实现基于硬件加速的非标准浮点数重建算法的方法和设备与流程
本公开涉及ct重建,尤其涉及基于硬件加速(如,定点运算加速卡)的重建算法中的大规模累进求和运算以及以有限的带宽资源取得最优化的计算精度,提高图像质量。
背景技术:
在涉及ct等图像的重建算法(例如,包括反投影算法和迭代算法)中多层图像可包含数百万或数千万像素,而每个像素点的值又由数万个数值累进求和产生。其特点是数据量大且单个像素的操作次数大。
在现有的硬件加速技术中大规模累进求和运算采用基于定点数的运算方法,其缺点是需要额外的大量带宽来解决溢出问题、同时不能保证高精度运算结果。
在现有的硬件加速技术中大规模累进求和运算假如采用浮点运算,其缺点可能主要将有:1.需要在加速硬件上设计大量浮点运算资源,成本大幅度提高;2.32位单精度运算尚不能保证计算精度,对比显卡/gpu加速没有精度优势。专用的浮点运算芯片虽然性能优异,但价格十分昂贵,不如直接使用显卡/gpu加速,在ct等领域中没有实际应用价值。
在现有技术中如采用显卡/gpu加速,其缺点主要有:1.不能保证计算精度。2.长远来看性能/价格比不如专用的加速硬件。3.商用的显卡设计不够灵活,不能按实际需要改动,显存过小,长远来看不能适应迭代重建的需要。
技术实现要素:
根据本公开的一方面,一种基于硬件加速处理浮点数的方法包括:根据标准浮点数的位数来设置非标准浮点数的总位数;根据所述非标准浮点数的总位数来设置所述非标准浮点数的指数位的位数和小数位的位数,以使得指数位的位数和小数位的位数之和保持不变;以及执行所述非标准浮点数与所述标准浮点数的转换。
根据该方面的一示例性实施例,设置所述非标准浮点数的指数位的位数和小数位的位数进一步包括:将所述非标准浮点数的指数位的位数设置为小于所述标准浮点数的指数位的位数;以及相应地将所述非标准浮点数的小数位的位数设置为大于所述标准浮点数的小数位的位数。
根据该方面的一示例性实施例,该方法还包括:通过对定点数的二进制值进行移位来将所述定点数转换为非标准浮点数,其中所述移位包括基于所述定点数的小数部分的长度、所述非标准浮点数的小数部分的长度以及指数部分的值,对所述定点数的二进制值进行移位。
根据该方面的一示例性实施例,该方法进一步包括通过寻找所述定点数的第一个非0位的位置来得到所述非标准浮点数的指数部分的值。
根据本公开的又一方面,一种基于硬件加速来执行非标准浮点数的方法包括:通过对非标准浮点数的小数部分的值进行移位来将所述非标准浮点数逆转换为定点数,其中所述移位包括基于所述定点数的小数部分的长度、所述非标准浮点数的小数部分的长度以及指数部分的值,对所述非标准浮点数的小数部分的值进行移位。
根据本公开的再一方面,一种基于硬件加速来执行非标准浮点数的方法包括执行非标准浮点数与所述定点数的加法,其中所述非标准浮点数与所述定点数的和的小数部分通过对定点数的二进制值进行移位后将其与非标准浮点数的小数部分求和来获得,并且所述非标准浮点数与所述定点数的和的指数部分通过取所述非标准浮点数的指数部分来获得;其中所述移位包括基于所述定点数的小数部分的长度、所述定点数的总长度以及所述非标准浮点数的指数部分的值,对所述定点数的二进制值进行移位。
根据本公开的进一步方面,一种基于硬件加速来执行非标准浮点数的方法包括:执行非标准浮点数与定点数的乘法,其中所述非标准浮点数与所述定点数的积的二进制值是通过将所述非标准浮点数的小数部分的值与所述定点数的二进制值相乘后对积进行相应移位来获得,并且所述移位包括基于所述积的小数部分的长度、所述非标准浮点数的小数部分的长度、所述非标准浮点数的指数部分的值以及所述定点数的小数部分的长度来对所述积的二进制值进行移位。
