序缺乏灵活性的问题,提供了一种基于lucene的支持表达式的自定义相关度排序算法。
具体步骤如下:
步骤一、搭建算法运行所需的分布式环境,包括若干数据节点,一个管理节点和一个元数据节点;
数据节点存储各字段的数据,底层采用lucene索引作为存储引擎;管理节点对数据存储和查询过程中的任务进行管理;元数据节点存储各数据节点的数据分布情况和各字段的类型等信息。
步骤二、对用户发送的某个文档或者文章,将内容划分为不同字段,并构造表达式作为相关度排序请求;
用户将文档或者文章中的不同内容存储到不同的字段中,在进行全文检索时,不同的字段作为不同的参数,构造不同内容的表达式作为相关度排序请求;每个文档的相关度排序请求为一个或者多个。
步骤三、针对某个相关度排序请求,管理节点进行解析后同时发送给不同数据节点,每个数据节点分别获取该请求的字段信息;
字段信息包括该字段的数据类型和字段名;文本类型的字段还包括该字段存储时所采用分词器。
管理节点解析该相关度排序请求,具体为:判断表达式是否合法,如果合法,将表达式和作为参数的字段名发送到各数据节点;否则,提示错误,结束。
表达式包括运算符表达式和函数表达式,针对运算符表达式,首先,判断运算符中操作数的个数是否合法,然后,将非数学数字的操作数作为未知参数,进行预运算,如果预运算通过,则该运算符表达式合法;
针对函数表达式,根据函数对照表,匹配函数表达式的函数名跟对照表中的函数名是否一致,且该函数表达式的所有字段名参数与元数据节点中的元数据表中的字段名称一一对比,如果全部对应,则该函数表达式合法。
步骤四、每个数据节点根据字段信息的不同字段名参数,在各自的数据节点中查询对应的不同字段数据;
步骤五、每个数据节点把各自的字段数据分别带入表达式,并调用函数对照表中对应的函数进行计算,将计算结果放入每个数据节点对应的堆中;
步骤六、对各堆中的相关度进行排序并调整,选择最终排序结果。
具体为:
步骤601、针对某个相关度排序请求对应的各个堆,从每个堆中选出各自的最大值;
步骤602、将所有最大值合并,再选择出其中的最大值作为最终结果;
步骤603、将最终结果从对应的堆中删除,并在该堆中重新选择最大值,与其余堆的最大值进行合并;
步骤604、重复步骤602,直至得到符合用户要求的最终结果。
步骤七、将最终自定义表达式的排序结果返回给用户。
本发明的有益效果在于:
本发明提供了一种灵活的自定义相关度排序算法,支持多字段间进行表达式计算,并按照其进行排序,优于单纯的文档打分排序机制,而且该发明支持更多的函数计算,且该算法适用于分布式的大数据平台上。
附图说明
图1为本发明一种基于lucene的支持表达式的自定义相关度排序算法的示意图;
图2为本发明元数据结构的示意图;
图3为本发明管理节点进行表达式解析的程序流程图;
图4为本发明一种基于lucene的支持表达式的自定义相关度排序算法流程图。
具体实施例
下面结合附图对本发明的具体实施方法进行详细说明。
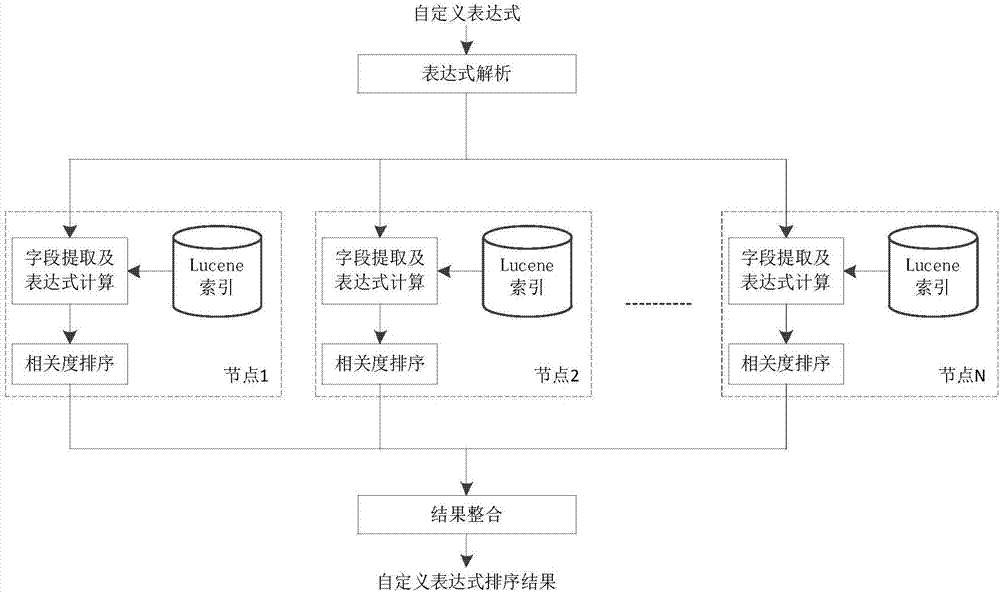
本发明一种基于lucene的支持表达式的自定义相关度排序算法,包括四部分:解析表达式,计算表达式,排序相关度和整合结果;对应采用四个模块:表达式解析模块,表达式计算模块,相关度排序模块和结果整合模块;
如图1所示,首先,用户输入自定义表达式后,表达式解析模块对用户输入的表达式进行合法性检查,并转化为系统可以计算的形式;
具体是:用户输入的表达式被管理节点进行解析,解析完成后,管理节点将表达式和表达式中参数(字段名)发送给各个数据节点;
然后,各数据节点根据字段名在底层的lucene索引中提取字段所对应的数据,并将字段数据带入表达式,应用表达式计算模块进行计算;
进而,相关度排序模块对各数据节点中表达式的计算结果进行排序;
具体为:将计算结果放入堆,各数据节点在各自的堆中放入一个计算结果,对堆进行一次调整;
最后,结果整合模块对各数据节点的堆顶元素进行比较,将最优结果从堆中取出,并对取出元素的堆进行调整;
由于本算法是基于分布式系统上的lucene索引进行计算的,所以需对各节点返回的计算结果进行整合,结果整合模块就是对各个节点的自定义表达式排序结果整合为用户需要的结果集进行返回。
如图4所示,所述算法具体步骤如下:
步骤一、搭建算法运行所需的分布式环境,包括若干数据节点,一个管理节点和一个元数据节点;
数据节点存储各字段的数据,底层采用lucene索引作为存储引擎;管理节点对数据存储和查询过程中的任务进行管理;元数据节点存储集群的数据分布情况和各字段的类型等信息。
