一种新型快速正则表达式的硬件电路编译方法及编译器实现与流程
本发明涉及计算机、大数据、模式匹配等
技术领域:
,特别涉及正则表达式匹配在服务器端对高速输入数据的识别过滤系统。
背景技术:
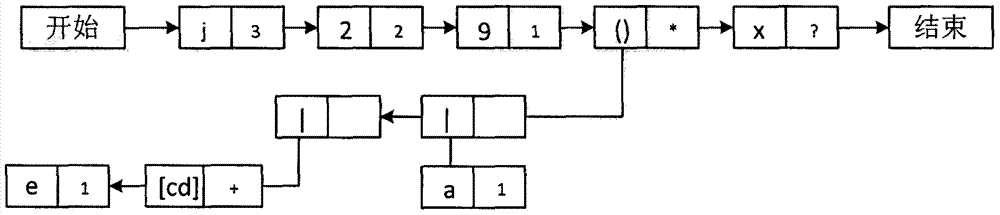
:正则表达式是当前主流的字符串识别机制之一,正则表达式具有构造相对简单,运行效率较高的特点,所以一般的字符串识别会使用正则表达式。正则表达式的软件匹配通过多年的发展,以及实现了完善的匹配功能,目前绝大多数正则表达式匹配功能通过软件实现。软件实现正则表达式匹配灵活方便,易于搭建匹配平台,且布置成本较低。正则表达式的匹配技术主要是基于非确定自动机(nfa),基于确定自动机(dfa)和基于nfa和dfa的混合匹配技术。因为nfa的并行状态特性很匹配fpga的天然并发性,是在fpga上实现正则匹配引擎的首选。随着网络带宽的不断增长,网络将无数计算机资源极尽所能的连结在一起,在互联网用户和互联网资源海量互联的同时也带来了大量垃圾信息和恶意攻击,此时单纯依靠软件过滤程序或许能够满足单个用户的应用需求,如采用snort/bro等入侵检测系统,依靠正则表达式匹配软件过滤危险信息。但是在服务器端,在这个数据爆炸的时代,依靠软件过滤的方法无法满足服务器的带宽需求。因此基于软件的正则表达式匹配引擎已经无法满足网络带宽高速增长的需求。正则表达式匹配引擎硬件加速研究会成为接下来研究的热点。正则表达式匹配的硬件实现研究起源于1982年,floy和ullman基于自动机理论在硬件上实现了一个nfa模型;sidhu和prasanna在此基础上提出了正则表达式中的基本操作符,连接、并联和闭包的基本专用电路结构,为之后模块化构造正则表达式硬件电路打下基础。在未来的应用场景中,快速的编译大规模的正则表达式集合并在像fpga这样的硬件平台配置对应的匹配引擎,有很高的应用价值。技术实现要素:发明目的:本发明旨在发明一个通用正则表达式编译器,快速地将大规模的正则表达式规则集合编译成对应的硬件匹配引擎并配置在fpga上。解决过滤系统规则集更替带来的烦琐工作,实现从输入规则到输出电路全自动的编译过程,解决了硬件入侵检测系统维护工作的复杂度。为了解决上述技术问题,本发明公开了一种新型的正则表达式自动快速编译方法并通过组合程序段实现编译器的全部功能。代码简洁,编译器功能强大。为了便于阐述,定义基本正则表达式规则a:a=j{3}2{2}9(a|[cd]+e)*x?,在规则a中,{3}为限定重复三次前驱字符。“|”为或关系操作符,即并联关系。“+”为限定重复至少一次前驱字符。“*”为限定词重复任意次前驱字符。“?”为限定重复0或1次前驱字符。正则表达式a仅仅为简单示例,并不涵盖本编译器包含的全部语法。本发明的主要内容包括:1.前期处理模块,对输入的snort/bro等规则集合的正则表达式部分截取,保存为正则集合输入文件。2.规则集合生成模块,在本编译支持语法框架下,输出任意数量任意长度的正则表达式集合。3.对于基本正则表达式a,编译器自动抓取单个匹配规则,分析正则式构成,将正则表达式分析成链式结构。4.对链式结构进行解析,采用改进的my算法输出nfa结果,并标记为自定义的新型nfa表示结构,后续模块可从nfa表示图中获取连接信息。5.在此过程中伴随以并行的匹配字符串输出和相应的测试激励文件生成功能,为rtl配置前测试提供配套的测试用例和仿真激励文件。6.采用并行结构自动集合输入规则集合对应的生成模块,连接以生成整体的对应集合的正则表达式匹配引擎。