一种链接器快速进行Overlay的方法与流程
本发明属于编译器技术领域,特别涉及一种链接器进行overlay的方法。
背景技术:
链接器属于ide(integrateddevelopmentenvironment)的重要组成部分。由于链接器功能复杂,各厂家指令集也不尽相同。其中主流8位指令集有cisc类型的51指令集,risc类型的avr指令集、pic指令集等。链接器需要根据不同的指令集特点快速高效的生成目标程序,随之的链接器设计技术包含重定位算法、overlay算法、代码修改算法等。
如专利申请201110305029.7公开了一种具有生存性的overlay网络构建方法,使用基于重叠惩罚思想的路径选择算法来为每个节点对选择多条能够满足业务需求的路径,将这些路径分为工作路径和保护路径。工作路径和保护路径中的节点和链路为每个节点对建立具有生存性的overlay层虚拓扑。使用重叠惩罚思想,使得工作路径和保护路径具有很大的相异性,由此可以保证overlay网络中路径的差异性,使得在网络故障发生之后,能够保证保护路径的替换成功率。这样,通过本发明中构造的overlay网络,使得对可靠性要求较高的业务层和底层网络中具有很好的映射关系,根据overlay网络中提供的相异路径可以保证在网络发生故障时,业务的快速倒换到满足其qos的传输路径中,从而提高网络的生存性。
随着芯海片上系统(systemonchip)技术的日益成熟,低端8位mcu指令集越来越完善和稳定,急需一个高效快速的链接器提高程序开发效率。
通过对目前普遍采用overlay算法进行分析,以
技术实现要素:
基于此,因此本发明的首要目地是提供一种链接器快速进行overlay的方法,该方法可以让程序员安排程序的不同部分来分享相同的内存,当程序的某一部分被其他部分调用时可以按需要加载,从而提高ram的利用率。
本发明的另一个目地在于提供一种链接器快速进行overlay的方法,该方法基于拓扑分析算法(tba)进行快速overlay,能够提高链接器overlay速度和效率。
为实现上述目的,本发明的技术方案为:
一种链接器快速进行overlay的方法,该方法使用静态分析方法可以得到程序的函数调用图,函数调用图是一个有向图g(v,e),其中v是节点的集合,e是有向边的集合,每个节点表示一个函数,每条有向边表示它的端点对应的两个函数间存在调用关系(从调用者指向被调用者),图中的任何一条路径代表一条函数调用链;其次,基于fcg的拓扑排序,确定每个函数的私有数据段的全局地址;然后,计算段内每个符号的全局地址,并根据重定位表更新对这些符号的引用。
进一步,所述的方法,其实现的具体流程为:
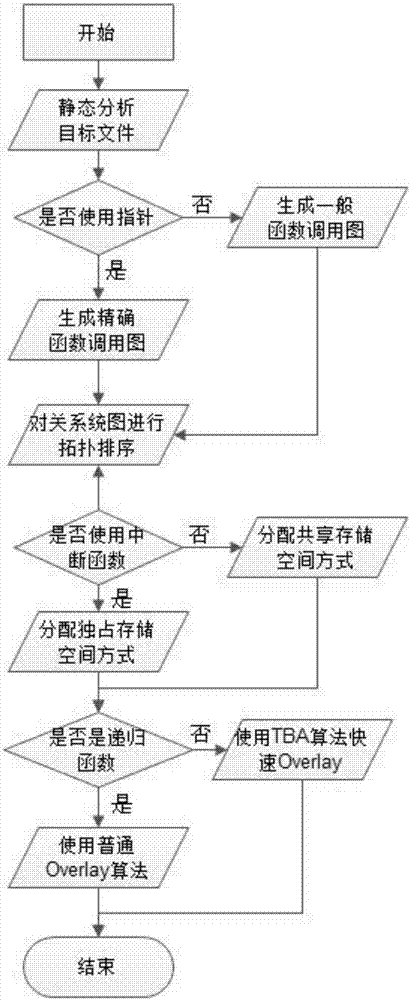
101、开始,静态分析目标文件;
102、生成函数调用图;
生成函数调用图包括两种,一种是不使用地址指针生成一般函数调用图,另一种是使用地址指针生成精确函数调用图。
进一步,生成函数调用图的算法:对于每个函数f扫描其语句,如果有函数调用语句,就将被调函数加入到f的调用函数集合;如果函数调用语句中操作的不是函数名,而是函数指针,就通point_to(p)返回指针变量p可能指向的函数集合。函数point_to依赖于指针分析。
103、对函数调用图进行拓扑排序;
