基于灾情表单自动生成灾情报告的方法及系统与流程
本发明涉及信息科学技术领域,具体涉及基于灾情表单自动生成灾情报告的方法及系统。
背景技术:
目前,由于灾情报告公文包括以下几点特殊性:不同数量级灾情指标的差异化进位格式、标准行政区划的复杂表述格式、长短句间的断句和标点使用规则等。由于上述灾情报告公文的特殊性,使得基于现有技术无法准确地按照公文要求对结构化的灾情表单进行文本转化,形成符合自然语言规则的灾情报告,因此,需要人工制作灾情报告,这增加了制作报告的时间,提高了人工成本,同时人工制作过程中极易出错。
技术实现要素:
针对现有技术中的缺陷,本发明提供的基于灾情表单自动生成灾情报告的方法及系统,能够依据结构化的灾情表单数据,按公文语言格式标准化、自动地化生成灾情报告文本。
第一方面,本发明提供的一种基于灾情表单自动生成灾情报告的方法,包括:
获取灾情的灾情表单;
提取所述灾情表单中的受灾区域,从数据库中提取所述受灾区域包括的行政区域,根据提取的行政区域生成受灾区域文本段落;
提取所述灾情表单中的灾情指标数据,将所述灾情指标数据转化为标准指标数值后填入预先设定的指标文本中形成灾情文本段落;
连接所述受灾区域文本段落和所述灾情文本段落得到符合自然语言规则的灾情报告。
本实施例提供的基于灾情表单自动生成灾情报告的方法,以结构化表单数据为基础,按照一定自然语言规则自动化的生成灾情报告文本,不仅极大提升了业务工作效率、提高了灾情发布效率,而且将灾情报告中出现数据错误的概率将至最低。
优选地,所述提取所述灾情表单中的受灾区域,从数据库中提取所述受灾区域包括的行政区域,根据提取的行政区域生成受灾区域文本段落,包括:
提取所述灾情表单中的受灾区域;
从数据库中提取所述受灾区域包括的行政区域形成受灾区域列表;
统计所述受灾区域列表中行政区域的区划名称的字数得到总文字数量;
若所述总文字数量超过预设的字数阈值,则缩减所述受灾区域列表中的行政区域的区划名称,否则,保持所述受灾区域列表中的行政区域的区划名称不变;
根据所述受灾列表中行政区域的区划名称生成受灾区域文本段落。
优选地,所述缩减所述受灾区域列表中的行政区域的区划名称,包括:
根据预先构建的区划名称缩写词库,对所述受灾区域列表中的行政区域的区划名称采用缩写进行替换。
优选地,所述缩减所述受灾区域列表中的行政区域的区划名称,包括:按照区划继承关系,对所述受灾区域列表中的行政区域进行合并,得到缩减后的受灾区划列表。
优选地,所述形成受灾区域列表之前还包括:根据预先构建的第一列表过滤所述受灾区域列表,剔除所述受灾区域列表中的特殊区域,所述特殊区域包括空头市和直管县,所述第一列表包括所有空头市和直管县;
所述根据所述受灾列表中行政区域的区划名称生成受灾区域文本段落,包括:将所述特殊区域与所述受灾区域列表中的行政区划名称进行挂接,生成受灾区域文本段落。
优选地,提取所述灾情表单中的灾情指标数据,将所述灾情指标数据转化为标准指标数值后填入预先设定的指标文本中形成灾情文本段落,包括:
提取所述灾情表单中的灾情指标数据,所述灾情指标数据标注有指标类别,一种指标类别对应一种灾情指标,每个在灾情指标包含至少一个子级指标;
对不同指标类别的灾情指标数据分别进行如下操作:将所述灾情指标数据转化为标准指标数值,确定每个所述标准指标数值对应的子级指标,将所述标准指标数值写入各子级指标对应的指标文本中,连接各个子级指标的指标文本得到单类指标文本;
连接所有单项指标文本得到形成灾情文本段落。
