一种基于互联网地图数据的地表覆盖分类方法及系统与流程
本发明属于地表覆盖分类技术领域,尤其涉及一种基于互联网地图数据的地表覆盖分类方法及系统。
背景技术:
地表覆盖及变化数据是环境变化研究、地理国情监测和可持续发展规划等的重要科学数据,其分类与制图一直是国内外研究的热点。当前地表覆盖分类主要利用航天、航空遥感影像中的光谱和纹理信息,结合先验知识和经验,来提取类型分布及变化信息,进行地表覆盖制图。然而,该方法耗时耗力、生产周期长,难以满足地表覆盖产品快速分类和制图的需求。为减少制图成本,满足用户对地表覆盖产品日益变化的应用需求,需要发展一种新的地表覆盖分类方法。
当前,已经出现了诸多应用众源地理数据进行地表覆盖分类的方法。例如,“see,linda,etal."buildingahybridlandcovermapwithcrowdsourcingandgeographicallyweightedregression."isprsjournalofphotogrammetryandremotesensing103(2015):48-56.”应用geo-wiki中的志愿者标注信息,通过志愿者对其所在地区的地表覆盖类型进行人工判断,实现中等分辨率地表覆盖的分类与制图;“johnson,briana.,etal."employingcrowdsourcedgeographicdataandmulti-temporal/multi-sensorsatelliteimagerytomonitorlandcoverchange:acasestudyinanurbanizingregionofthephilippines."computers,environmentandurbansystems64(2017):184-193.”提出一种将众源地理数据中的文本信息与遥感影像相结合的地表覆盖分类方法。上述研究通过利用众源地理数据,实现了地表覆盖的快速分类。然而,由于众源地理数据大多来自未经过训练的志愿者,其数据质量无法保证,并且其覆盖范围为志愿者主要活动区域,数据更新也无法保证。因此,将其作为数据源进行地表覆盖分类,在一定程度上影响了精度。
近年来,随着商业互联网地图的应用和发展,出现了诸如百度地图、高德地图等互联网地图数据。这些数据来源于专业的商业公司,其精度高、更新实时、覆盖面广,也包含了大量能够反映地表覆盖类型的文本信息。因此,将商用互联网地图数据应用于地表覆盖分类是一条可行途径。鉴于此,本专利提出了一种基于互联网地图数据的地表覆盖分类方法及系统。
技术实现要素:
本发明提供了一种基于互联网地图数据的地表覆盖分类方法及系统,由于互联网数据包含了点、线、面等多种不同的数据类型,同时其文本信息类型多样,无法直接应用于地表覆盖分类。
为解决上述问题,本发明提出了:
一种基于互联网地图数据的地表覆盖分类方法,包括如下步骤:
步骤a:对互联网地图数据中的文本信息进行分类,得到互联网地图数据的地表覆盖类型;
步骤b:构建地表覆盖分类区域:分别提取互联网地图数据中已经完成分类的点、线和面,构建基于点、线和面的三种地表覆盖区域;
步骤c:对地表覆盖分类区域进行融合:首先,将步骤b所得基于点、线、面的三种地表覆盖区域进行空间叠加;继而,针对叠加后的地表覆盖重合区域,利用步骤a所得地表覆盖类型,将地表覆盖类型不同的区域去除,保留地表覆盖类型相同的区域,其地表覆盖类型为步骤a所得类型;针对叠加后未重合的地表覆盖区域,其地表覆盖类型为步骤a所得各互联网地图数据的类型。
所述地表覆盖类型包括耕地、绿地、水体、人造地表。
所述点为兴趣点,所述线包括道路或河流,所述面包括建筑物、绿地或水体。
