一种联合图像、语音的全面情绪识别方法与流程
本发明属于计算机技术、信息技术、数据挖掘交叉技术领域,涉及一种联合图像、语音的全面情绪识别方法和系统,在人机交互中,主要利用同一个人的人脸图像和语音这两个方面进行有权重分配的情绪识别。
背景技术:
人脸情绪识别是指利用计算机对人类面部表情信息进行特征提取分析,按照目前大众的认识和思维方式归类和理解,综合人类具有的情感信息的先验知识使计算机独立联想、思考及推理,最后从人脸信息中去分析人类情绪。由于人脸表情识别有着广泛的应用前景,因而逐渐成为当前人机交互、图像理解、模式识别、机器视觉等领域的研究热点之一。
在当下的人机交互中,语音是交流中最基本最直接的方式,因此语音信号中的情感信息也受到了广泛技术人员的重视,语音情绪识别就是通过分析人的语音信号在不同情感表达方面的变化规律,使用计算机从语音信号中准确提取并选取合适的语音情感特征参数,并根据选取的情感参数来判别人的情绪。
集成学习就是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合从而获得比单个学习器更好的学习效果的一种机器学习方法。目前,机器学习方法已经在科学研究、语音识别、人脸识别、手写识别、数据挖掘、医疗诊断、游戏等等领域之中得到应用。
目前现有的人类情绪识别只是单一的人脸图像情绪识别或单一的语音情绪识别,在光线昏暗、图像模糊的背景下使用图像情绪识别,或在环境噪声大的背景下使用语音识别都会使得人类情绪识别产生很大误差,甚至误判为其他情绪类别。单一方面的人类情绪识别技术遇到瓶颈,准确率难以提高。此外,在人机交互中,现有的情绪识别计算量仍然巨大,产生延时,这种延时会造成数据的误差,在人机交互中是很不友好的。
技术实现要素:
本发明所要解决的技术问题是克服现有技术的不足而提供一种联合图像、语音的全面情绪识别系统,通过联合的信号处理方法,以对应用中的语音和图像环境进行一种认知识别,这里称为可靠程度识别。本发明可有效的提高人类情绪识别的实时性、准确性。
本发明为解决上述技术问题采用的技术方案为一种联合图像、语音的全面情绪识别方法,包括以下步骤:
步骤1:从casia汉语情感语音数据库收集n个语音情感样本,并从人脸表情识别图片库收集n个表情情感样本,根据原始情感分类标记将获得的语音和表情样本,归结为n种情感类别ej,1≤j≤n;
步骤2:对n个语音样本构建元分类器样本训练特征数组:xmeta=<p1(e1|x),p2(e1|x),p1(e2|x),p2(e2|x),…,p1(en|x),p2(en|x)>,其中,x表示语音样本,pi(ej|x)表示第i(i=1,2)个语音情感弱分类器判断x属于类别ej的后验概率;
步骤3:对n个表情样本构建元分类器样本训练特征数组,ymeta=<p1(e1|y),p2(e1|y),p1(e2|y),p2(e2|y),…,p1(en|y),p2(en|y)>,其中,y表示表情样本,pi(ej|y)表示第i(i=1,2)个表情情感弱分类器判断y属于类别ej的后验概率;
步骤4:使用m倍交叉验证的方式处理语音、表情样本的原始标注集lx和ly,lx=[xmeta]n×2n,ly=[ymeta]n×2n,其中,lx,ly分别表示语音、表情样本的原始标注集,是含有n个样本后验概率的n行2n列的矩阵;