优选地,所述将所述灾情指标数据转化为标准指标数值,包括:
根据所述灾情指标数据确定数量级,
根据所述数量级对所述灾情指标数据进行进位处理,并添加与所述数量级对应的单位词得到标准指标数据。
优选地,还包括:
对各类灾情指标的子级指标写入数量进行统计;
若各类灾情指标的子级指标写入数量均为1,则所述连接所有单项指标文本得到形成灾情文本段落包括:采用一级分割符号连接所有单项指标文本得到形成灾情文本段落,所述灾情文本段落末尾用句号匹配;
若至少有一类灾情指标的子级指标写入数量超过1,则所述连接各个子级指标的指标文本得到单类指标文本,包括:采用一级分割符号连接各个子级指标的指标文本得到单类指标文本;则所述连接所有单项指标文本得到形成灾情文本段落包括:采用二级分割符号连接所有单类指标文本,所述灾情文本段落末尾用句号匹配。
优选地,所述指标类别包括:人口类指标、房屋类指标、农业类指标、经济类指标。
第二方面,本发明提供的一种基于灾情表单自动生成灾情报告的系统,包括:
灾情表单获取模块,用于获取灾情的灾情表单;
受灾区域文本段落生成模块,用于提取所述灾情表单中的受灾区域,从数据库中提取所述受灾区域包括的行政区域,根据提取的行政区域生成受灾区域文本段落;
灾情文本段落生成模块,用于提取所述灾情表单中的灾情指标数据,将所述灾情指标数据转化为标准指标数值后填入预先设定的指标文本中形成灾情文本段落;
灾情报告生成模块,用于连接所述受灾区域文本段落和所述灾情文本段落得到符合自然语言规则的灾情报告。
本实施例提供的基于灾情表单自动生成灾情报告的系统,以结构化表单数据为基础,按照一定自然语言规则自动化的生成灾情报告文本,不仅极大提升了业务工作效率、提高了灾情发布效率,而且将灾情报告中出现数据错误的概率将至最低。
附图说明
图1为本发明实施例所提供的基于灾情表单自动生成灾情报告的方法的流程图;
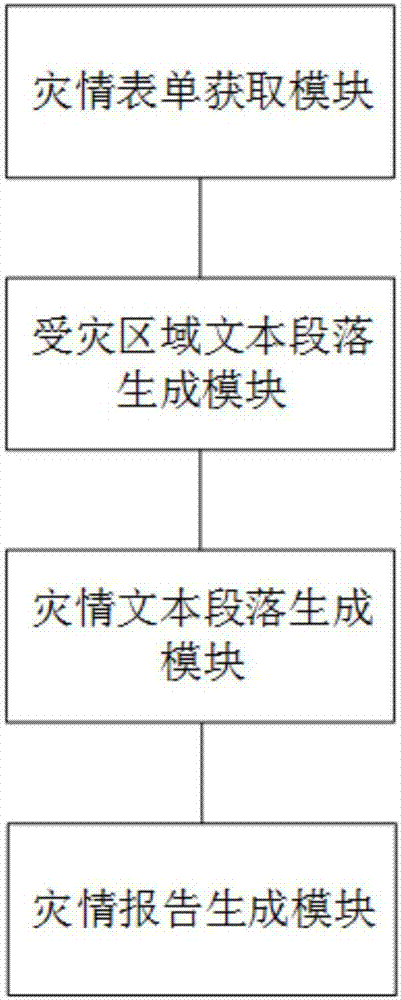
图2为本发明实施例所提供的基于灾情表单自动生成灾情报告的系统的结构框图。
具体实施方式
下面将结合附图对本发明技术方案的实施例进行详细的描述。以下实施例仅用于更加清楚地说明本发明的技术方案,因此只是作为示例,而不能以此来限制本发明的保护范围。
需要注意的是,除非另有说明,本申请使用的技术术语或者科学术语应当为本发明所属领域技术人员所理解的通常意义。
如图1所示,本实施例提供了一种基于灾情表单自动生成灾情报告的方法,包括:
步骤s1,获取灾情的灾情表单。
其中,灾情表单为结构化的表格,存储有与灾情有关的数据。
步骤s2,提取灾情表单中的受灾区域,从数据库中提取受灾区域包括的行政区域,根据提取的行政区域生成受灾区域文本段落。
其中,自然灾害的灾情信息在采集、上报与数据统计、发布上使用了与行政区域不同的划分标准,受灾区域是根据采集点的分布、采集点的地域条件等进行划分的,一个受灾区域可能跨多个省市县,如长江下游流域就包括安庆、南京、苏州、上海等行政区域。因此,一个受灾区域包含至少一个行政区域。
步骤s3,提取灾情表单中的灾情指标数据,将灾情指标数据转化为标准指标数值后填入预先设定的指标文本中形成灾情文本段落。
其中,每一项灾情指标数据都有对应的固定格式的指标文本。其中,灾情指标数据一般为数值,当然也可以是文字内容。
步骤s4,连接受灾区域文本段落和灾情文本段落得到符合自然语言规则的灾情报告。