所述步骤a的步骤为:首先,应用互联网地图数据,依据互联网地图中各数据的空间位置,应用谱聚类算法,对互联网地图数据进行聚类,得到n个互联网地图数据聚类簇;继而,提取每个聚类簇中的文本信息,应用朴素贝叶斯算法,对每个聚类簇中的互联网地图数据进行分类,得到互联网地图数据的地表覆盖类型。
所述步骤b的步骤为:
步骤b1:针对互联网地图数据中的点,应用核密度方法,构建基于点的地表覆盖区域;
步骤b2:针对互联网地图数据中的线,利用缓冲区分析的方法,构建基于线的地表覆盖区域;
步骤b3:互联网地图数据中的面数据,则直接作为地表覆盖区域。
所述步骤a包括:
步骤a1:提取互联网地图数据的空间位置信息,利用谱聚类算法,对互联网地图数据进行聚类,得到n个互联网地图数据聚类簇;
步骤a2:提取每个聚类簇中的文本信息,应用朴素贝叶斯算法,对每个聚类簇中的互联网地图数据进行分类,得到互联网地图数据的文本信息分类结果。
所述步骤a1提取互联网地图数据的空间位置信息,利用谱聚类算法,对互联网地图数据进行聚类,得到n个互联网地图数据聚类簇,计算公式如下:
其中,xi表示第i个互联网地图数据,xj表示第j个互联网地图数据;si,j表示相邻互联网数据间的相似度,相似度的取值范围在[-1,1],其中-1表示两个值完全不相同,1表示两个值完全相同;||xi||表示第i个互联网地图数据的范数,||xj||表示第j个互联网地图数据的范数。
继而,基于公式(1)构建相似图
所述步骤a2提取每个聚类簇中的文本信息,应用朴素贝叶斯算法,对每个聚类簇中的互联网地图数据进行分类,见公式(3):
其中,
其中,p(xi|c,x1,x2,x3....xi-1)为地表覆盖类型c下数据为xi的概率,简化为公式(5):
p(xi|c,x1,x2,x3....xi-1)≈p(xi|c);(5)
其中,i为第i个互联网地图数据。
最后,将公式(4)(5)带入公式(3),得到互联网地图数据的文本信息分类结果,见公式(6):
所述构建相似图方法如下:
相似图中的每一个互联网地图数据xi代表一个输入数据点,若相似度si,j为正值,即si,j>0,则两个数据xi、xj与边ei,j相连;相似图构建完毕。
所述带权邻接矩阵w的构建方法如下:
提取相似图
wi,j为两个数据xi、xj连接的权重。
所述次数矩阵d的构建方法如下:
把带权邻接矩阵w的每一列权重加起来得到n个数,把它们放在矩阵d的对角线上(其他地方都是零),组成一个次数矩阵d,其构建形式如下:
其中,dn为第n列权重加起来得到的个数。
接着,利用带权邻接矩阵w和次数矩阵d,构建拉普拉斯矩阵l:
l=d-w;(2)
最后,应用k-means聚类,对所得拉普拉斯矩阵l进行聚类,得到互联网地图数据的聚类簇。
所述步骤b1:针对互联网地图数据中的点,应用核密度方法,构建基于点的地表覆盖区域d,其计算公式如下:
其中,n为互联网地图数据的数量,k为核函数,选择sigmoid核函数作为计算依据,xi为第i个已知的互联网地图数据,h为区域范围搜索带宽。依据经验参数取h=30m。
所述步骤b2:针对互联网地图数据中的线,利用缓冲区分析的方法,构建基于线的地表覆盖区域。针对一级道路、二级道路、三级道路、四级道路分别建立半径为35m、30m、20m、10m的缓冲区,得到道路的地表覆盖区域。
一种基于互联网地图数据的地表覆盖分类系统,包括:
分类模块:对互联网地图数据中的文本信息进行分类,得到互联网地图数据的地表覆盖类型;
地表覆盖分类区域构建模块:分别提取互联网地图数据中已经完成分类的点、线和面,构建基于点、线和面的三种地表覆盖区域;
对地表覆盖分类区域进行融合的模块:首先,将地表覆盖分类区域构建模块所得基于点、线、面的三种地表覆盖区域进行空间叠加;继而,针对叠加后的地表覆盖重合区域,利用分类模块所得地表覆盖类型,将地表覆盖类型不同的区域去除,保留地表覆盖类型相同的区域,其地表覆盖类型为分类模块所得类型;针对叠加后未重合的地表覆盖区域,其地表覆盖类型为分类模块所得各互联网地图数据的类型。