步骤5:将原始标注数据集平均分成m(m≤n/n)份,每份包含所有情感类别,分别为l1,l2,…,lm,赋予k初值1,1≤k≤m;
步骤6:将lk作为新的未标注样本,其余作为新的标注样本,即:unew=lk,lnew=l-lk,其中,unew表示新的未标注样本集,作为训练样本;lnew表示新的标注样本集,并令
步骤7:分别使用两种语音情感弱分类器f1,f2对语音样本集训练,得到分类的后验概率p1(c|x)=f1(x),p2(c|x)=f2(x);
步骤8:再分别使用两种表情情感弱分类器g1,g2对语音样本集训练,得到分类的后验概率p1(c|y)=g1(y),p2(c|y)=g2(y),设置置信度要求η;
步骤9:对于分类结果与样本初始标记c0一致的后验概率p(c0|c)≥η的样本xmeta和ymeta,移入新的标注样本集lnew,剩余的样本作为不可信样本留在训练样本集unew继续参与迭代,判断此时k值:小于n返回步骤6;否则进入步骤10;
步骤10:令可信的新样本集lnew中xmeta和ymeta个数分别为nx和ny,将
步骤11:输入音频流,截取表情图片并提取语音信号,分别用上述四种情感识别方法分类,对分类结果加权获得可信度较高的情感分类结果。
进一步,上述步骤1中n种情感类别包含正常、喜悦、愤怒、悲伤、惊讶五种状态。
进一步,上述步骤7中,根据弱分类器结果与原始标记的比较,用后验概率表征该分类器可信度。
进一步,上述步骤7中,语音情感弱分类器f1,f2具体包括如下步骤:
步骤701:分别提取语音样本的特征参数:语速、瞬时能量、瞬时过零率、共振峰和基频,并构成样本特征数据集,进入步骤702;
步骤702:使用pnn分类算法对获得的特征数据集分类,得到f1弱分类器,并进入步骤703;
步骤703:提取语音信号样本的特征参数:信号的持续时间、信号的振幅、基音周期和共振峰频率,并构成样本特征数据集,进入步骤704;
步骤704:采用带有高斯概率分布的参数方法对获得的特征数据集分类:估算完参数的均值和方差后,利用bayes准则计算出最大后验概率对情感进行分类,得到f2弱分类器。
进一步,上述步骤8中表情情感弱分类器g1,g2具体包括如下步骤:
步骤801:使用adaboost算法进行人脸检测;
步骤802:对每类表情图像系列进行fastica处理,并将得出的特征值作为表情图像的特征向量,初始化hmm模型,采用前向-后向算法训练hmm模型,得到g1弱分类器;
步骤803:采用gabor小波变换方法对表情图像的gabor特征提取,并运用支持向量机对表情进行分类识别,得到g2弱分类器。
本发明还进一步提出一种实现上述联合图像、语音的全面情绪识别方法的系统,该系统由信息采集装置、情感分类器和集成处理器组成,信息采集装置包括视频采集器和音频采集器;情感分类器包括对采集的视频信息进行情感分类的表情情感分类模块和对采集的音频信息进行情感分类的语音情感分类模块;集成处理器包括加权模块、集成学习训练器,当信息采集装置采集到相应语音、视频信号后,分别传送到对应的情感分类模块,经分类处理后,集成学习训练器分配权重,经加权处理后,输出识别结果,完成识别过程。
进一步,上述情感分类器对情感的分类包括五类:正常、喜悦、愤怒、悲伤、惊讶。
进一步,上述情感分类器对语音情感分类采用pnn分类算法、bayes准则两种分类算法得到语音情感弱分类器,表情情感分类采用hmm模型、gabor小波变换两种分类算法得到表情情感弱分类器。
