监控场景下行人目标的全景描述方法及系统与流程
本发明涉及特定行人在多个监控点下的运动轨迹的视频追踪,具体地指监控场景下行人目标的全景描述方法与系统,属于视频侦查业务领域。
背景技术:
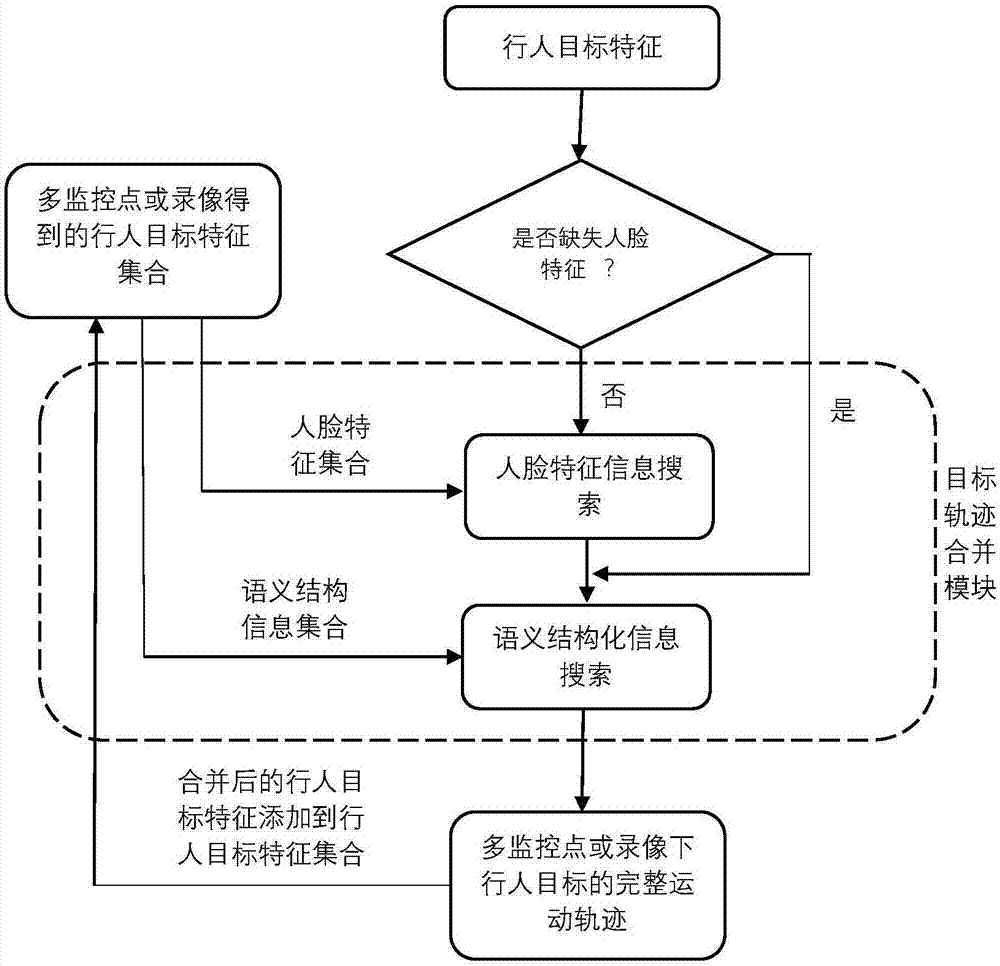
:随着平安城市的广泛建设和视频监控系统的普及,通过视频监控系统获取到的数据量也就越来越大,这给公安机关的维稳、各类案件侦查等带来机遇,也带了挑战。大量的视频监控录像数据为维稳和案件侦查带了大量的可视化证据,但是如何快速准确地区别视频监控录像出现的行人目标并提取出尽可能多的有效信息供公安干警使用成为了能否有效使用视频监控录像数据的关键。传统的行人目标描述方法主要的问题在于:(1)无法准确定位行人图像,图像连带多人或残缺,使得后续特征提取失效;(2)只提取行人全局特征,行人表达不精确,使得行人表达有偏差或判断力不足;(3)无法定位行人目标在多个监控点下的运动轨迹。技术实现要素:本发明目的在于克服上述现有技术的不足而提供一种基监控场景下行人目标的全景描述方法及系统,本发明能够在监控场景下,准确跟踪和提取每个行人目标,对每个行人目标进行全景描述,包括人脸特征提取和人体语义结构化信息提取,最终实现在多个监控点下碰撞出相同的行人目标,形成每个行人目标在多个监控点下的运动轨迹。实现本发明目的采用的技术方案是一种基监控场景下行人目标的全景描述方法,该方法包括:从输入视频中提取出行人目标代表帧;从行人目标代表帧中提取出行人的人脸特征;将行人目标代表帧进行语义部件分割生成行人的部件,形成行人图像的结构化语义描述、提取行人部件的部件特征,以及提取行人图像的整体特征;根据当前行人目标的人脸信息,从多个监控视频中搜索出与所述人脸特征最近似的几个目标轨迹,得到近似目标集合;然后根据行人图像的结构化语义描述、部件特征和整体特征,从所述近似目标集合中得到与当前行人目标相似度最高的目标轨迹即为当前行人的行踪轨迹。此外,本发明还提供一种基监控场景下行人目标的全景描述系统,该系统包括:目标提取模块,用于从输入视频中提取出行人目标代表帧;人脸特征提取模块,用于从行人目标代表帧中提取出行人的人脸特征;结构化语义提取模块,用于将行人目标代表帧进行语义部件分割生成行人的部件,形成行人图像的结构化语义描述、提取行人部件的部件特征,以及提取行人图像的整体特征;以及,目标轨迹合并模块,用于根据当前行人目标的人脸信息,从多个监控视频中搜索出与所述人脸特征最近似的几个目标轨迹,得到近似目标集合;然后根据行人图像的结构化语义描述、部件特征和整体特征,从所述近似目标集合中得到与当前行人目标相似度最高的目标轨迹即为当前行人的行踪轨迹。本发明具有以下优点:1、与现有技术的全局特征是从一个矩形图像上提取,且包含了背景相比,本发明方法对行人图像进行像素级分割,以提取部件特征,使得部件间的相似度度量比更有针对性,能更好解决视角问题。2、在视觉特征基础上,通过提取语义属性,相比基于视觉特征检索方法的鲁棒性更高;3、根据视频侦查需求,提出可语义分割的27个行人部件,还提出17个类别的语义属性,为视频侦查和特定行人追踪扩展思路;4、部件特征加上人脸结构化特征形成新的全景描述特征,比现有技术提取全局特征的方法更加全面。