本公开还涉及一种基于硬件加速处理浮点数的设备,包括:处理器,其被配置成执行以上任何一项所述的方法;以及存储器,其被配置成耦合到所述处理器。
本公开进一步涉及一种其上存储有计算机可执行指令的计算机可读介质,所述计算机可执行指令在由处理器执行时使得所述处理器执行以上任何一项所述的方法。
本公开的再一方面涉及一种用于ct图像重建的系统,包括扫描器,用于获得ct原始图像;处理模块,用于基于所述ct原始图像通过执行以上权利要求1–6中的任何一项所述的方法或其任何组合来进行重建处理;以及显示器,用于显示重建出的ct图像。
附图说明
图1示出了根据本公开的一种基于硬件加速处理浮点数的方法的流程图。
图2是根据第一示例性实施例的采用非标准浮点计算的(子)流程;
图3是根据第二示例性实施例的采用非标准浮点计算的(子)流程;
图4是根据第三示例性实施例的采用非标准浮点计算的(子)流程;并且
图5是根据第四示例性实施例的采用非标准浮点计算的(子)流程。
图6是根据本公开一示例性实施例的ct图像重建系统。
具体实施方式
将参照附图详细描述各实施例。在可能之处,相同附图标记将贯穿附图用于指代相同或类似部分。对特定示例和附图所作的引用是用于解说性目的,而无意限定本发明或权利要求的范围。措辞“示例性”在本文中用于表示“用作示例、实例或解说”。本文中描述为“示例性”的任何实现不必然被解释为优于或胜过其他实现。
重建算法(诸如但不限于ct重建算法)通常涉及大规模累进求和运算。以ct重建算法作为示例性而非限定性示例,其中的多层图像可包含例如数百万或数千万像素,而每个像素点的值又由例如数万个数值累进求和产生。数据量极大且单个像素的操作次数大。本领域中希望能以有限的带宽资源取得最优化的计算精度,提高图像质量。
下文以ct重建算法为例来讨论各个实施例,但本领域普通技术人员明了,本公开并不被限定于ct重建,而是可适用于其他相关领域,例如其它模态的图像重建工作。
在现有技术的ieee标准中,32位的单精度浮点数例如由8个指数位、23个小数位、1个符号位组成。
所谓非标准浮点数指的是非ieee标准下的浮点数格式。在本公开中,非标准浮点数可以不限制指数位和小数位的个数,而保持总位数不变。例如,在与现有技术ieee标准的32位单精度浮点数对比的情况下,本公开的非标准浮点数在保持总数为32位不变的前提下,可以不限制指数位和小数位的个数。但是,如本领域普通技术人员所能明了的,本公开不限于32位的单精度浮点数的情形,而是可现成地应用于其他总位数和精度的浮点数。
图像ct值通常不超过2^16,故可以采用比标准单精度浮点数更少的指数位,如4个指数位,这样可以把小数位扩大到27位,其计算精度比单精度浮点数提高16倍。大幅度提高计算精度,可更好的保证迭代重建算法的稳定性,提高图像质量。
在一示例性实施例中,本公开的非标准浮点数中的指数位和小数位可按需要改变大小。例如,在具体实现中,对于本公开的非标准浮点数中的指数位和小数位,可按实际需要的精度和数值范围来确定优化的方案。
图1示出了根据本公开的一种基于硬件加速处理浮点数的方法100,包括在101,根据标准浮点数的位数来设置非标准浮点数的总位数;在102,根据所述非标准浮点数的总位数来设置所述非标准浮点数的指数位的位数和小数位的位数,以使得指数位的位数和小数位的位数之和保持不变;以及在103,执行所述非标准浮点数与所述标准浮点数的转换。该转换可包括非标准浮点数与标准浮点数之间的相互转换,并可进一步包括对非标准浮点数的缓冲、存储、以及与定点数的相互转换、相加和/或相乘及其各种组合等等。
