一种基于在线数据和因子分析模型的智能源类识别方法与流程
本发明涉及大气颗粒物源解析领域,具体涉及一种因子分析模型的智能源识别方法。
背景技术:
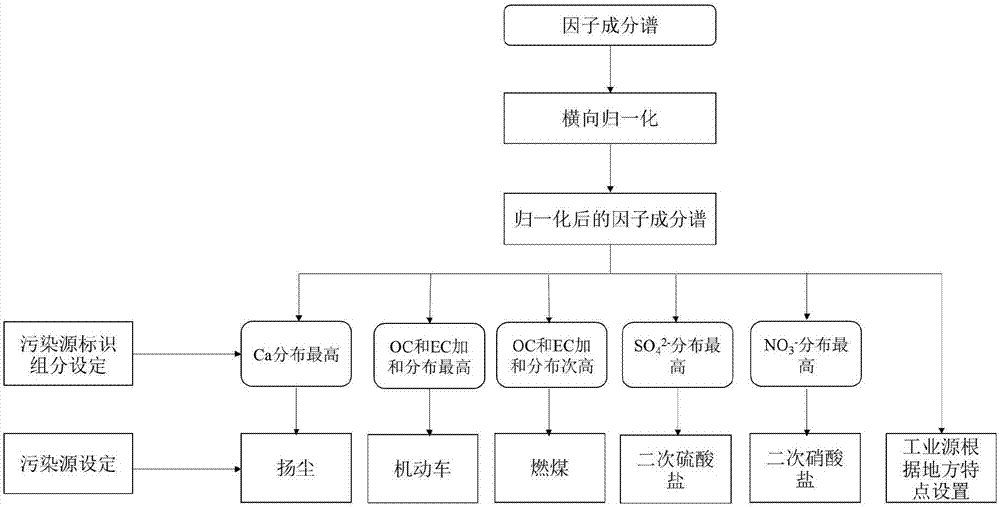
:颗粒物浓度增加是灰霾等污染过程产生的主要内在因素,在不利的气象条件下,由pm2.5污染引发的我国区域性重灰霾持续时间可长达数天(5~10天),持续的重污染过程也成为城市环境空气质量、大气能见度和居民人体健康的重大威胁。对于重污染天气,应急预案的制订应该基于科学分析和污染源解析,找准城市重污染天形成的根源和关键环节。这就需要我们对重污染过程成因快速进行精确解析和对颗粒物来源进行快速、准确溯源,为重污染天气的应急预案提供科学依据,从而有效控制城市颗粒物污染尤其是重污染过程中的颗粒物。大气颗粒物源解析能为制定城市大气颗粒物污染控制对策提供不可缺少的科学依据,根据源解析结果,能帮助环境决策者们提出更具有针对性、科学性和合理性的颗粒物污染防治政策。传统的基于受体模型的颗粒物源解析是通过滤膜采样、离线分析技术进行分析的。这种长时间、低时间分辨率(一般为24小时)的分析技术不能满足在较短时间内取得足够的样品来解析污染源对颗粒物的影响。目前,利用正定矩阵因子分析模型结合在线监测数据建立的在线源解析技术能快速的解析重污染天气过程中颗粒物的主要来源。但是正定矩阵因子分析模型是基于数学意义提取的公因子,该模型不能自动给出公因子代表的源类,需要根据人为经验判断公因子代表的源类,因此,目前的在线源解析技术需要结合经验判断才能得到污染源对对颗粒物的贡献和影响,无法在线源解析技术的自动化。技术实现要素:本发明的目的是解决现有因子分析模型很难自动识别污染源,无法使在线源解析技术的自动化的问题,基于较高时间分辨率的测量仪器来测量受体源解析模型中需要的各种数据,结合因子分析模型,提供了一种智能识别源类的方法。本发明通过对污染源的成分谱特征进行研究,总结规律,首次采用横向归一化因子成分谱的方法,得到污染源标识组分在各个因子中的分布特征,再根据污染源及其标识组分的设定规则,将其转化成计算机语言嵌套到模型中,最终建立污染源的智能识别方法,实现在线源解析技术的自动化。本发明提供的基于在线数据和因子分析模型的智能源类识别方法,采用的技术方案如下:第1步.利用在线观测仪器观测颗粒物的化学组分,构建多组分在线数据,输入到因子分析模型;输入的在线数据包括水溶性离子,碳组分,元素和颗粒物浓度;在线数据输入到正定矩阵因子分析实时源解析模型(即因子分析模型)。颗粒物浓度由颗粒物在线监测仪器测量pm2.5浓度;水溶性离子由在线离子色谱分析仪测量,包括nh4+、na+、k+、ca2+、mg+、so42-、no3-和cl-;碳组分由半连续oc/ec仪器测量,包括oc和ec;元素由重金属在线分析仪监测,包括k、ca、v、cr、mn、fe、co、ni、cu、zn、ga、as、se、ag、cd、sn、sb、ba、au、hg、tl、pb和bi组分。第2步.设置模型参数;所述的因子分析模型是正定矩阵因子分析实时源解析模型,需要输入因子分析模型的参数包括两个,第一参数是分析仪器检测限,另一个参数是输入数据中的部分不确定性数据,根据具体的采样和分析情况来设定,模型计算之前,需要同时输入这两个参数。第3步.选择进行计算的样品、化学组分、时间分辨率;根据计算需求,选择要分析的样品和时间分辨率;根据需要识别的源类和数据的可靠性,选择合适的化学组分。第4步.设定模型需要提取出的因子个数,因子个数代表可能的污染源类数量,根据需要观测点位的实际情况设定,且因子设定的个数小于输入数据中化学组分的数量。因子个数设定完成后,进行模型计算,提取因子,并计算因子贡献。第5步.