基于非支配排序遗传算法的配电网规划建设方案设计方法与流程
本发明涉及配电网规划领域,更具体地,涉及一种基于非支配排序遗传算法的配电网规划建设方案设计方法。
背景技术:
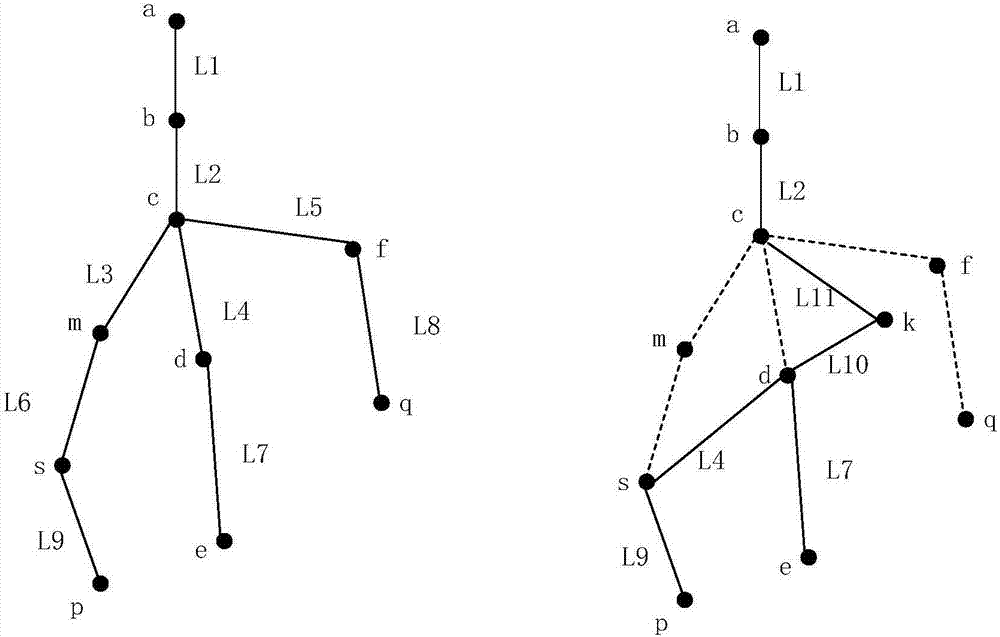
:城市电网是电力系统的重要组成部分,是电力系统的主要负荷中心,同时又是城市现代化建设的一项重要基础设施。城市电网规划既是电力系统规划的重要组成部分,也是城市规划的重要组成部分,合理进行城网规划是实现未来城市电网经济性和安全性的先决条件,可以获得很大的经济和社会效益。在对城市电网进行规划时,对于发展较成熟的地区,规划时的重点在于在现状电网分析的基础上对当前电网中问题的解决,因此应按照问题严重性和问题解决后带来的效益如何来安排各类项目的实施,推动网架的发展。对于未来发展空间较大,例如新区、园区等,往往在规划时会具备完善的目标网架设计,需要关注在如何建设各规划项目以从现状过渡到目标网架这一问题,而对于这一问题,目前研究较为缺少。在从现状电网发展为目标电网的过程中,为保证中间年网架的合理性,即满足安全性、可靠性等技术要求的同时要尽量保证建设和运行的经济性。因此,人工难以对建设方案进行制定,而必须借助计算机,采用新技术、新方法对配电网规划项目的自动生成和建设时序方案进行寻优。技术实现要素:本发明为克服上述现有技术所述的至少一种缺陷,提供一种基于非支配排序遗传算法的配电网规划建设方案设计方法。为解决上述技术问题,本发明的技术方案如下:一种基于非支配排序遗传算法的配电网规划建设方案设计方法,包括具体步骤如下:s1:规划项目的生成;以变电站为核心,分别对现状和目标网络进行梳理,将二者对比做差得到目标电网与现状电网二者的差异量,进而根据网架对比分析所得的差异,按照一定的项目划分原则自动生成从现状电网到目标电网的规划项目库;s2:项目建设时序自动优化设计;建立配电网规划的数学模型,以经济性、可靠性为目标,考虑电网运行的技术条件约束及实际建设投资等限制,采用带精英策略的非支配排序遗传算法(elitistnon-dominatedsortinggeneticalgorithm,nsga-ⅱ),对规划期内的项目实施时序进行自动寻优,辅助规划人员作出决策。在一种优选的方案中,在步骤s1中对目标及现状网架进行对比分析后,所得的网架差异包括增量、减量、变化量(更换)和变换量(移动)四种不同的情况。在一种优选的方案中,四种不同的网架差异类型将分别对应规划项目中的新建、拆除、改造和改接四种项目类型。在一种优选的方案中,在步骤s1中依据设备元件之间的联通关系,将连接在一起的设备元件差异分析后属性相同的设备元件归于同一项目之中进行规划项目类别的划分,进而对规划项目进行生成。在一种优选的方案中,在步骤s2中,为保证满足电网运行技术指标的同时使全规划周期的建设方案经济性、可靠性尽可能优化,建立了以经济性为目标和以可靠性为目标的配电网多目标动态负荷子系统确定性规划模型,以经济性为目标:主要考虑使配电网规划建设期内各阶段电网的投资及运行费用总和最小,目标函数的数学表达式为其中,n代表规划期总年数;k代表第k规划年;r0代表资金贴现率;u(k-1)代表第k-1规划年的网络扩展方案,也即该年所实施的项目集;代表第k-1规划水平年的网络扩建投资费用,其中np为该年实施的项目总数,ij为项目j的投资费用;对于新建类型的项目ij应等于项目j中所有新建元件的建设投资费用,对于改造类型的项目ij则等于新设备的建设投资费用减去旧设备的残值,对于拆除项目和线路改接项目认为没有投资建设费用,即ij=0;x(k)代表第k年的网络状态;co(x(k))按照u(k-1)扩展到x(k)后网络的运行费用;设单位电量的电价为λ,最大负荷利用小时数为τmax,线路i上的有功功率损耗为δpi,则有其中l(k)为第k规划水平年的线路集;第k规划水平年的缺电损失费用;其中τmax为最大负荷利用小时数,d(k)为该年供电需求未被满足的负荷的集合,pli为d(k)中某一负荷的缺电量。