本实施例提供的基于灾情表单自动生成灾情报告的方法,以结构化表单数据为基础,按照一定自然语言规则自动化的生成灾情报告文本,不仅极大提升了业务工作效率、提高了灾情发布效率,而且将灾情报告中出现数据错误的概率将至最低。
其中,步骤s2的实现方式有多种,为了规范发布的灾情报告、精简灾情报告的内容,步骤s2的优选实施方式包括:
步骤s21,提取灾情表单中的受灾区域。
步骤s22,从数据库中提取受灾区域包括的行政区域形成受灾区域列表。
步骤s23,统计受灾区域列表中行政区域的区划名称的字数得到总文字数量。
步骤s24,若总文字数量超过预设的字数阈值,则缩减受灾区域列表中的行政区域的区划名称,否则,保持受灾区域列表中的行政区域的区划名称不变。
步骤s25,根据受灾列表中行政区域的区划名称生成受灾区域文本段落。
通过对灾情报告中的受灾区域文本段落的字数控制,可以精简灾情报告的内容,使得报告阅读者能够第一时间获取有效的信息。
其中,步骤s24中,缩减受灾区域列表中的行政区域的区划名称方法有多种,本实施例的优先实现方法包括:根据预先构建的区划名称缩写词库,对受灾区域列表中的行政区域的区划名称采用缩写进行替换。受灾区域列表中会存储替换后的区划名称的缩写,因此,灾情报告的文本中行政区域会以缩写的形式进行发布。其中,区划名称缩写词库会记录所有行政区域对应的合法缩写,比如,对地市级、县级受灾区域名称中的“xx族”“自治”等词汇进行过滤,删除其中“xx族”“自治”等词汇,又如,采用行政区域的简称进行替代,最终实现区划名称的缩写。
其中,步骤s24中,缩减受灾区域列表中的行政区域的区划名称方法有多种,本实施例的优先实现方法包括:按照区划继承关系,对受灾区域列表中的行政区域进行合并,得到缩减后的受灾区划列表。
其中,受灾市、县,在受灾区域列表中按照区划代码顺序排列好。例如,市:济南市、青岛市、菏泽市;县:章丘市、黄岛区、曹县。则,按照区划继承关系,对受灾区域列表中的行政区域进行合并,具体包括以下步骤:当市、县的数量相等时,亦即每个地市有一个受灾县,此时,若市(县)数量不超过3个,直接进行挂接,济南市章丘市、青岛市黄岛区、菏泽市曹县;若市(县)数量超过3个,按照前三个截断缩减描述,济南、青岛、菏泽等5市5个县(市、区)。当市、县数量不等时(市小于县),按照区划顺序缩减描述,济南、青岛2市3个县(市、区),或济南、青岛、菏泽等4市7个县(市、区)。
本实施例还提供了步骤s2另一优选实施例方式,包括:
步骤s201,提取灾情表单中的受灾区域。
步骤s202,根据预先构建的第一列表过滤受灾区域列表,剔除受灾区域列表中的特殊区域,特殊区域包括空头市和直管县,第一列表包括所有空头市和直管县。
其中,空头市和直管县是特殊行政区划结构,需要单独在文本中罗列,不参与一般区划数量的统计和表述,所以先行剔除。剔除特殊区域后,剩余的区划单位都是结构化的、标准的,对这些区划单位处理后,在文本末尾单独加上空头市和直管县。剔除了特殊区域的受灾区域列表中的行政区域组合成常规受灾区域。
步骤s203,从数据库中提取受灾区域包括的行政区域形成受灾区域列表。
步骤s204,统计受灾区域列表中行政区域的区划名称的字数得到总文字数量。
步骤s205,若总文字数量超过预设的字数阈值,则缩减受灾区域列表中的行政区域的区划名称,否则,保持受灾区域列表中的行政区域的区划名称不变。
其中,步骤s205中,缩减受灾区域列表中的行政区域的区划名称的优先实现方法包括:根据预先构建的区划名称缩写词库,对受灾区域列表中的行政区域的区划名称采用缩写进行替换。