设定源识别条件,利用因子智能识别技术识别因子;所述的设定源识别条件包括两个设定,一个是污染源的设定,另一个是污染源标识组分的设定;因子分析模型根据以下步骤,将因子识别为具体的源类,具体包括如下步骤:(a)在线数据经因子分析模型计算得到因子成分谱;(b)将因子成分谱进行归一化得到归一化后的因子成分谱,即对于每一种化学组分,它在各因子的值加和等于1;(c)设定污染源及其标识组分,第一污染源设定为二次硫酸盐,标识组分设定为so42-,第二个污染源设定为二次硝酸盐,标识组分设定为no3-;第三个污染源设定为扬尘,标识组分设定为ca;第四个污染源设定为机动车,标识组分设定为oc和ec;第五个污染源设定为燃煤,标识组分设定为oc和ec。工业源的标识组分根据地方特点设置;(d)根据归一化因子成分谱中标识组分在各个因子中的分布特征,将因子识别为具体的源类;所有因子中,so42-值最大的因子识别为二次硫酸盐,no3-值最大的因子识别为二次硝酸盐,ca值最大的因子识别为扬尘,oc和ec加和值最大的因子识别为机动车,oc和ec加和分布第二大的因子识别为燃煤,工业源根据地方特点设置(例如工业源主要是钢铁行业,则标识组分为fe)。本发明的优点和有益效果:与因子分析模型相比,本发明能实现污染源的自动识别。通过智能识别,减少人为因素对源解析结果的干扰,提高模型的运算时效性,实现在线源解析技术的自动化,便于在线源解析技术的推广应用。附图说明图1示出了自动源识别的流程图。具体实施方式实施例1本实例利用天津市的在线监测数据和因子分析模型进行污染源的识别,具体步骤如下:1.构建因子分析模型输入数据。所述的输入数据包括水溶性离子,碳组分,元素,颗粒物浓度。利用颗粒物在线监测仪器测量pm2.5浓度。利用半连续oc/ec仪器测量碳组分,包括oc和ec的浓度。利用在线离子色谱分析仪测量水溶性离子,包括nh4+、na+、mg2+、s042-、no3-、cl-的浓度。利用重金属在线分析仪监测元素,包括k、ca、cr、mn、fe、ni、cu、zn、as、se、ag、cd、ba、hg、pb的浓度。(每次输入数据的组分类别根据实际监测数据会有一定变化)。四台监测仪器同时采集22天的样品,监测的数据时间分辨率为1小时。2、输入因子分析模型的参数。其中包括两个参数,一个是与分析仪器检测限相关的参数,设置为0.2,另一个是与输入数据不确定性相关的参数,设置为0.34。这两个参数要根据实际分析仪器的检测限和输入数据的不确定性进行设置。3、输入识别的因子数。模型提取的因子个数设置为4。4、选择计算的样品、化学组分、时间分辨率。选择上述步骤1中的所有输入数据和化学组分进行计算。时间分辨率为1小时,开始运算。提取因子和计算因子贡献,提取的因子如表1所示。如无智能识别技术,则需要根据经验人为的判断因子代表的源类。根据经验判断的结果如下:因子1中oc、ec含量最高,可认为是机动车源;因子2中oc、ec-等相对含量较高,代表燃煤源,因子3代表二次硫酸盐和二次硝酸盐的混合源,硫酸盐、硝酸盐是该因子的主要组分;因子4中ca的含量较高,是扬尘。表1源解析因子成分谱化学组份因子1因子2因子3因子4cl-0.000.000.470.19no3-0.330.518.603.85so42-0.870.6511.990.07na+0.030.040.100.07nh4+0.160.008.700.00mg2+0.000.000.000.06ca0.080.000.000.20k0.150.520.000.03cr0.000.000.000.00mn0.010.020.000.00fe0.160.280.090.08ni0.000.000.000.00cu0.000.010.000.00zn0.020.150.000.00as0.000.010.000.00se0.000.000.000.00ag0.000.000.000.00cd0.000.000.000.00ba0.010.010.000.00hg0.000.000.000.00pb0.010.050.010.00ec3.723.550.940.15oc1.210.800.450.305、设定因子识别条件,包括两个设定,一个是污染源的设定,另一个是污染源标识组分的设定。