以可靠性为目标:主要考虑使配电网规划建设期内各阶段电网的可靠性水平评价最优,目标函数表达式如下:其中saidik为第k年的系统平均停电时间:在一种优选的方案中,在步骤s2中,将选择非支配排序遗传算法对所建立的配电网优化规划模型进行求解,其步骤如下:t1:编码方法:采用浮点数编码方式,设待实施的项目有n个,总规划年为k年,则基因编码为一组n个取值为[1,k]的实数变量;t2:初始种群生成:以待实施项目总数、总规划年数为输入,用随机的方法生成种群规模数的初始项目建设方案编码群体;每个个体,利用潮流计算程序和可靠性计算程序计算,得到如下三种数据:经济性参数、可靠性参数、约束条件违反次数。t3:个体间的快速非支配排序:根据以上三个参数对群体中的个体进行快速非支配排序;在决定个体间支配关系时,在以下情况下认为个体pi支配个体pj:当个体pi对应的解为可行解且个体pj对应的解不可行;当个体pi和pj对应的解均不可行,但pi对应的解总体对于约束条件的违反较pj轻;当个体pi和pj对应的解均为可行解,且pi支配个体pj;根据个体之间的支配关系判断结果,对于每个个体p可以得到的两个参数:群中支配个体p的个体数np,种群中被个体p支配的个体集合sp;根据这两个参数可以将整个种群中各个体分入不同的非支配层,同一层的个体具有相同的非支配序rank(p);t4:个体的拥挤度计算:非支配序为相同的个体经上一步骤被存储于同一集合中;对于每个集合内的个体计算每个个体的拥挤度;具体地,首先对于每个目标函数k,按照目标函数值的大小对集合内的个体进行排序;排序后在目标k下处于第i个位置的个体,其拥挤度用cdk(i[i,k])表示;若个体在排序后处于边界,则其拥挤度为无穷;若个体排在其他位置则拥挤度为:其中fk(i[i-1,k])和fk(i[i+1,k])分别为排在个体i之前和之后一位的个体的目标函数k的值,和分别为集合中的第k个目标函数的最大值和最小值;最终计算个体i的拥挤度cd(i)为各目标下拥挤度之和;t5:拥挤度选择算子:定义了拥挤度选择算子如下:当且仅当rank(pi)<rank(pj),或rank(pi)=rank(pj)且cd(pi)>cd(pj);也即:个体非支配序不同时,认为非支配序越低越优;非支配序相同时,认为拥挤度越大越优;t6:选择操作:采用锦标赛选择法,随机从种群中抽取一定个体,选取其中更好的一个放入matingpool中,重复此操作直至选出种群规模个个体;在生成第一代子群时,对于个体的比较直接依赖非支配排序后个体的非支配序大小;在生成非第一代子群时,对于个体的比较则依据拥挤度选择算子;t7:交叉操作:采用算数交叉的方法对选择操作后进入matingpool中的群体,随机选择,两两配对成组,按照交叉概率,则对个体进行交叉;t8:变异操作:采用均匀变异的方法,对交叉操作后得到的群体按照变异概率进行变异,对进行变异的个体随机确定变异的基因位置;对变异位置的编码ai,将其置为:其中和分别为基因位取值范围,γ为[0,1]范围内符合均匀概率分布的一个随机数。在一种优选的方案中,在步骤t1中,有五个待实施项目a、b、c、d、e(n=5)要在三年内完成(k=3)则编码可能为[1,3,2,2,1],表示项目a、e在第一年完成,项目b在第三年完成,项目c、d在第二年完成。