作为示例性而非限定性示例,本公开可采用非标准浮点计算方法来处理硬件加速中的大规模累进求和运算问题。在一示例性而非限定性实施例中,本公开的非标准浮点计算系统的基本功能可以包括但不限于以下单元的各种组合(含单个单元的情形):
1.定点数-非标准浮点数转换器;
2.非标准浮点数的缓冲单元;
3.非标准浮点数的存储单元;
4.定点数-非标准浮点数加法器;
5.非标准浮点数-定点数逆转换器;
6.非标准浮点数-标准浮点数转换器;
7.非标准浮点数-定点数乘法器。
以下给出上述各种单元的示例性而非限定性实现示例。
在一示例性而非限定性实施例中,本公开的定点数-非标准浮点数转换器可将定点数按给定的指数位、小数位转换为本公开的非标准浮点数。
在一特定示例中,本公开的定点数-非标准浮点数转换器可进一步通过对定点数的二进制值进行移位来实现此转换。例如,该移位可基于例如该定点数的小数部分的长度、非标准浮点数的小数部分的长度以及指数部分的值等。
作为一示例性而非限定性示例,下面给出一个无符号定点数到非标浮点数转换的应用实例。
输入:定点数b
输出:无符号浮点数a,a=b
1.a.frac=b.bit>>(b.fraclength-a.fraclength+a.exp)
其中a.frac表示a的小数部分的值,a.exp表示a的指数部分的值;b.bit表示b的二进制值,a.fraclength表示a的小数部分的长度,b.fraclength表示b的小数部分的长度,>>表示向右移位运算,下同。
注意,这个示例性转换器只能按事先给定的a.exp执行转换,可能不具备根据数值大小随机浮点的功能,不是通用的定点数到浮点数的转换器。但在特定的条件下,可以适用于正反投影计算的具体需要。本领域普通技术人员在以上示例的基础上,可以明了其他替换、变形和修改,并且这些替换、变形和修改可以根据条件和需要来作出。
如果事先并不给定a.exp,则可以通过寻找b的第一个非0位的位置得到a.exp,然后再执行上述算法,并保存a.exp的值,如:
1.a.exp=firstnonzero(b)-b.fraclength
2.a.frac=b.bit>>(b.fraclength-a.fraclength+a.exp)
firstnonzero(b)表示b的第一个非0位的位置,其算法是众所周知的。这将多消耗至少1个时钟周期和b.bit个寄存器。本领域普通技术人员可以明了如何基于这些特性,根据需要作出适当的设计。
在一示例性而非限定性实施例中,本公开的非标准浮点数的缓冲单元可以是硬件加速卡的寄存器资源。但如本领域普通技术人员可以明了,其他缓冲单元也可适用于作为本公开的非标准浮点数缓冲单元。
在一示例性而非限定性实施例中,本公开的非标准浮点数存储单元可以是硬件加速卡上的ddr内存,非标准浮点数以例如32bit形式存储于存储单元上。但如本领域普通技术人员可以明了,其他存储单元也可适用于作为本公开的非标准浮点数存储单元。本公开中大规模中间数据以例如32bit为单位的标准二进制数保存在诸如ddr内存中,解决了保存和快速读写大规模中间结果的问题,不需要额外的压缩等处理。
在一示例性而非限定性实施例中,本公开的定点数-非标准浮点数加法器可以是基于硬件加速设计的非标准加法器,其功能是计算一个定点数与一个非标准浮点数的和,结果输出为非标准浮点数。