进一步,上述集成学习训练器经由标准语音和表情情感库训练。
进一步,上述加权模块中生成的权值是以样本语音和表情情感弱分类器的识别后验概率作为参数,进行加权处理。
与现有技术相比,本发明具有的有益效果:
1、本发明提出的系统自适应性强,同时具有更好的抗噪性能,整体性能稳健。
2、情感分类可靠性更高,调整置信度参量可灵活完成识别要求,达到高精度要求。
3、通过表情语音双向识别,实现新型联合识别系统,极大程度上模拟了人类情感识别过程。
附图说明
图1是本发明联合图像、语音的全面情绪识别系统的结构示意图。
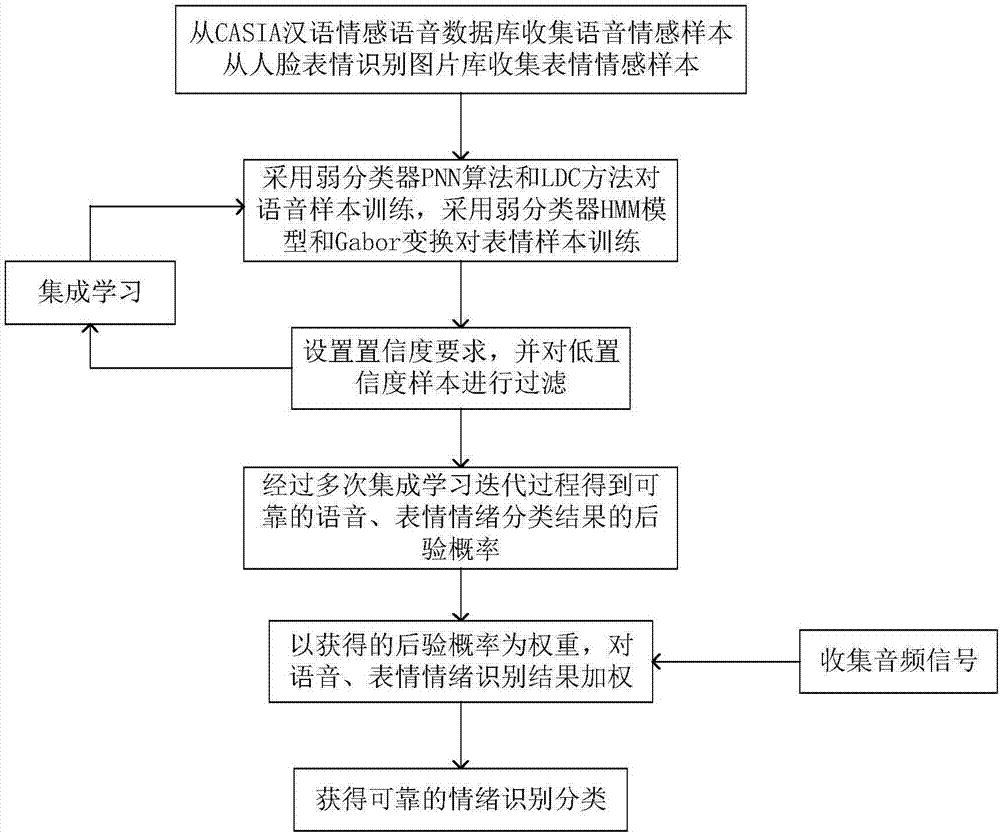
图2是联合图像、语音的全面情绪识别方法的流程图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明。
联合图像、语音的全面情绪识别系统研究人类情绪识别的两大主要方法(语音情绪识别、人脸图像情绪识别)的合理配置,增加识别人类情绪的时效性和准确性。首先从柏林情感语音数据库和人脸表情识别图片库收集语音情感样本、表情情感样本。接着采用弱分类器pnn算法和ldc方法对语音样本训练,采用弱分类器hmm模型和gabor变换对表情样本训练,通过设置置信度、集成学习得到可靠的语音、表情情绪分类结果的后验概率,并以此为权重,对语音、表情加权。最后输入语音和流表情图像,对分类结果加权获得可信度较高的情感分类结果。这种训练使得我们对人类情绪的识别更为准确,更具有实时性。
联合图像、语音的全面情绪识别系统的结构如图1所示。系统包含信息采集装置、情感分类器和集成处理器组成。信息采集装置包括视频采集器和音频采集器;情感分类器包括对采集的视频信息进行情感分类的表情情感分类模块和对采集的音频信息进行情感分类的语音情感分类模块;集成处理器包括加权模块、集成学习训练器。当信息采集装置从输入视频中采集到相应语音、视频信号后,分别传送到对应的情感分类模块,经分类处理后,集成学习训练器分配权重,经加权处理后,输出识别结果,完成全过程。
如图2所示,联合图像、语音的全面情绪识别方法包含以下步骤:
步骤001.从casia汉语情感语音数据库收集n个语音情感样本,并从人脸表情识别图片库收集n个表情情感样本,根据原始情感分类标记将获得的语音和表情样本,归结为n种情感类别ej,1≤j≤n,根据母语的特点和其它学者研究的经验,在我们的研究中设置待识别的情绪为:正常(e1)、喜悦(e2)、愤怒(e3)、悲伤(e4)、惊讶(e5)五种状态,即n=5,然后进入步骤002;
步骤002.为了方便大量样本训练计算,我们对n个语音样本构建元分类器样本训练特征数组:xmeta=<p1(e1|x),p2(e1|x),p1(e2|x),p2(e2|x),…,p1(en|x),p2(en|x)>。其中,x表示语音样本,pi(ej|x)表示第i(i=1,2)个语音情感弱分类器判断x属于类别ej,1≤j≤5的后验概率。并进入步骤003;
步骤003.对于表情情感样本,同样的对n个表情样本构建元分类器样本训练特征数组:ymeta=<p1(e1|y),p2(e1|y),p1(e2|y),p2(e2|y),…,p1(en|y),p2(en|y)>。其中,y表示表情样本,pi(ej|y)表示第i(i=1,2)个表情情感弱分类器判断y属于类别ej,1≤j≤5的后验概率。然后进入步骤004;