正定矩阵因子分析实时源解析模型根据以下步骤,将因子识别为具体的源类,具体包括如下步骤如下:(a)在线数据经因子分析模型计算得到因子成分谱(表1);(b)将因子成分谱归一化得到归一化后的因子成分谱,即对于每一种化学组分,它在各因子的值加和等于1;污染源标识组分在各个因子中的分布特征见表2:表2横向归一化后的源解析因子成分谱化学组份因子1因子2因子3因子4cl-0.000.000.710.29no3-0.020.040.650.29so42-0.060.050.880.01na+0.130.170.420.29nh4+0.020.000.980.00mg2+0.000.000.001.00ca0.290.000.000.71k0.210.740.000.04cr0.000.000.000.00mn0.330.670.000.00fe0.260.460.150.13ni0.000.000.000.00cu0.001.000.000.00zn0.120.880.000.00as0.001.000.000.00se0.000.000.000.00ag0.000.000.000.00cd0.000.000.000.00ba0.500.500.000.00hg0.000.000.000.00pb0.140.710.140.00ec0.440.420.110.02oc0.440.290.160.11(c)设定污染源及其标识组分,第一污染源设定为二次硫酸盐,标识组分设定为so42-,第二个污染源设定为二次硝酸盐,标识组分设定为no3-;第三个污染源设定为扬尘,标识组分设定为ca;第四个污染源设定为机动车,标识组分设定为oc和ec;第五个污染源设定为燃煤,标识组分设定为oc和ec。本次采样点无工业源,故在此不设置工业源;(d)根据归一化因子成分谱中标识组分在各个因子中的分布特征(表2),将因子识别为具体的源类;所有因子中,so42-值最大的因子(因子3)识别为二次硫酸盐,no3-值最大的因子(因子3)识别为二次硝酸盐,ca值最大的因子(因子4)识别为扬尘,oc和ec加和值最大的因子(因子1)识别为机动车,oc和ec加和分布第二大的因子(因子2)识别为燃煤。根据上述方法,识别因子。结果如表3:表3因子识别结果源因子二次硫酸盐因子3二次硝酸盐因子3扬尘因子4机动车因子1燃煤因子2因子智能识别技术得到的结果与人为经验判断的结果一致,说明,因子智能识别技术能正确的识别因子代表的源类。实施例2本实例利用天津市的在线监测数据和因子分析模型进行污染源的识别,具体步骤如下:1.构建因子分析模型输入数据。所述的输入数据包括水溶性离子,碳组分,元素,颗粒物浓度。利用颗粒物在线监测仪器测量pm2.5浓度。利用半连续oc/ec仪器测量碳组分,包括oc和ec的浓度。利用在线离子色谱分析仪测量水溶性离子,包括nh4+、na+、mg2+、s042-、no3-、cl-的浓度。利用重金属在线分析仪监测元素,包括ca、mn、fe、cu、zn、as、se、ba、hg、pb的浓度。(每次输入数据的组分类别根据实际监测数据会有一定变化)。四台监测仪器同时采集30天的样品,监测的数据时间分辨率为1小时。2、输入因子分析模型的参数。其中包括两个参数,一个是与分析仪器检测限相关的参数,设置为0.1,另一个是与输入数据不确定性相关的参数,设置为0.34。这两个参数要根据实际分析仪器的检测限和输入数据的不确定性进行设置。3、输入识别的因子数。模型提取的因子个数设置为4。4.选择计算的样品、化学组分、时间分辨率。