一种基于发布/订阅模式的分布式度量相似查询处理方法与流程
本发明涉及数据库的索引与查询技术,特别是一种基于发布/订阅模式的分布式度量相似查询处理方法。
背景技术:
度量相似查询包括度量空间区域查询和度量k最近邻查询。度量区域查询是指:给定度量空间中的一个数据集、一个查询点和一个距离阈值,找到给定数据集中与查询点距离小于阈值的所有数据对象。度量k最近邻查询是指:给定度量空间中的一个数据集、一个查询点和一个整数k,找到给定数据集中与查询点距离最近的k个数据对象。度量相似查询是数据库领域的重要查询类型,被广泛地应用于社会的各个领域中。
现有的查询处理大多关注欧氏空间,并用欧式距离来度量对象之间的邻近关系;但在许多的实际应用,如地理信息系统、数据挖掘、模式识别,对象之间的邻近关系并不能用欧式距离来度量,而需要用借助其它的距离度量方式。例如,路网上两个位置间的距离度量往往借助于路网距离;字符串之间的距离则更多使用编辑距离进行度量。
为此,我们需要借助度量空间进行统一表达。度量空间是支持任意距离函数的一种更为广泛的空间,只要求其距离度量函数满足非负性、对称性和三角不等式性。为了快速有效地组织、存储和访问度量空间数据,专家学者们提出了大量的索引方式。迄今为止,影响最大、应用最广泛的是m树索引结构。m树是ciaccia、patella和zezula在1997年提出的,它是一棵基于外存的平衡树,其更新操作代价小且无需重构树。
另一方面,随着互联网的发展,特别是移动设备的广泛使用,使得数据在体量,多样性和丰富度上有着极大的增长,这也对传统的度量相似查询算法在时间效率和空间效率上提出了挑战。因此,我们需要一种具有良好可伸缩性的度量相似查询处理方法来提供高效的查询处理服务以适应这样的场景。
目前,面向相似查询的方法大多针对欧式空间,并利用欧氏空间的几何特性以加速查询;但不幸的是,这些欧氏空间的几何特性并不能通用于度量空间。所以,这些方法不能用来解决度量相似查询。此外,现存集中式的度量相似查询方法因扩展性有限、查询效率低,并不能用来处理大规模数据。所以,设计一种具有高可扩展性、高效率的分布式度量相似查询处理方法成为了学术界与工业界的迫切需求。
技术实现要素:
针对现有技术的不足,本发明提供一种基于发布/订阅模式的分布式度量相似查询处理方法。该方法在分布式系统中对数据进行划分后,建立局部m树索引,并将系统中的节点组织成树形结构,便于后续查询任务的处理;在处理用户相似查询请求时,本方法基于发布/订阅模式将查询请求包装成任务供对应的节点进行处理。
为了达到上述目的,本发明所采用技术方案如下:一种基于发布/订阅模式的分布式度量相似查询处理方法,具体包括如下步骤:
(1)对应用中给定的度量空间数据集进行随机采样,得到样本数据;
(2)对得到的样本数据进行支枢点选择,并据此将应用中给定的整个数据集(包括样本数据)从度量空间映射至向量空间;
(3)利用样本数据构建kd树,得到叶子节点对应的空间划分;
(4)根据步骤(3)得到空间划分,将应用中给定的度量空间数据集(包括样本数据)进行划分,并将划分后的数据分发到对应的工作节点。
(5)各个工作节点对分配到的数据建立局部索引,工作节点、管理节点以及根节点形成树形层次结构,并对自己负责的数据信息进行统计。
(6)将用户的查询请求作为任务发布,各个节点判断、订阅查询范围与自己职责范围相交的任务,并在所有相关工作节点返回结果后,对结果进行整合并返回给用户。
进一步的,所述步骤(2)具体为:
2.1)在样本数据中找出离群点作为支枢点的候选集合;