本发明采用并行结构,自动对输入的文件进行分析,选择截取获取或者自动生成符合要求的正则表达式集合,编译器操作难度低,编译速度快,可以很好的加速今后硬件过滤平台的搭建,快速的实现从正则规则集到现实的硬件电路的生成,并可以提供配套的测试文件用于仿真测试。附图说明下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。图1是本发明的整体模块划分图。图2是本发明的链式编译分析图。图3是本发明的核心编译功能示意图。图4是本发明的核心编译功能示例的nfa状态转移图。图5是本发明的匹配更新模块(左)和否定匹配模块(右)。图6是本发明的二输入匹配状态更新模块综合实例示意图。图7是本发明的正则匹配引擎结构。图8是本发明的十规则引擎综合rtl结构示意图。具体实施方式下面详细地描述本发明的实施例,所述示例为上述正则表达式a,编译器整体框架以及分流程在附图中示出。本编译器可以从输入端接收或自动生成测试正则规则集合,并自动完成之后编译过程直至输出rtl电路用于之后的仿真和综合验证。如图1所示,整个正则表达式编译器由snort/bro规则集合提取模块,自定义规则集合生成模块,匹配字符串生成模块,测试文件生成模块,正则表达式编译模块,顶层连接模块,rtl输出模块等七个模块组成。所有的子模块集合构成了自动本发明的快速自动正则表达式编译器。如图2所示,编译器首先将输入的正则表达式示例a分析成链式结构的组成单元。每个单元由四个构成要素组成,分别是值域、正则操作符、后继单元和子单元。其中值域可以表示ascii表中任意字符(包含具有特殊作用,需要转义使用的字符)。操作符包括了所有正则表达式支持的语法,并支持部分定制的语法功能的添加。后继单元则承接前驱单元,子单元为出现“()”和“|”时的多路可选子规则。本编译器支持的正则表达式语法规则见表一。表一:编译器支持的正则规则语法操作符正则表达式中的匹配作用a+匹配大于一个aa?匹配零或一个aa*匹配任意个数a(a|b)匹配a或者b中的一个a{n}/{n,}/{n,m}限定重复,匹配n个a/大于n个a/n至m个a.通配符,匹配任意一个字符\xff匹配十六进制值对应的ascii字符\n,\r,\t,\v匹配回车,换行,制表,垂直制表符[a-z],[0-9],[!-&]范围匹配,匹配“-”相连范围内的字符[abc]匹配abc中任意一个字符[^a-z]否定范围匹配,匹配除“-”相连范围内的字符[a-c0-9!-&]范围匹配,匹配“-”两侧若干范围内的任意字符\*,\?,\+转义字符,将特殊字符转义成普通字符匹配^reg^从开头开始匹配reg&&匹配至结尾处结束\s\s,匹配任意空白字符(回车,换行,制表,空格)\s\s,匹配任意非空白字符\d匹配任意0-9之间数字\d匹配除0-9之外的任意字符\w匹配0-9,a-z,a-z,或“_”\w匹配除\w,之外的任意字符.*(?^abc)限定通配符重复,匹配任意个数除(abc)外的任意字符除了通用的正则表达式规则之外,本编译器还支持一些自定义规则并预留新匹配规则支持接口以便编译器后期功能升级。如图3所示为编译器核心算法流程。在完成链式分析之后,编译器将链式存储单元读入并采用改进后的my(mcnaughton-yamada)构造算法,将链式单元分析成对应的nfa单个状态。如图4所示为示例正则表达式a所对应的状态转移图。根据nfa结构,本发明所提出的编译方法采取新型的nfa标记结构,有效存储了nfa状态转移方向,方便了之后连接模块对单个正则规则单元采取对应的连接策略。