选择所有输入数据和化学组分进行计算。时间分辨率为1小时,开始运算。提取因子和计算因子贡献。提取的因子如表4所示,如无智能识别技术,则需要根据经验人为的判断因子代表的源类。根据经验判断的结果如下:因子1中oc、ec含量最高,可认为是机动车源;因子2中ca、fe等地壳元素的含量较高,是扬尘;因子3代表二次硫酸盐和二次硝酸盐的混合源,硫酸盐、硝酸盐是该因子的主要组分;因子4中oc、ec等相对含量较高,代表燃煤源,表4源解析因子成分谱化学组份因子1因子2因子3因子4cl-3.693.270.080.10no3-0.000.0020.060.00so42-4.630.005.510.00na+0.000.120.700.44nh4+6.762.192.010.00mg2+0.000.000.130.15ca0.000.980.000.00mn0.020.040.010.00fe0.001.000.040.00cu0.010.030.000.00zn0.140.190.000.00as0.010.010.000.00se0.000.000.000.00ba0.000.050.010.00hg0.000.000.000.00pb0.040.060.010.00ec13.590.000.006.05oc4.230.000.001.505、设定因子识别条件,包括两个设定,一个是污染源的设定,另一个是污染源标识组分的设定。正定矩阵因子分析实时源解析模型根据以下步骤,将因子识别为具体的源类,具体包括如下步骤如下:(a)在线数据经因子分析模型计算得到因子成分谱(表4);(b)将因子成分谱归一化得到归一化后的因子成分谱,即对于每一种化学组分,它在各因子的值加和等于1;污染源标识组分在各个因子中的分布特征见见表5:表5横向归一化后的源解析因子成分谱化学组份因子1因子2因子3因子4cl-0.520.460.010.01no3-0.000.001.000.00so42-0.460.000.540.00na+0.000.100.560.35nh4+0.620.200.180.00mg2+0.000.000.460.54ca0.001.000.000.00k0.290.570.140.00cr0.000.960.040.00mn0.250.750.000.00fe0.420.580.000.00ni0.500.500.000.00cu0.000.000.000.00zn0.000.830.170.00as0.000.000.000.00se0.360.550.090.00ag0.690.000.000.31cd0.740.000.000.26(c)设定污染源及其标识组分,第一污染源设定为二次硫酸盐,标识组分设定为so42-,第二个污染源设定为二次硝酸盐,标识组分设定为no3-;第三个污染源设定为扬尘,标识组分设定为ca;第四个污染源设定为机动车,标识组分设定为oc和ec;第五个污染源设定为燃煤,标识组分设定为oc和ec。本次采样点无工业源,故在此不设置工业源(d)根据归一化因子成分谱中标识组分在各个因子中的分布特征(表5),将因子识别为具体的源类;所有因子中,so42-值最大的因子(因子3)识别为二次硫酸盐,no3-值最大的因子(因子3)识别为二次硝酸盐,ca值最大的因子(因子4)识别为扬尘,oc和ec加和值最大的因子(因子1)识别为机动车,oc和ec加和分布第二大的因子(因子2)识别为燃煤。根据上述方法,识别因子。结果如表6:表6因子识别结果源因子二次硫酸盐因子3二次硝酸盐因子3扬尘因子2机动车因子1燃煤因子4因子智能识别技术得到的结果与人为经验判断的结果一致,说明,因子智能识别技术能正确的识别因子代表的源类。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1