2.2)根据支枢点的选择目标,对候选集合中的点进行增量式的贪心选择,得到支枢点集;
2.3)对于每一个在度量空间中的数据,计算其与步骤2.2)中得到的支枢点集中的每个支枢点之间的距离,并将求得的距离作为向量空间中各维度的坐标值,以得到度量空间数据在向量空间中的坐标。
进一步的,所述的步骤(3)具体为:对步骤(1)得到的样本数据,构建kd树,得到的kd树中包含数据点个数相等的叶子节点,各叶子节点对应的空间区域即为空间划分的结果;这里需要注意的是kd树叶子节点的数目是提前指定的,与后续分布式系统中工作节点的数目相等且一一对应。
进一步的,所述的步骤(4)具体为:将应用中给定的整个度量空间数据集(包括样本数据)划分到步骤(3)得到的相应空间划分中去;完成划分后的数据分发到对应的工作节点,进行下一步处理;
进一步的,所述的步骤(5)具体为:
5.1)各个工作节点对分配到的数据建立局部m树索引,加速后续查询任务的处理;
5.2)工作节点、管理节点以及根节点形成树形结构,工作节点作为叶子节点,直接负责数据处理;管理节点作为中间节点,负责管理子节点以及与上层进行通讯;根节点负责管理整个分布式系统;
5.3)每个节点统计自己负责数据的信息,包括数据的范围、数目;管理节点、根节点还需记录自己对应子节点的相关统计信息,以便后续查询任务的发布/订阅处理。
进一步的,所述的步骤(6)具体为:
6.1)将用户的查询作为任务发布,各个节点查看发布中的任务,若与自己负责的数据范围相交,则对其进行基于m树索引的最佳优先查询处理;
6.2)最初发布任务的节点维护一个计数器,该计数器用于计算完成任务的工作节点数量,计数器在所有相关的工作节点返回结果后会被加满;在计数器加满后,该节点对得到结果进行整合并返回给用户。
本发明具有的有益效果是:本发明充分利用了空间数据库中索引技术和相关查询技术,丰富和优化了分布式环境下的度量相似查询处理方法;采用统一的方法来处理相似查询;基于发布/订阅模式,对两种不同类型的度量相似查询进行处理,并利用范围过滤、索引等技术加速查询处理,极大地提升了度量相似查询的性能。
附图说明
图1为本发明的实施步骤流程图;
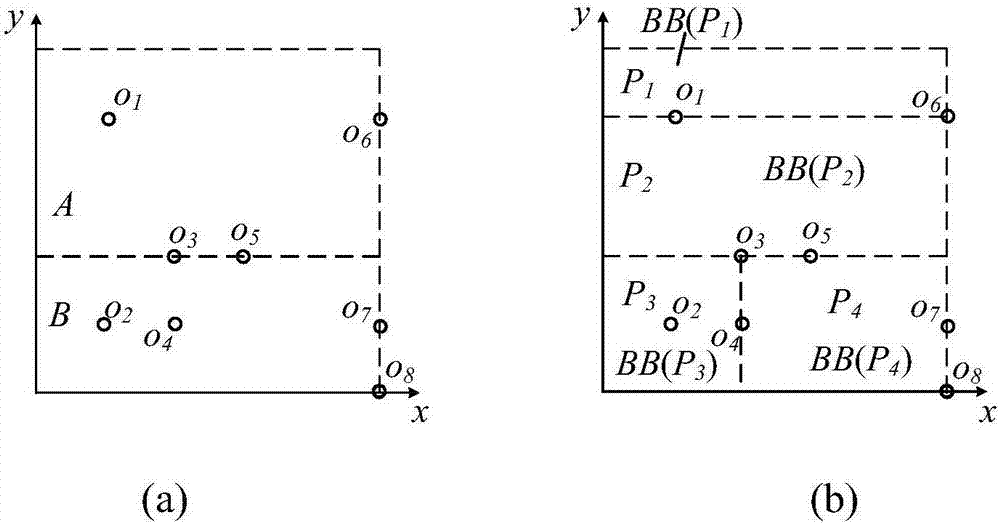
图2(a)为基于kd树的空间迭代划分第一轮示意图,(b)为基于kd树的空间迭代划分第二轮示意图;
图3为基于发布/订阅模式的分布式度量相似查询处理方法工作原理示意图。
具体实施方式
现结合附图和具体实施对本发明的技术方案作进一步说明:
如图1所示,本发明具体实施过程和工作原理如下:
步骤(1)对应用中给定的度量空间数据集进行随机采样,得到样本数据;
步骤(2)对得到的样本数据进行支枢点选择,并据此将应用中给定的整个数据集(包括样本数据)从度量空间映射至向量空间;其中,支枢点选择的具体步骤包括:
2.1)在样本数据中找出离群点作为支枢点的候选集合;
2.2)根据支枢点的选择目标,对候选集合中的点进行增量式的贪心选择,得到支枢点集;
利用支枢点集将数据集从度量空映射至向量空间的具体步骤如下:
2.3)对于每一个在度量空间中的数据,计算其与步骤2.2)中得到的支枢点集中的每个支枢点之间的距离,并将求得的距离作为向量空间中各维度的坐标值,以得到度量空间数据在向量空间中的位置坐标。
步骤(3)利用样本数据构建kd树,得到叶子节点对应的空间划分;具体步骤如下:对步骤(1)得到的样本数据,构建kd树,得到的kd树中包含数据点个数相等的叶子节点,各叶子节点对应的空间区域即为空间划分的结果;这里需要注意的是kd树叶子节点的数目是提前指定的,与后续分布式系统中工作节点的数目相等且一一对应;下面以图2为例对kd树的构建进行说明,假定样本数据为{o1,o2,o3,…,o8}:
1)在一个随机选择的维度上,图2(a)中选到维度y,将所有的采样数据进行排序,进而将样本数据等分为a、b两个节点,即a={o1,o3,o5,o6}和b={o2,o4,o7,o8};
2)分别对a、b两个节点进行迭代划分,最终得到图2(b)所示的四个节点,即p1={o1,o6},p2={o3,o5},p3={o2,o4}和p4={o7,o8};
3)最终得到各叶子节点对应的空间划分,即为图2(b)中节点p1、p2、p3和p4对应的包围盒bb(p1)、bb(p2)、bb(p3)和bb(p4)。
步骤(4)根据步骤(3)得到空间划分,将应用中给定的度量空间数据集(包括样本数据)进行划分,并将划分后的数据分发到对应的工作节点,这里需要说明两点:
4.1)步骤(4)中所获得的数据划分互不相交,提升步骤(6)中使用的基于相交的匹配方法效率;
4.2)步骤(4)中所获得的子数据集大小相当,使得节点间负载大致相当,保证单个节点中的数据不至于过多,以致其成为性能瓶颈。
步骤(5)各个工作节点分别对分配到的数据进行处理,建立本地的m树索引,以加速后续查询任务的处理;将整个系统组织成如图3所示的树型结构:工作节点(图3所示a,b,c…,i,j节点)作为叶子节点,直接负责数据处理;管理节点(图3所示1,2,3,4,5节点)作为中间节点,负责管理子节点以及与上层进行通讯;根节点(图3所示r节点)负责管理整个分布式系统。
步骤(6)将用户的查询请求作为任务发布,各个节点判断、订阅查询范围与自己职责范围相交的任务,并在所有相关工作节点返回结果后,对结果进行整合并返回给用户;下面以图3为例,介绍系统对一个度量区域查询处理的过程:
6.1)工作节点e发布用户的查询请求,其对应管理节点3接收到任务后,基于相交的方法查看当前任务的查询区域与自己负责的数据范围之间的关系:
(1)若管理节点3发现自己负责的数据范围包含当前任务的查询区域,则在此分支内部即可得到查询的所有结果,此时在对应子工作节点订阅任务进行基于m树索引的最佳优先查询处理后,可以跳到步骤6.4);
(2)若管理节点3发现自己负责的数据范围不足以完成查询(即当前任务的查询区域超出其负责的数据范围),则如图3所示,向根节点发布任务,在监听根节点的其他管理节点也基于相交的方法判断、订阅在自己职责范围内的任务,图3的例子中管理节点1,2,4都订阅了当前任务进行处理;
6.2)管理节点3从根节点处获得订阅了自己发布任务的管理节点数量,构建阈值为4的计数器;
6.3)同时,各个订阅查询任务的节点开始进行查询处理,完成处理后将结果发送给管理节点3;
6.4)当管理节点3的计数器加满之后,即所有相关的工作节点返回的结果,管理节点3整理收到的数据结果返回给用户,完成查询。
值得注意的是,本发明给出的基于发布/订阅模式的分布式度量相似查询处理方法还可以支持度量k最近邻查询。k最近邻查询与区域查询的不同在于其初始时并没有一个可供判断查询区域的距离阈值。在本发明中的处理方式是:在工作节点发布k最近邻查询任务之前,在本地进行一次局部的k最近邻查询得到局部结果。因为全局k最近邻结果必然包含在局部k最近邻的范围中,所以可以用局部第k近邻与查询点之间的距离作为全局度量k最近邻查询范围的上界。经此处理后,度量k最近邻查询可以使用步骤(6)所述的度量区域查询处理方法进行处理。
- 还没有人留言评论。精彩留言会获得点赞!