附图说明图1为本发明监控场景下的行人目标的全景描述系统的结构框图。图2为本发明监控场景下的行人目标的全景描述方法的流程图。图3为输入的某一行人代表帧图像。图4为图3经过特征提取模块语义分割后成部件后的图像。具体实施方式下面结合附图和具体实施例对本发明作进一步的详细说明。本发明监控场景下的行人目标的全景描述的系统包括目标提取、人脸检测、结构化语义提取、目标轨迹合并四个模块,每个模块具体实现如下功能:(1)目标提取模块包括背景建模、特征提取、目标检测与定位、目标跟踪、目标代表帧提取等子功能,具体实现的功能如下:首先,目标提取模块可以通过两种方式获取目标前景图像,一是用传统的背景建模和前景提取方法,二是用基于深度学习的目标检测方法。其次,目标提取模块利用目标跟踪方法,将一系列目标前景图像会形成多个不同的行人图像序列,不同的序列代表不同的行人目标。最后,目标提取模块从每个行人图像序列中选出一个图像帧来代表相应的行人,该图像帧作为目标代表帧。(2)人脸检测模块的输入是行人的目标代表帧图像,输出是行人目标的人脸结构化信息。人脸检测模块在检测输入的行人目标代表帧图像中有人脸信息时,会自动提取行人目标代表帧图像中的人脸特征信息。(3)结构化语义提取模块的输入是行人的目标代表帧图像,输出行人图像结构化语义、行人的部件和其特征以及行人的整体特征,它包括目标语义部件分割、行人结构化语义特征、部件特征提取、整体特征提取等子功能。首先,行人的代表帧图像,经过语义分割会生成行人的不同部件;然后,分割好的行人图像分别提取各个部件的特征和整体特征,并形成语义结构化描述。(4)目标轨迹合并模块的输入是当前目标的结构化特征信息,输出是目标在多监控点或多录像中的完整运动轨迹。它包括人脸搜索、行人结构化语义搜索等子功能。首先,使用当前目标的人脸特征信息进行人脸搜索,产生近似目标集合;然后,使用当前目标的人体结构化语义特征信息在近似目标集合中进行行人结构化语义搜索,得到相识度最高的值,可以进行目标轨迹合并。上述基于监控场景下的行人目标的全景描述的系统实现行人目标的多层次全景描述的过程如下:s1、目标提取模块对输入的视频文件或视频流处理后输出目标代表帧,具体包括:s1.1、从视频帧序列到行人前景图像:视频文件或视频流经过经过背景建模、前景提取、目标检测定位功能,生成行人前景图像。本实施例提供两套方案获取行人前景图像,一是用传统的背景建模和前景提取方法,二是用基于深度学习的目标检测方法。实际操作中,对于分辨率不高,对处理速度有要求的场景用传统方法;对于分辨率高、行人密度大的场景用基于深度学习的目标检测方法。s1.2、从行人前景图像到行人序列:多张行人前景图像经过跟踪后生成行人前景图像序列;s1.3、从行人前景图像序列到行人代表帧图像:行人前景图像序列经过目标代表帧提取选出行人的代表帧图像。本实施例提取目标代表帧的过程如下:记录第n个序列行人图像的面积为s(n),第n+1个序列行人图像的面积为s(n+1)。如果s(n)>s(n+1),代表帧为n;如果s(n)<s(n+1),且s(n+1)<a*s(n),a一般取2,代表帧为n+1;如果s(n+1)>a*s(n),代表帧为n。