在该实施实例中使用三台实体机分别作为master、datanode1、datanode2,以hadoop作为底层存储架构,利用zookeeper进行节点管理,在master节点上使用mysql存储数据系统的元数据。
如图2所示,设计数据的表结构,并将表结构相关数据存放到master节点的mysql元数据系统中;在数据系统通过基于lucene的数据录入系统,向三个节点中录入数据。
步骤二、针对用户发送的某个文档或者文章,将内容划分为不同字段,设计为表达式形式的相关度排序请求;
每个文档的相关度排序请求为一个或者多个;
用户将数据信息中的不同内容存储到不同的字段中,例如一篇博客可以分为:博客内容、评论数、评论内容、点赞数等,将这些信息存储为不同字段的数据信息,用户在进行全文检索时可以将这些字段作为表达式中的参数,来影响最终的相关度排序结果。例如用博客的评论数和点赞数来影响最终的相关度排序结果,那么在进行全文搜索时,就可以构造一个评论数和点赞数作为参数的表达式。
步骤三、针对某个相关度排序请求,管理节点进行解析后同时发送给不同数据节点,每个数据节点分别获取该请求的字段信息;
管理节点解析表达式:判断表达式是否合法,如果合法,将表达式和作为参数的字段名发送到各数据节点;否则,提示错误,结束。
用户输入表达式(例如:log10(field1)*sqrt(field2))进行检测,然后形成系统可计算的表达式,并将参数和表达式传送给各数据节点;
表达式包括运算符表达式和函数表达式;
针对运算符表达式,首先,判断运算符中操作数的个数是否合法,然后,将非数学数字的操作数(如函数名、字段名)作为未知参数,进行预运算,如果预运算通过则该运算符表达式合法;
针对函数表达式,根据函数对照表,匹配函数表达式的函数名跟对照表中的函数名是否一致,且该函数表达式的所有字段名参数与元数据节点中的元数据表中的字段名称一一对比,如果全部对应,则该函数表达式合法。
管理节点进行表达式解析的程序流程如图3所示,在表达式解析模块中预设了函数对照表;对照函数映射表,检测用户输入的表达式中的函数,并进行预编译,然后提取数据系统中字段名,检查表达式中的参数是否为数据系统中字段的字段名。
针对元数据中的读入字段信息,进行函数检查,检查函数合法性;如果是函数,判断参数是否合法,如果合法取出函数中参数体,再次进行函数检查;不合法则抛出异常,结束。如果不是函数,判断是否为常量或者操作符,如果是,再次判断是否合法,直至结束。如果不是常量或者操作符,判断是否为字段名,如果是,则判断是否合法,直至结束;否则,抛出异常结束。
本算法支持的运算类型及函数如下表所示:
字段信息包括该字段的数据类型、字段名,文本类型的字段还包括该字段存储时所采用分词器。
如图2所示,字段数据的元数据结构,包括了字段名、字段类型,名称为_score的字段为预留的默认全文打分字段,即lucene中默认的全文相关度打分字段。
步骤四、每个数据节点分别根据字段信息的不同字段名参数,在各自的数据节点中查询对应的不同字段数据;
步骤五、每个数据节点把各自的字段数据带入各自的表达式,并调用函数对照表中对应的函数进行计算,并将计算结果放入每个数据节点对应的堆中;
表达式计算模块根据表达式中的参数,在lucene索引中提取出参数相应字段的值进行计算。由于本算法的设计目的是应用于分布式大数据系统中,在表达式分析模块分析完后,将表达式及其参数传送到每一个数据节点,在每一个节点中提取表达式参数相应字段数据,并进行表达式计算,将计算结果放入堆中并调整。
步骤六、对各堆中的相关度进行排序并调整,选择最终排序结果。
具体为:
步骤601、针对某个相关度排序请求对应的各个堆,从每个堆中选出各自的最大值;
步骤602、将所有最大值合并后,再次选择出其中的最大值作为最终结果;
步骤603、将最终结果从对应的堆中删除,并在该堆中重新选择最大值,与其余堆的最大值进行合并;
步骤604、重复步骤602,直至得到符合用户要求的最终结果。
将各节点的计算结果进行整合,在各节点的结果堆中取出数据,对堆进行调整,将三个结点取出的数据进行比较,符合条件的从该结点中取出并调整结点的堆,符合条件的值放入最终结果的堆并调整。
步骤七、结果整合模块将最终排序结果返回给用户。
实施方式是基于本发明整体构思下的实现方式,而且本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!