表二为本发明所提出的新型nfa记录结构。表二:针对示例a的nfa记录结构状态名状态值前入状态后续状态标记位0start/1t1j02t2j13t3j24t4235t5246t6957,8,10,11t7a6,7,97,8,10,11t8cd6,7,8,98,9t9e87,8,10,11t10x6,7,911t11end6,7,9,10/t本发明方法定义的nfa结构包含五个组成部分,状态名,状态值,前入状态,后续状态,匹配标记。1.状态名部分由起始状态0开始,依次标记为对应状态号。2.状态值从start开始终于end。之间各状态的值为状态对应的转移值。3.前入状态表示为转移到该状态的所有状态。4.后续状态表示状态往后转移的路径。5.标记位记录了状态的匹配状态,“t”为匹配,“f”为否定匹配,即匹配非val值的任意字符。由表二可知,起始状态的前入状态为空,终止状态的后续状态为空。正则表达式模块根据nfa状态,对该nfa所对应的正则表达式的硬件电路进行模块连结。采取模块化的匹配模块,根据nfa中的后续状态集合,自动连结各状态模块,实现整个正则匹配单元。如图五所示为单个状态匹配的状态更新模块结构示意图,左图为匹配模块,右图为否定匹配模块。如图六所示为匹配状态更新模块的综合rtl可视图。对照本编译器输出的硬件描述文件,在quartusii中综合得到的结果。如图七所示,编译器编译完成规则集合中的所有正则表达式之后,顶层连结模块将所有正则表达单元联结成完整正则表达式匹配引擎。并伴随产生对应的规则集合测试文件和仿真激励文件。如图八所示为十规则正则匹配引擎的综合rtl可视图。表三为示例十规则集合,此处仅为验证整体结构,并未涉及到本编译器所支持的全部语法规则。表三:示例十规则正则表达式集合lq*(q{2,4}|uj{4,})*(mx?|ov+)[uwp][vi](z?[xo]|[jz]?)?[jr][bx]shc[^cl]*f+z{2}wp?.s(m{3}|jy*)+tq?(n+|lf)*[fr][xh]?ds+.r*[lve]ywt+pk?(k{2,6}|.n+)*run(ffbn|eld+)?k{2,}[cj]*z{1,6}(js|l+)fh+q{4,}ibvm([dp]|pw+)?m{2}mo[hn]?[ac]nn([cxa]?|fc)测试字符串为编译器产生字符串集合,如表四所示。在modelsim中用对表四中的示例字符串所产生的激励文件进行仿真,仿真结果表明本编译器编译产生的硬件电路能够有效的匹配相应符合规则的信息。表四:示例十规则正则表达式测试字符串集合lqqujjjjjmwijxshcaaaffzzwpasmmmtqlflffhdsswrreywttpannnrunelddkkkjjjzzzllfhhhqqqqqibvmpwwmmmocnnfc对大规模测试集合的编译结果表面,本编译器可以在30秒内实现包含超过500个正则表达式的正则表达式规则集合的编译,生成对应的硬件描述文件,测试文件和激励文件,且仿真综合结果都符合要求。综上所述,利用本发明实施例展示了本编译器方法及实现编译器的作用。可以快速高效的实现对大规模正则匹配引擎的搭建,适用于今后数据带宽日益提高的高速数据匹配场景。尽管已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下载本发明的范围内可以对上述实施例进行变化、修改、替换和变型。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1