步骤004.为了提高训练质量,以及对标准样本的冲分利用,我们采用m倍交叉验证的方式处理语音、表情样本的原始标注集:lx=[xmeta]n×2n和ly=[ymeta]n×2n。其中,lx,ly分别表示语音、表情样本的原始标注集,是含有n个样本后验概率的n行2n列的矩阵,方便后续筛选统计。然后进入步骤005;
步骤005.将原始标注数据集平均分成m(m≤n/5)份(每份包含所有情感类别),分别为l1,l2,…,lm,赋予迭代计数器k初值1,1≤k≤m,进入步骤006;
步骤006.选取其中的lk样本子集作为新的未标注样本,其余作为新的标注样本,即:unew=lk,lnew=l-lk。其中,unew表示新的未标注样本集,作为训练样本;lnew表示新的标注样本集,并令
步骤007.分别使用两种语音情感弱分类器pnn分类算法f1,和ldc分类方法f2对语音样本集训练,得到分类的后验概率p1(c|x)=f1(x),p2(c|x)=f2(x),具体包括如下步骤:
步骤00701.分别提取语音样本的特征参数:语速、瞬时能量、瞬时过零率、共振峰和基频,并构成样本特征数据集,进入步骤00702;
步骤00702.使用pnn分类算法对获得的特征数据集分类,得到f1弱分类器,并进入步骤00703;
步骤00703.提取语音信号样本的特征参数:信号的持续时间、信号的振幅、基音周期和共振峰频率,并构成样本特征数据集,进入步骤00704;
步骤00704.采用ldc方法(带有高斯概率分布的参数方法)对获得的特征数据集分类:估算完参数的均值和方差后,利用bayes准则计算出最大后验概率对情感进行分类,得到f2弱分类器。然后进入步骤008;
步骤008.再分别使用两种表情情感弱分类器基于hmm模型分类器g1,和svm分类识别器g2对语音样本集训练,得到分类的后验概率p1(c|y)=g1(y),p2(c|y)=g2(y)。具体包括如下步骤:
步骤00801.使用adaboost算法进行人脸检测,然后进入步骤00802;
步骤00802.对每类表情图像系列进行fastica处理,并将得出的特征值作为表情图像的特征向量。初始化hmm模型,采用前向-后向算法训练hmm模型,得到g1弱分类器,并进入步骤00803;
步骤00803.采用gabor小波变换方法对表情图像的gabor特征提取,并运用支持向量机(svm)对表情进行分类识别,得到g2弱分类器。并进入步骤009;
步骤009.根据不同可靠度要求,为用户提供灵活的置信度要求η,需要注意的是,过高的置信度要求可能导致训练无法进行。对于分类结果与样本初始标记c0一致的后验概率p(c0|c)≥η的样本xmeta和ymeta,移入新的标注样本集lnew,剩余的样本作为不可信样本留在训练样本集unew继续参与迭代。判断此时k值:小于n返回步骤006;否则进入步骤010;
步骤010.令可信的新样本集lnew中xmeta和ymeta个数分别为nx和ny,将
步骤011.从输入的音频流提取语音信号并截取表情图片,用上述四种情感识别弱分类器组成的强分类器对待测样本分类,利用各弱分类器加权结果作为可信度较高的情感分类结果。
- 还没有人留言评论。精彩留言会获得点赞!