与现有技术相比,本发明技术方案的有益效果是:一种基于非支配排序遗传算法的配电网规划建设方案设计方法,主要包括规划项目的生成和项目建设时序自动优化设计;借助计算机新技术对分别对现状和目标网络进行梳理,将二者对比做差得到目标电网与现状电网二者的差异量,进而根据网架对比分析所得的差异,按照一定的项目划分原则自动生成从现状电网到目标电网的规划项目库;采用基于非支配排序遗传算法的配电网建设时序方案进行寻优,通过对生物进化过程中选择、交叉和变异机理的模仿来完成对问题最优解的自适应搜索,具有较强鲁棒性和隐含的并行性,较其他传统优化算法具有更独特和优越的性能。本发明满足了安全性和可靠性等技术要求,保证了中间年网架的合理性及建设和运行的经济性。附图说明图1为本发明实施例1的现状与目标电网对比分析流程图。图2为本发明实施例1的网架对比项目生成简例。图3为本发明实施例1的以目标网架为导向的规划项目自动生成方法总流程图。图4为本发明实施例1的简单遗传算法的基本流程图。图5为本发明实施例1的nsga-ⅱ算法的流程图。具体实施方式附图仅用于示例性说明,不能理解为对本专利的限制;为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。下面结合附图和实施例对本发明的技术方案做进一步的说明。实施例1一种基于非支配排序遗传算法的配电网规划建设方案设计方法,包括具体步骤如下:s1:规划项目的生成;以变电站为核心,分别对现状和目标网络进行梳理,将二者对比做差得到目标电网与现状电网二者的差异量,进而根据网架对比分析所得的差异,按照一定的项目划分原则自动生成从现状电网到目标电网的规划项目库;两电网对比分析的基本比较单元为网络中的各设备元件。对于现状电网中所包含的每一设备,都首先在目标电网的设备列表中对其进行搜索,同时对于搜索得到的元件进行进一步的参数对比,其中若设备元件为交流线路,则需对比参数包括线路的导线型号及起终厂站,对于其他设备则只对比设备模型型号。如图1对比分析的流程可见,经网架对比分析后,现状和目标电网中的任一设备都将会被归类为以下五类中的一种:(1)增量:该设备在现状电网中不存在,而在目标电网中存在;(2)减量:该设备在现状电网中存在,而在目标电网中不存在;(3)变化量(更换):该设备在现状和目标电网中均存在,但设备模型型号且仅型号发生了变化;(4)变化量(移动):仅针对架空线路,线路在现状和目标电网中均存在但其起终厂站参数且仅此参数发生了变化;(5)非差异量:该设备在现状和目标电网中均存在,且所有参数完全一致。s2:项目建设时序自动优化设计;建立配电网规划的数学模型,以经济性、可靠性为目标,考虑电网运行的技术条件约束及实际建设投资等限制,采用带精英策略的非支配排序遗传算法(elitistnon-dominatedsortinggeneticalgorithm,nsga-ⅱ),对规划期内的项目实施时序进行自动寻优,辅助规划人员作出决策。在具体实施过程中,在步骤s1中对目标及现状网架进行对比分析后,所得的网架差异包括增量、减量、变化量(更换)和变换量(移动)四种不同的情况。在具体实施过程中,四种不同的网架差异类型将分别对应规划项目类别划分中的新建、拆除、改造和改接四种项目类别。(1)新建项目:主要来源于网络对比分析中所得到的增量,例如某处环网柜的新建等;(2)拆除项目:主要来源于网络对比分析中所得到的减量,例如,一般对应在对现状电网梳理后对于某些线路的拆除;(3)改造项目:主要来源于网络对比分析中所得到的变化量(更换),例如将某两节点间的线路导线更换其他型号;(4)改接项目:主要来源于网络对比分析中所得到的变化量(移动),实际特指线路的改接,即指现状电网中的某条线路(同一段导线)在被架设在了目标网架中不同的位置。在具体实施过程中,在步骤s1中依据设备元件之间的联通关系,将连接在一起的设备元件差异分析后属性相同的设备元件归于同一项目之中进行规划项目类别的划分,进而对规划项目进行生成。