本发明提出了首先依据互联网地图数据的空间位置信息,利用谱聚类得到方法,进行数据聚类,并提取每个数据簇的文本信息,应用朴素贝叶斯算法,对文本信息进行地表覆盖分类;继而,提取互联网地图数据中的点、线、面数据,构建地表覆盖区域;最后,将所得地表覆盖区域进行叠加,处理冲突的地表覆盖类型,最后得到地表覆盖分类结果。
附图说明
图1为地表覆盖分类方法示意图;
图2(a)-图2(c)为北京市互联网地图数据示意图;
图3(a)-图3(b)为北京市部分区域互联网地图数据聚类结果及地表覆盖类型分类图;
图4(a)-图4(b)为北京市部分区域互联网地图数据地表覆盖区域构建图;
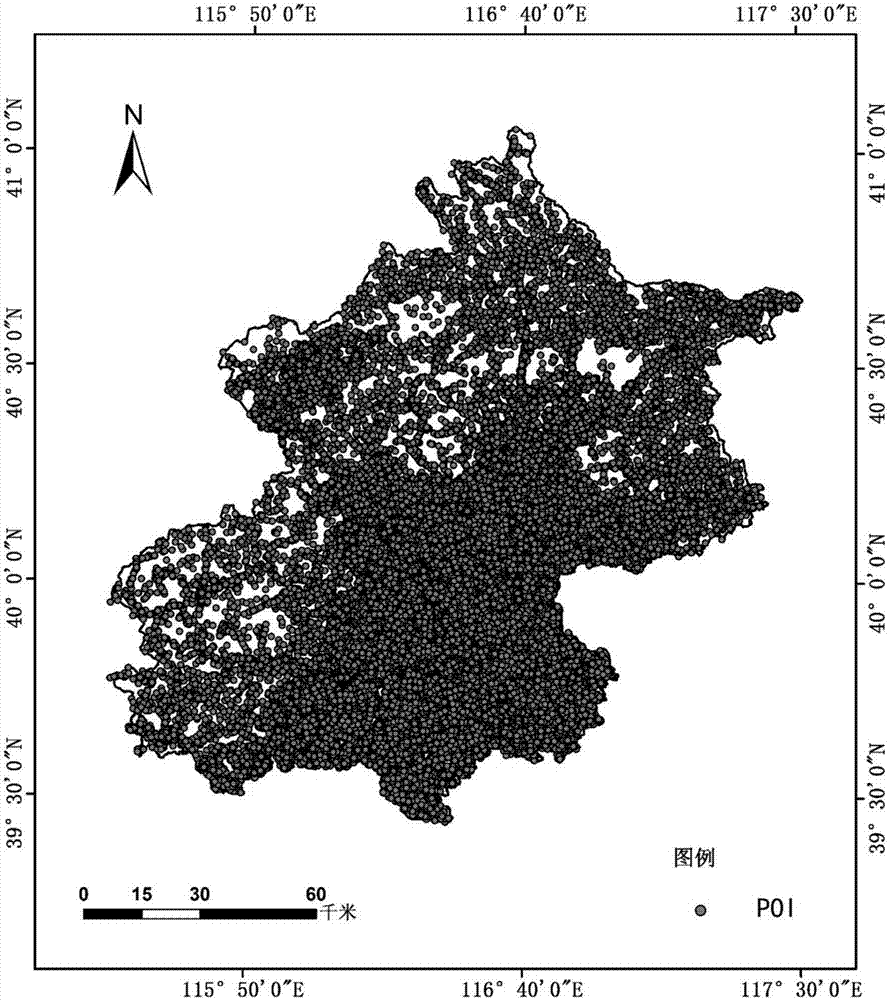
图5为北京市基于互联网地图数据的地表覆盖分类图。
具体实施方式
下面结合附图与实施例对本发明作进一步说明。
为了对本发明的技术特征、目的和效果有更加清楚的理解,现以北京市互联网地图数据集为例,对照附图说明本发明的具体实施方式。
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
本发明所提出的一种基于poi数据的地表覆盖分类方法,如图1所示,所述方法用于基于互联网地图数据的地表覆盖分类;所述地表覆盖分类方法包括基于谱聚类算法的互联网地图数据中的文本信息分类方法和基于互联网地图数据的地表覆盖区域构建方法;所述方法包括如下步骤:
a:对互联网地图数据中的文本信息进行分类。首先,应用互联网地图数据,依据互联网地图中各数据的空间位置,应用谱聚类算法,对互联网地图数据进行聚类,得到n个互联网地图数据聚类簇;继而,提取每个聚类簇中的文本信息,应用朴素贝叶斯算法,对每个聚类簇中的互联网地图数据进行分类,得到互联网地图数据的地表覆盖类型。
北京市互联网地图数据集包括1528104个poi数据,如图2(a)所示;206029条道路数据,如图2(b)所示;183739个建筑物数据、1466个绿地数据,2649个水系数据,如图2(c)所示。如表1所示:poi数据源属性信息有位置、类型、与地址;道路数据源属性信息有名称、位置和类型;建筑数据、绿地数据与水系数据源属性信息有名称和位置。
表1互联网地图数据源及其属性信息
a:提取互联网地图数据的空间位置信息,利用谱聚类算法,对互联网地图数据进行聚类,得到n个互联网地图数据聚类簇。其计算公式如下:
其中,si,j表示相邻互联网数据间的相似度,xi与xj分别表示第i个与第j个互联网地图数据。其相似度的取值范围在[-1,1],其中-1表示两个值完全不相同,1表示两个值完全相同。
继而,基于公式(1)构建相似图g=(x,e)。其中,x与e分别为互联网地图数据与连接数据的边。其构建方法如下:
相似图中的每一个互联网地图数据xi代表一个输入数据点,若相似度si,j为正值,即si,j>0,则两个数据与边ei,j相连。由此建立两个矩阵,带权邻接矩阵w和次数矩阵d。
接着,利用带权邻接矩阵w和次数矩阵d,构建拉普拉斯矩阵l,其公式如下:
l=d-w(2)
最后,应用k-means聚类,对所得拉普拉斯矩阵l进行聚类,即得到互联网地图数据的聚类簇。
以北京市为例,利用互联网地图数据中的poi、道路、水系、绿地和建筑物的位置信息,基于谱聚类算法一共获得一共得到了41029个聚类簇。图3(a)为局部聚类结果图,可以发现聚类结果实现了聚类簇内部的互联网地图数据之间的距离最小,聚类簇之间的距离最大,实现了对互联网地图数据集中的点、线、面数据的聚类分簇。
b:提取每个聚类簇中的文本信息,应用朴素贝叶斯算法,对每个聚类簇中的互联网地图数据进行分类,其计算公式如下:
其中,
其中,p(xi|c,x1,x2,x3....xi-1)为地表覆盖类型c下数据为xi的概率,可简化为如下公式:
p(xi|c,x1,x2,x3....xi-1)≈p(xi|c)(5)
其中i为第i个互联网地图数据。
最后,将公式(4)(5)带入公式(3),即得到互联网地图数据的文本信息分类结果,如下公式:
即不同数据x下地表覆盖c的概率。
考虑到poi地址与建筑物中的名称较为离散,无法准确反映地表覆盖信息,本实验将poi数据集中的类型作为用于主题分析的文本数据,将建筑物数据集新建文本字段,统一赋值为“建筑物”文本信息。
在提取每个簇的文本字段时,只提取poi数据类型中的小类信息,已经出现了的文本信息不予提取。在41029个聚类簇的1921987个互联网地图数据中一共提取了38438个文本信息,选取前30000簇的1493865个互联网地图数据中的29453个文本信息作为训练数据集,选取后11029个簇的428122个互联网地图数据中的8985个文本信息作为测试数据集。其中,“建筑物”、“购物服务”、“餐馆”等文本分为人造地表,“绿地”、“高尔夫球场”等文本分为绿地,“水系”、“清风湖”等文本分为水体,“采摘园”等文本分为耕地。
依据互联网地图数据中文本信息的概论分布,利用朴素贝叶斯算法,构建地表覆盖分类模型。依据本专利提出的地表覆盖分类模型,对41029聚类簇的1921987个互联网地图数据集进行分类,局部分类结果如图3(b)所示。
b:构建地表覆盖分类区域。分别提取互联网地图数据中已经完成分类的点(兴趣点)、线(道路)、面(建筑物、绿地、水体)。针对互联网地图数据中的点(兴趣点),应用核密度方法,构建基于点的地表覆盖区域;针对互联网地图数据中的线(道路),利用缓冲区分析的方法,构建基于线的地表覆盖区域;而互联网地图数据中的面数据,则直接作为地表覆盖分类区域。
a:针对互联网地图数据中的点(兴趣点),应用核密度方法,构建基于点的地表覆盖区域d,其计算公式如下:
其中,n为互联网地图数据的数量,k为核函数,选择sigmoid核函数作为计算依据,xi为第i个已知的互联网地图数据,h为区域范围搜索带宽。依据经验参数取h=30m。
以30米为搜索半径,对1528104个poi数据进行核密度分析,构建poi数据地表覆盖区域。如图4(a)所示,所划定poi数据的地表覆盖区域与遥感影像中的地表覆盖区域有效叠合。
b:针对互联网地图数据中的线(道路),利用缓冲区分析的方法,构建基于线的地表覆盖区域。分别针对一级道路、二级道路、三级道路、四级道路建立半径为35m、30m、20m、10m的缓冲区,得到道路的地表覆盖区域。
根据互联网地图数据中的道路等级,分别建立半径为35m、30m、20m、10m的缓冲区,得到道路的地表覆盖区域。如图4(b)所示,所划定的地表覆盖区域与遥感影像中的地表覆盖区域有效叠合。
c:互联网地图数据中的面数据,直接作为地表覆盖分类区域。
对已有的互联网地图数据中的建筑物数据、水体数据和绿地数据不做处理。
c:对地表覆盖分类区域进行融合。首先,将步骤b所得地表覆盖区域进行空间叠加;继而,针对叠加后的地表覆盖重合区域,利用步骤a所得地表覆盖类型,将地表覆盖类型不同的区域去除,保留地表覆盖类型相同的区域,其地表覆盖类型为步骤a所得类型;针对叠加后未重合的地表覆盖区域,其地表覆盖类型为步骤a所得各互联网地图数据的类型。
首先,对poi核密度结果、道路缓冲区、建筑物数据、道路数据与水体数据进行空间叠加。其次,对空间叠加后重合的区域基于数据类型绝对去除或保留,若数据类型相同,人造地表类型的poi数据与建筑物数据叠加,保留区域;若数据类型不同,人造地表类型的poi数据与水体数据叠加,去除区域。如图5所示,为本实验基于互联网地图数据地表覆盖北京市分类结果图。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!