作为一示例性而非限定性示例,给出一个无符号非标浮点数与无符号定点数加法器的应用实例:
输入:非标浮点数a,无符号定点数b,且满足a>b。
a=0.(a.frac)*2^a.exp;b=b.bit*2^-b.fraclength
其中a.frac表示a的小数部分的值,a.exp表示a的指数部分的值;b.bit表示b的二进制值,b.bitlength表示b的总长度,b.fraclength表示b的小数部分的长度。
输出:非标浮点数c,c=a+b。
1.c.frac=a.frac+(b.bit>>(a.exp-b.bitlength+b.fraclength))
c.exp=a.exp
2.ifcoverflow
c.frac=c.frac>>1
e.exp=c.exp+1
endif
该示例性应用实例可能仅适合a>b的情形,不是通用的加法器,但适合在正反投影的累加计算中使用。
本公开设计的示例性定点数-非标准浮点数加法器可例如在2个时钟周期内完成一次定点数-非标准浮点数加法,避免定点数-非标准浮点数转换过程中的延迟,并减少一次截位(或舍入)计算。
本公开中大规模累进求和运算由定点数-非标准浮点数加法器完成,有效的解决了至少以下问题,例如:
(1)单独采用定点数加法器可导致溢出从而需要大量额外带宽的问题;
(2)单独采用浮点运算需要专用的浮点运算单元,不具备可行性。
在一示例性而非限定性实施例中,本公开的特殊设计的定点数-非标准浮点数加法器不但可以完成类似于浮点加法器的功能,还提高了计算精度。
在一示例性而非限定性实施例中,本公开的非标准浮点数-定点数转换器可将非标准浮点数按给定的定点数长度、移位转换为定点数。
作为一示例性而非限定性示例,下面给出一个非标浮点数到无符号定点数转换的应用实例:
输入:非标浮点数a
输出:定点数b,b=a
1.b.bit=a.frac<<(b.fraclength-a.fraclength+a.exp)
其中a.frac表示a的小数部分的值,a.exp表示a的指数部分的值;b.bit表示b的二进制值,a.fraclength表示a的小数部分的长度,b.fraclength表示b的小数部分的长度,<<表示向左移位运算,下同。
本领域普通技术人员在以上示例的基础上,可以明了其他替换、变形和修改,并且这些替换、变形和修改可以根据条件和需要来作出。
上述例子中左移位运算可能产生截位,该截位不额外消耗时钟周期和资源。该截位也可以用舍入运算代替,以便在必要的时候略微提高计算精度,如:
b.bit=round(a.frac<<(b.fraclength-a.fraclength+a.exp))
用舍入运算(round)代替截位将多消耗1~2个时钟周期和0~1个寄存器资源(具体数量由不同的舍入运算方法决定)。本领域普通技术人员应明了舍入运算的多种不同的公开算法,可根据需要选择合理的设计。
在一示例性而非限定性实施例中,本公开的非标准浮点数-定点数乘法器可计算一个非标准浮点数与一个定点数的乘积,输出为定点数。
作为一示例性而非限定性示例,下面给出一个无符号非标浮点数与无符号定点数乘法器的应用实例:
输入:非标浮点数a,无符号定点数b,且满足a>=0
输出:定点数c,c=a*b
1.c.bit=a.frac*b.bit
2.c.bit=c.bit<<(c.fraclength-a.fraclength+a.exp-b.fraclength)