如图2所示,设图中左侧为现状网架中的某馈线,右侧为目标网架中对应的馈线,二者对应左右侧的设备信息分别见表1和表2,图中虚线代表被拆除线路。表1现状电网设备信息表线路名称导线型号线路起点线路终点l1yjv22-3×70abl2yjv22-3×70bcl3yjv22-3×70cml4yjv22-3×70cdl5yjv22-3×70cfl6yjv22-3×70msl7yjv22-3×70del8yjv22-3×70fql9yjv22-3×70sp表2现状电网设备信息表按照所提中的网络对比分析方法对以上网络进行分析,将得到各现状和目标网架中的各设备的差异类别如下:表3网架对比分析后设备差异类别表线路名称线路起终点类别线路名称线路起终点类别l1a-b非差异量l7d-e非差异量l2b-c变化量(更换)l8f-q减量l3c-m减量l9s-p非差异量l4c-d变化量(移动)l10d-k增量l5c-f减量l11c-k增量l6m-s减量通过对上表遍历可以寻找具有电气连接且网架差异类别相同的各设备,从而最终生成项目如下:表4规划项目列表项目编号项目名称包含设备项目类型1c-s线路拆除l3、l6拆除项目2c-q线路拆除l5、l8拆除项目3导线l4改接l4改接项目4c-d线路建设l10、l11新建项目5b-c线路改造l2改造项目为使项目自动生成的方法解释地更清晰,以上例子中只是对网络中的交流线路进行了分析,对于图2中的各节点在实际规划数据输入中实际是杆塔、环网柜、分接箱等,在最终生成的项目中也将包含这些设备。除项目的类型外,还主要关注生成项目的成本,在对新建/改造项目计算成本时将计算项目包含的所有设备的成本价格之和,电网规划时对于线路的拆除项目并无专项资金,故此类项目成本为零。此外,自动生成的规划项目库将作为现状电网到目标电网过渡方案生成的原始输入,而在考虑电网发展过程时各接线模式或者说网络中的联络关系是如何建设的十分值得关注。因此,本发明在上述项目生成方式的基础上将网络中的联络线/联络开关单独提取出来,并生成独立的联络建设项目。以目标网架为导向的规划项目自动生成方法总流程如0所示。在具体实施过程中,在步骤s2中,在对配电网规划项目建设时序方案进行优化设计时,需关注项目的实施时序对于整个规划建设方案优劣的影响,为保证满足电网运行技术指标的同时使全规划周期的建设方案经济性、可靠性尽可能优化,建立了以经济性为目标和以可靠性为目标的配电网多目标动态负荷子系统确定性规划模型,(1)模型目标函数以经济性为目标:主要考虑使配电网规划建设期内各阶段电网的投资及运行费用总和最小,目标函数的数学表达式为其中,n代表规划期总年数;k代表第k规划年;r0代表资金贴现率;u(k-1)代表第k-1规划年的网络扩展方案,也即该年所实施的项目集;代表第k-1规划水平年的网络扩建投资费用,其中np为该年实施的项目总数,ij为项目j的投资费用;对于新建类型的项目ij应等于项目j中所有新建元件的建设投资费用,对于改造类型的项目ij则等于新设备的建设投资费用减去旧设备的残值,对于拆除项目和线路改接项目认为没有投资建设费用,即ij=0;x(k)代表第k年的网络状态;co(x(k))按照u(k-1)扩展到x(k)后网络的运行费用;设单位电量的电价为λ,最大负荷利用小时数为τmax,线路i上的有功功率损耗为δpi,则有其中l(k)为第k规划水平年的线路集;第k规划水平年的缺电损失费用;其中τmax为最大负荷利用小时数,d(k)为该年供电需求未被满足的负荷的集合,pli为d(k)中某一负荷的缺电量。