其中,步骤s205中,缩减受灾区域列表中的行政区域的区划名称的优先实现方法包括:按照区划继承关系,对受灾区域列表中的行政区域进行合并,得到缩减后的受灾区划列表。
步骤s206,将特殊区域与受灾区域列表中的行政区划名称进行挂接,生成受灾区域文本段落。
其中,步骤s206中,会根据特殊区域的数量,判断采用何种连接词语法,并与常规受灾区域的文本进行挂接,生成最终的受灾区域文本段落。
其中,为了对灾情指标数据实现分类处理,方便规范各类指标的不同表达方式,步骤s3的优选实施方式包括:
步骤s31,提取灾情表单中的灾情指标数据,灾情指标数据标注有指标类别,一种指标类别对应一种灾情指标,每个在灾情指标包含至少一个子级指标。
其中,指标类别包括但不限于人口类指标、房屋类指标、农业类指标、经济类指标。
其中,人口类指标的子级指标包括但不限于受灾人口、紧急转移安置人口、死亡失踪人口。房屋类指标的子级指标包括单不限于倒塌房屋数量、损坏房屋数量。农业类指标的子级指标包括单不限于农作物受灾面积、农作物绝收面积。经济类指标的子级指标包括单不限于直接经济损失。
上述分类方法合理地对指标进行分类,使报告结果更清晰,提高可阅读性。
步骤s32,对不同指标类别的灾情指标数据分别进行如下操作:将灾情指标数据转化为标准指标数值,确定每个标准指标数值对应的子级指标,将标准指标数值写入各子级指标对应的指标文本中,连接各个子级指标的指标文本得到单类指标文本。
步骤s33,连接所有单项指标文本得到形成灾情文本段落。
其中,步骤s3和步骤s32中,将灾情指标数据转化为标准指标数值的优选实施例方式包括:根据灾情指标数据确定数量级,根据数量级对灾情指标数据进行进位处理,并添加与数量级对应的单位词得到标准指标数据。其中,灾情指标数据的数量级可以根据实际情况设定,一般包括百、万、亿三个数量级。特殊的,对于农业类指标的数量级可以设为百、千、亿。其中,单位词包括:百、千、万、亿。
其中,进位处理是将数值转换为预定的格式的过程,不同数量级采用不同的进位处理方法。对万(或千)以下的数量级,按照“逢八进位”原则进行进位处理,并判断后缀词汇是“余”还是“近”,“逢八进位”原则如下:当十位数不超过8时,例如7530人受灾、660万元,用“余”,写为7500余人受灾、损失600余万元;当十位数超过8时,例如7582人受灾,690万元损失,用“近”,写为近7600人受灾、损失近700万元。对万(或千)以上、亿以下的数量级,按照“逢八进位”原则进行进位处理,并判断后缀词汇是“余”还是“近”,加“万”或“千”单位词。对亿以上的数量级,按照“四舍五入”原则进行进位,保留小数点后一位小数,加“亿”单位词。上述方法解决了不同数量级的灾情指标数据差异化的问题,统一规范了灾情报告中数值的表达方式。
因为根据公文语法的规定对各类灾情指标中的子级指标在文本中设置了固定顺序和表达格式,因此需要判断依据灾情表单中的数据获取了哪些子级指标,即判断写入各单类指标文本的指标数量,以此来判断各单类指标文本中,每个子级指标对应的指标量词组的顺序和首词组、次词组、末次词组的语法格式。对每一类灾情指标来说,若其所有子级指标都获取到了对应的数据,则采用正常语序和表达格式;若后序的子级指标缺失,则仅表达首序的指标文本;若于首序的子级指标缺失,则需要将后序词组前置,用首序语法格式化转换。通过上述方法,可以根据指标的写入量自动调整语句的顺序和表达格式,使最终生成的灾情报告的语句更加自然顺畅。
以倒损房屋为例说明上述调整语句的顺序和表达格式的方法:
获取的子级指标为:120间倒塌、380间严重损坏、1100间一般损坏。该情况对应所有子级指标都获取到的情况,则采用正常语序和表达格式,写为“100余间房屋倒塌,近400间严重损坏,1100余间一般损坏”;
获取的子级指标为:120间倒塌、380间严重损坏,没有一般损坏,这一情况对应后序的子级指标缺失,则写为“100余间房屋倒塌,近400间严重损坏”;
获取的子级指标为:120间倒塌、1100间一般损坏,没有严重损坏,则写为“100余间房屋倒塌,1100余间一般损坏”;
获取的子级指标为:120间倒塌,没有损坏,则写为“100余间房屋倒塌”;
获取的子级指标为:380间严重损坏、1100间一般损坏,则写为“近400间房屋倒塌,1100余间一般损坏”;
获取的子级指标为:380间严重损坏,没有倒塌和一般损坏,则写为“近400间房屋严重损坏”;
获取的子级指标为:1100间一般损坏,没有倒塌和严重损坏,则写为“1100余间房屋一般损坏”。
同类指标,根据写入数量的多少,需要动态调整每个指标对应短语的表述,不是简单的机械罗列;首句有房屋,后面的就要承前省略“房屋”二字。
基于上述的方法实施例,本实施例中还包括对灾情报告中的长短语句的标点符号进行自动匹配,具体实现方法包括:
步骤s501,对各类灾情指标的子级指标写入数量进行统计。
其中,写入数量是指对各类灾情指标来说,从灾情表单中获取到的子级指标的数量。
步骤s502,若各类灾情指标的子级指标写入数量均为1,则步骤s33包括:采用一级分割符号连接所有单项指标文本得到形成灾情文本段落,灾情文本段落末尾用句号匹配。
步骤s503,若至少有一类灾情指标的子级指标写入数量超过1,则步骤s32中的连接各个子级指标的指标文本得到单类指标文本,包括:采用一级分割符号连接各个子级指标的指标文本得到单类指标文本;则步骤s33包括:采用二级分割符号连接所有单类指标文本,灾情文本段落末尾用句号匹配。
其中,一级分割符号可以为逗号,二级分割符号可以为分号,当然也可以选择其它符号。
本实施例提供的基于灾情表单自动生成灾情报告的方法,实现了在完全遵守灾情报告公文规范约束下,将结构化的灾情表单数据全自动化、无人工干预的转化为自然语言文本,装换的准确率达98%以上,人工修正率不超过5%。通过本实施例提供的方法,使单个灾害案例数据的文本转化时间由传统的全人工15分钟,提升至小于3秒钟,不仅极大提升了业务工作效率,而且将文本中出现数据错误的概率将至最低。
基于与上述基于灾情表单自动生成灾情报告的方法相同的发明构思,本实施例还提供了一种基于灾情表单自动生成灾情报告的系统,如图2所示,包括:
灾情表单获取模块,用于获取灾情的灾情表单;
受灾区域文本段落生成模块,用于提取灾情表单中的受灾区域,从数据库中提取受灾区域包括的行政区域,根据提取的行政区域生成受灾区域文本段落;
灾情文本段落生成模块,用于提取灾情表单中的灾情指标数据,将灾情指标数据转化为标准指标数值后填入预先设定的指标文本中形成灾情文本段落;
灾情报告生成模块,用于连接受灾区域文本段落和灾情文本段落得到符合自然语言规则的灾情报告。
本实施例提供的基于灾情表单自动生成灾情报告的系统,以结构化表单数据为基础,按照一定自然语言规则自动化的生成灾情报告文本,不仅极大提升了业务工作效率、提高了灾情发布效率,而且将灾情报告中出现数据错误的概率将至最低。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
- 还没有人留言评论。精彩留言会获得点赞!