基于拓扑排序是确定各函数的私有数据段的起始地址。首先,对fcg中的所有函数进行拓扑排序,得到函数的任意一个拓扑序列;然后,依次取出拓扑序列中的函数f,如果f是第一个函数main,那么其数据段的起始地址为0,并记录其数据段的结束地址的后一个地址addr(即起始地址+数据段大小,称为f的后继地址);然后,将序偶(addr,main)加入到已处理函数列表allocfuncs(该列表根据序偶中的后继地址从大到小排序);如果f不是第一个函数,那么在allocfuncs中按顺序搜索,直到找到一个序偶(nend,g)满足g调用f(除了第一个函数main,其余函数都能找到这样的序偶);再将nend分配给g的数据段的起始地址,最后将新数据段的后继地址(nend+g的数据段大小)加入到allocfuncs。
然后,根据分配算法的结果,更新重定位表,以及代码中对这些函数私有符号的引用地址,先扫描私有数据段中的所有符号,将符号在段内的偏移量加上所在段的全局地址,得到该符号的全局地址;再根据重定位表,更新代码中对这些符号的引用。
104、判断是否使用中断函数;
105、若使用中断函数,则分配独占空间存储;若不使用中断函数,则分配共享空间存储;
106、判断是否是递归函数;
107、是递归函数,则使用普通的overlay算法,不是递归函数,则使用tba算法快速overlay。
本发明所实现的快速进行overlay的方法,基于拓扑分析算法(tba)进行快速overlay,可以让程序员安排程序的不同部分来分享相同的内存,当程序的某一部分被其他部分调用时可以按需要加载,从而提高ram的利用率,提高链接器overlay速度和效率。
传统overlay算法注重效率的同时,往往速度不够快,导致编译时间较长。在进行大型项目的开发过程中时,这点尤其明显。优化后的基于快速拓扑分析算法(tba)能够提高overlay30%以上的速度。
附图说明
图1是现有技术所实现程序对应的函数调用图。
图2是本发明所实现的流程图。
图3是本发明所实现的算法地址分配示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
使用静态分析方法可以得到程序的函数调用图(functioncallgraph,fcg)。函数调用图是一个有向图g(v,e),其中v是节点的集合,e是有向边的集合。每个节点表示一个函数,每条有向边表示它的端点对应的两个函数间存在调用关系(从调用者指向被调用者)。图中的任何一条路径代表一条函数调用链。图1是某个程序对应的函数调用图。节点中冒号前面是函数名,冒号后面是该函数对应的私有数据段的所占的字节数目。
当程序的控制流进入一个函数时,其私有数据的生命期开始,执行过程中需要访问这些数据;当该函数返回时,其私有数据的生命期结束,这些数据所占用的空间可以被释放。显然,出现在同一条调用链上的所有函数的私有数据的生命期是相交的,因此它们的私有数据段不能共享存储空间。反之,如果两个函数没有同时出现在任何一条调用链上,那么在程序执行过程中,这两个函数的生命期不相交,它们的私有数据可以共享存储空间。
提出的快速分配算法(topologicalbasedalgorithm,tba)包括三个步骤。首先,通过静态分析技术,构建fcg。其次,基于fcg的拓扑排序,确定每个函数的私有数据段的全局地址。最后,计算段内每个符号的全局地址,并根据重定位表更新对这些符号的引用。详细的处理流程如图2所示。
其实现的具体流程为:
101、开始,静态分析目标文件;
102、生成函数调用图;
生成函数调用图包括两种,一种是不使用地址指针生成一般函数调用图,另一种是使用地址指针生成精确函数调用图。
103、对函数调用图进行拓扑排序;
104、判断是否使用中断函数;
105、若使用中断函数,则分配独占空间存储;若不使用中断函数,则分配共享空间存储;
106、判断是否是递归函数;
107、是递归函数,则使用普通的overlay算法,不是递归函数,则使用tba算法快速overlay。
进一步,构建函数调用图:
构建函数调用图的算法:对于每个函数f扫描其语句,如果有函数调用语句,就将被调函数加入到f的调用函数集合。如果函数调用语句中操作的不是函数名,而是函数指针,就通point_to(p)返回指针变量p可能指向的函数集合。函数point_to依赖于指针分析。
基于拓扑排序的分配:
如前所述,没有函数递归调用的程序的函数调用图fcg是一个dag。所以,可以对fcg进行拓扑排序。我们的算法基于拓扑排序确定各函数的私有数据段的起始地址。首先,对fcg中的所有函数进行拓扑排序,得到函数的任意一个拓扑序列。然后,依次取出拓扑序列中的函数f,如果f是第一个函数main,那么其数据段的起始地址为0,并记录其数据段的结束地址的后一个地址addr(即起始地址+数据段大小,称为f的后继地址)。将序偶(addr,main)加入到已处理函数列表allocfuncs(该列表根据序偶中的后继地址从大到小排序);如果f不是第一个函数,那么在allocfuncs中按顺序搜索,直到找到一个序偶(nend,g)满足g调用f(除了第一个函数main,其余函数都能找到这样的序偶)。将nend分配给g的数据段的起始地址。然后将新数据段的后继地址(nend+g的数据段大小)加入到allocfuncs。
下面我们以图1中的例子来进行说明。假设图1中的fcg的某一个拓扑排序是<main,f4,f1,f2,f3,f5>。
1).首先分配main。因为main是第一个函数,因此它的数据段的起始地址为0.将main函数及其后继地址加入allocfuncs得到{(36,main)}。
2).然后分配f4。扫描allocfuncs。它被main函数调用,所以f4的数据段的起始地址为36。将其后继地址116(36+80)加入allocfuncs得到{(36,main),(116,f4)}。
3).然后分配f1。扫描allocfuncs。f1不被f4调用,但是被main调用,所以main函数的后继地址36作为起始地址,并将其后继地址48(36+12)加入allocfuncs,得到{(116,f4),(48,f1),(36,main)}
4).然后分配f2。依次扫描allocfuncs,先扫描到结束地址为116的f4函数。因为f4调用f2,所以给f2的数据段分配起始地址116,并将后继地址176(116+60)加入到allocfuncs。
5).然后分配f3。从后向前扫描allocfuncs,找到f1调用f3,所以将其数据段结束地址48作为f3的数据段的起始地址,并将后续208(48+160)加入allocfuncs。此时allocfuncs为{(208,f3),(176,f2),(116,f4),(48,f1),(36,main)}。
最后分配f5,在allocfuncs中第一个调用f5的函数为f2。最终的分配结果如图3所示。
更新符号表及代码:
最后一步是根据上述分配算法的结果,更新重定位表,以及代码中对这些函数私有符号的引用地址。先扫描私有数据段中的所有符号,将符号在段内的偏移量加上所在段的全局地址,得到该符号的全局地址,再根据重定位表,更新代码中对这些符号的引用。
总之,本发明所实现的快速进行overlay的方法,基于拓扑分析算法(tba)进行快速overlay,可以让程序员安排程序的不同部分来分享相同的内存,当程序的某一部分被其他部分调用时可以按需要加载,从而提高ram的利用率,提高链接器overlay速度和效率。
传统overlay算法注重效率的同时,往往速度不够快,导致编译时间较长。在进行大型项目的开发过程中时,这点尤其明显。优化后的基于快速拓扑分析算法(tba)能够提高overlay30%以上的速度。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!