如此循环,找到行人序列的合适代表帧图像。s2、人脸检测模块对输入行人的目标代表帧图像处理后输出是行人目标的人脸结构化信息。本发明将得到人脸结构化信息通过9个语义信息体现,如下表1所示:人脸区域人脸的左上、右下点坐标左眼坐标左眼瞳孔中心坐标右眼坐标右眼瞳孔中心坐标嘴巴坐标嘴巴区域中心坐标鼻子坐标鼻尖坐标yaw偏角yaw偏角:-90~90(度)pitch偏角pitch偏角:-90~90(度)roll偏角roll偏角:-90~90(度)画像质量画像质量:0~100(分)表1s3、结构化语义提取模块对输入的代表帧图像处理后输出行人图像的结构化语义描述、行人部件的部件特征,以及行人图像的整体特征,具体包括:s3.1从行人代表帧图像到行人部件:行人代表帧图像经过目标语义部件分割生成行人的部件;本实施例中,目标图像语义分割采用全卷积网络方法,训练语义分割模型。对每个行人代表帧图像,会把其分成如下表2中的部件:表2将图2作为输入的图片按上表1进行分割成部件,输出的图片如图3所示。s3.2、从行人部件到行人结构化语义和特征:行人代表帧图像和部件分割信息经过行人结构化语义、部件特征提取、整体特征提取等功能形成行人结构化语义和特征。本发明将学习得出如下表3中的17个类别的语义。表3本实施例提取整体特征采用基于中轴线的高斯权重分布的特征提取方法,具体方法为对行人图像的上身部分和下身部分,分别取中轴线。以中轴线为对称轴,作为高斯分布的最高值。以高斯分布作为权重,提取带权重的颜色直方图。只提取上衣部分和下衣部分特征,并组合成全局特征。本实施例提取部件特征先对每个部件提取颜色和纹理直方图,然后对每个直方图,用相应部件的像素个数进行归一化。s4、目标轨迹合并模块对输入是当前目标的结构化特征信息,输出是目标在多监控点或多录像中的完整运动轨迹,具体包括:利用目标当前已有的结构化特征信息,与步骤s2获得的人脸结构化信息和s3获得的人体语义结构化信息比对,若当前目标的结构化特征信息包括人脸结构化信息,则优先使用目标的人脸结构化信息与所有目标轨迹的人脸结构化信息比对,在所有目标轨迹中选择最近似的几个目标轨迹,例如五个目标轨迹;若当前目标的结构化特征信息还包括人体语义结构化信息,那么可以对经过人脸比对的五个最近似目标轨迹再比对其人体语义结构化信息,确定最优的目标轨迹,将当前目标合并到最优的目标轨迹中形成更为精准的新的目标轨迹。由于采用的都是结构化信息比对,比对速度会较快而且准确。本发明通过行人检测追踪技术准确的获取监控视频中每个行人目标的轮廓,准确行人目标的轮廓提取就可以精确的提取每个目标对应的人脸特征和人体语义结构化特征,利用这些特征可以全景的描述一个行人目标。在多监控点下,本发明方法能够对行人目标的全景描述,准确搜索到出现在其他监控点下的同一个行人目标,勾画出行人目标在多个监控点下的运动轨迹。同时利用人脸特征可以与城市的人脸库或者重点人员库比较,快速确实行人目标的身份信息。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1