以可靠性为目标:主要考虑使配电网规划建设期内各阶段电网的可靠性水平评价最优,目标函数表达式如下:其中saidik为第k年的系统平均停电时间:(2)规划模型的约束条件考虑项目背景以及配电网实际运行要求,以上优化问题应满足的约束条件包括:①网络连通性:对于任意规划年所形成的网络,网络中的负荷节点都必须与配电网络相连,有电源为该负荷供电。②网络辐射性:根据配电网闭环设计开环运行的要求,对于任意规划年所形成的网络均应满足网络辐射性的约束条件。③潮流约束:对于任意规划年,所形成网络中的任意线路i都必须满足线路的潮流约束,即应有pi≤pimax,其中pimax为线路i上的所允许的最大潮流限值。④电压约束:对于任意规划年,所形成网络中的任意节点j的电压都必须满足网络节点电压的约束,即应有ujmin≤uj≤ujmax,其中ujmin和ujmax分别为节点j运行电压的上下限⑤联络项目约束:在生成项目时,网络中的联络线/联络开关被单独提取出形成了联络项目。而此类项目的建设必须依托于其所联络的馈线中的至少一个,因此所得配电网规划建设方案必须满足所有联络项目的建设均发生在其所连接的至少一条馈线的对应项目已实施完毕之后这一约束。⑥一次投资费用约束:对于各规划年均有ctmin≤ct(u(k-1))≤ctmax,其中,ctmin和ctmax分别为某一规划年的一次投资建设费用上下限额,其数值由规划人员设定。本实施例中将选择遗传算法对所建立的配电网优化规划模型进行求解。遗传算法的基本思想源于的达尔文的进化论和mendel的遗传学说,在利用遗传算法对优化问题进行求解时实际就是通过对生物进化过程中选择、交叉和变异机理的模仿来完成对问题最优解的自适应搜索。遗传算法具有较强鲁棒性和隐含的并行性,在解决配电网的规划这一多变量、多约束、非线性的复杂优化问题时,遗传算法较其他传统优化算法具有更独特和优越的性能。简单遗传算法(simplegeneticalgorithm,sga)的基本流程如0所示,主要包括问题编码、适应度函数设计、选择算子设计、交叉算子设计、变异算子设计等几个步骤。sga可以被用于求解在某一单目标,如经济性或可靠性,下的配电网优化规划问题,但所得的解显然仅是某一设定目标下的最优解,却无法帮助规划人员根据需要权衡经济性和可靠性选出最合适的方案同时,针对两个不同指标的两次遗传算法计算也极大的增加了规划建设方案的计算时间。在对规划建设方案进行寻优时应将可靠性和经济性一并考虑,按照多目标优化(multiobjectiveoptimization)问题进行求解。在解决moo问题时,常使用对多个目标进行线性加权的weightedsummethod,但这样所得的解对各目标权重的设置依赖性很大,且二者关系复杂难以控制,实质上也是将多目标转换成了单目标的问题。因此,本发明将采用基于pareto排序的多目标遗传算法,在这种算法中各优化目标将被同等对待,所求得的解也不再是唯一解而是满足一定定义的所谓pareto最优解集,可供规划人员根据实际需要在这一解集中选取最终的方案,具有更好的工程应用价值。(1)pareto最优解的概念对于多目标最小化的问题:min{f1(x),f1(x),…,fn(x)}设问题的决策变量空间为s,对于任意两个决策变量x1和x2,且x1,x1∈s,对于任意的i∈{1,2,…,n}都有fi(x1)≤fi(x2),且存在i∈{1,2,…,n}使得fi(x1)<fi(x2)成立,则称决策变量x1支配x2,记为对于多目标问题的一个可行解x∈s,当且仅当s中不存在y使即x是s中的非支配个体,称x为多目标优化问题的pareto最优解,也称非支配解。简言之,所谓pareto最优解就是不存在比这个方案至少在一个目标下更好同时又保证其他目标不必此解差的方案。通常多目标优化问题的解是一个解集paretooptimalset,对于此解集中的解的选择需提交人工解决。基于pareto排序的多目标遗传算法就是致力于求出这一pareto最优解集,且应尽可能保证解的丰富性。(2)nsga-ii算法带精英策略的非支配排序遗传算法(nsga-ⅱ)主要是在sga的基础上进行了如下三方面的改进:①nsga-ⅱ算法在通过遗传操作生成子代种群之前根据个体之间的支配关系对种群进行了分层,即快速非支配排序过程;②通过引入个体拥挤度提高了种群的多样性;③设计了拥挤度选择算子对父代和子代的混合种群进行操作保留了种群中的精英个体。如图5所示为nsga-ⅱ算法步骤流程:t1:编码方法:采用浮点数编码方式,设待实施的项目有n个,总规划年为k年,则基因编码为一组n个取值为[1,k]的实数变量;t2:初始种群生成:以待实施项目总数、总规划年数、需输出方案组数为输入,用随机的方法生成种群规模数的初始项目建设方案编码群体;每个个体,利用潮流计算程序和可靠性计算程序计算,得到如下三种数据:经济性参数、可靠性参数、约束条件违反次数。t3:个体间的快速非支配排序:根据以上三个参数对群体中的个体进行快速非支配排序;在决定个体间支配关系时,在以下情况下认为个体pi支配个体pj:当个体pi对应的解为可行解且个体pj对应的解不可行;当个体pi和pj对应的解均不可行,但pi对应的解总体对于约束条件的违反较pj轻;当个体pi和pj对应的解均为可行解,且pi支配个体pj;根据个体之间的支配关系判断结果,对于每个个体p可以得到的两个参数:群中支配个体p的个体数np,种群中被个体p支配的个体集合sp;根据这两个参数可以将整个种群中各个体分入不同的非支配层,同一层的个体具有相同的非支配序rank(p);t4:个体的拥挤度计算:非支配序为相同的个体经上一步骤被存储于同一集合中;对于每个集合内的个体计算每个个体的拥挤度;具体地,首先对于每个目标函数k,按照目标函数值的大小对集合内的个体进行排序;排序后在目标k下处于第i个位置的个体,其拥挤度用cdk(i[i,k])表示;若个体在排序后处于边界,则其拥挤度为无穷;若个体排在其他位置则拥挤度为:其中fk(i[i-1,k])和fk(i[i+1,k])分别为排在个体i之前和之后一位的个体的目标函数k的值,和分别为集合中的第k个目标函数的最大值和最小值;最终计算个体i的拥挤度cd(i)为各目标下拥挤度之和;t5:拥挤度选择算子:定义了拥挤度选择算子如下:当且仅当rank(pi)<rank(pj),或rank(pi)=rank(pj)且cd(pi)>cd(pj);也即:个体非支配序不同时,认为非支配序越低越优;非支配序相同时,认为拥挤度越大越优;t6:选择操作:采用锦标赛选择法,随机从种群中抽取一定个体,选取其中更好的一个放入matingpool中,重复此操作直至选出种群规模个个体;在生成第一代子群时,对于个体的比较直接依赖非支配排序后个体的非支配序大小;在生成非第一代子群时,对于个体的比较则依据拥挤度选择算子;t7:交叉操作:采用算数交叉的方法对选择操作后进入matingpool中的群体,随机选择,两两配对成组,按照交叉概率,则对个体进行交叉;t8:变异操作:采用均匀变异的方法,对交叉操作后得到的群体按照变异概率进行变异,对进行变异的个体随机确定变异的基因位置;对变异位置的编码ai,将其置为:其中和分别为基因位取值范围,γ为[0,1]范围内符合均匀概率分布的一个随机数。在具体实施过程中,在步骤t1中,有五个待实施项目a、b、c、d、e(n=5)要在三年内完成(k=3)则编码可能为[1,3,2,2,1],表示项目a、e在第一年完成,项目b在第三年完成,项目c、d在第二年完成。相同或相似的标号对应相同或相似的部件;附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1