其中a.frac表示a的小数部分的值,a.exp表示a的指数部分的值;b.bit表示b的二进制值,c.bit表示c的二进制值,a.fraclength表示a的小数部分的长度,b.fraclength表示b的小数部分的长度,c.fraclength表示c的小数部分的长度。
本发明设计的非标准浮点数-定点数乘法器可以解决迭代算法过程中的正投影计算,避免非标准浮点数-定点数转换过程中的延迟,并减少一次截位(或舍入)计算。
本领域普通技术人员在以上示例的基础上,可以明了其他替换、变形和修改,并且这些替换、变形和修改可以根据条件和需要来作出。本领域技术人员应当理解,本例中的非标浮点数a>=0,但是本领域普通技术人员在本公开的教导下能够显而易见地得到涉及a<0的变化例,而这也在本公开的范围之内。
同上,上述例子中左移位运算可能产生截位。该截位也可以用舍入运算代替,以便在必要的时候略微提高计算精度,如:
c.bit=round(c.bit<<(c.fraclength-a.fraclength+a.exp-b.fraclength))
用舍入运算(round)代替截位将多消耗1~2个时钟周期和0~1个寄存器资源(具体数量由不同的舍入运算方法决定)。本领域普通技术人员应明了舍入运算的多种不同的公开算法,可根据需要选择合理的设计。
在一示例性而非限定性实施例中,本公开的非标准浮点数-像素转换器可以是在重建软件上实现的,而不是硬件加速卡的一部分,其功能是把硬件加速卡返回的图像的非标准浮点数像素值转换为符合dicom标准的像素值。但如本领域普通技术人员可以明了,其他能够实现非标准浮点数-像素转换功能的单元也可适用于作为本公开的非标准浮点数-像素转换器。
本领域普通技术人员应当理解,以上具体参数是作为示例给出的,而并不意图旨在构成限定。并且具体所采用的参数可根据偏好或需要来设计,也可根据相关技术标准的变动而相应调整。
例如,在本公开的非标准浮点数中,指数位不限于被减少到4个,而可以是3个、5个或其他个数。而小数位则相应扩大,从而计算精度有相应的提高。这均是本领域普通技术人员在本申请的基础上能够显而易见地直接得到的,故而落在本申请的保护范围内。
如本领域普通技术人员从以上各种示例性实施例可以直接而毫无疑义地确定的,上述各个示例性运算器是以涉及无符号非标浮点数与无符号定点数的运算器为例来描述的,但是有符号非标浮点数与有符号定点数的对应运算器能在以上示例性实施例的基础上现成地实现。
在此基础上,以下结合附图来说明各种示例性非标准浮点计算(子)流程。
例如,在硬件加速卡上根据不同的算法要求可有例如以下四种采用非标准浮点计算的(子)流程,这些子流程是总体重建算法的组成部分。
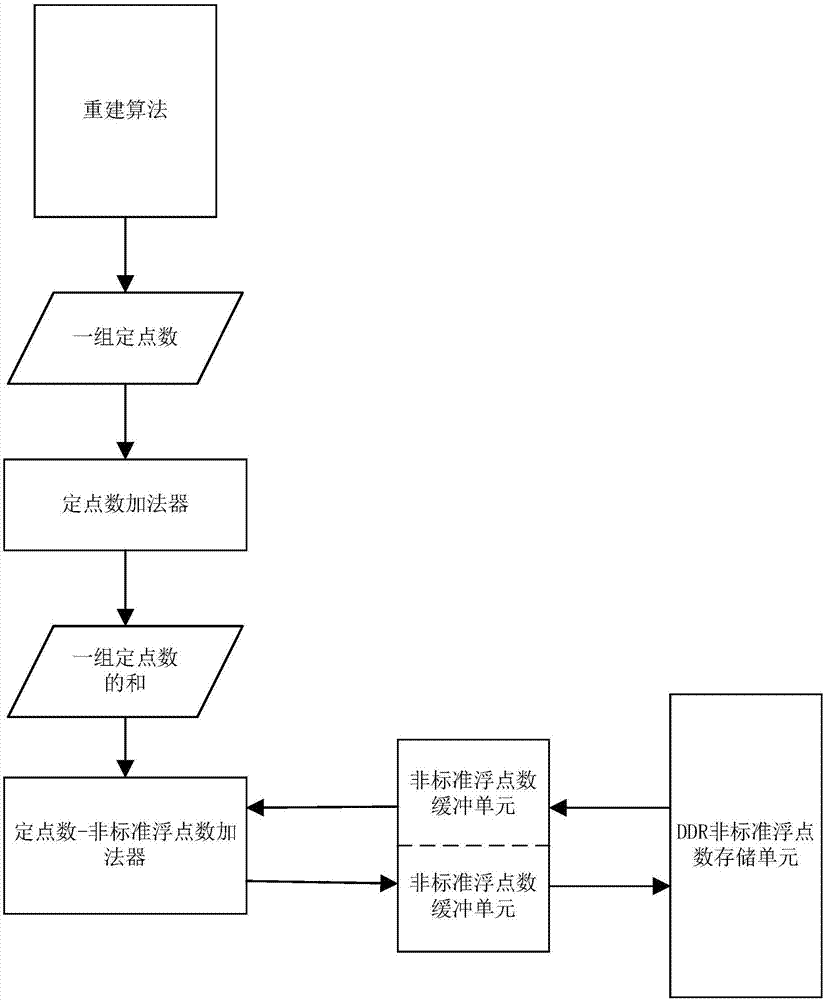
[(子)流程1]
如图2中所示,(子)流程1可涉及从重建算法获得一组定点数,使用定点数加法器对该组定点数进行计算并得到该组定点数的和,进一步使用定点数-非标准浮点数加法器将该组定点数的和与来自ddr非标准浮点数存储单元并经非标准非标准浮点数缓冲单元缓冲的非标准浮点数相加,其结果经非标准浮点数缓冲单元缓冲,并被存储回ddr非标准浮点数存储单元。此定点数-非标准浮点数加法可以迭代地执行。
[(子)流程2]
如图3中所示,(子)流程2可涉及从重建算法获得一组定点数,使用定点数加法器对该组定点数进行计算并得到该组定点数的和,进一步使用定点数-非标准浮点数转换器对该组定点数的和进行转换,其结果经非标准浮点数缓冲单元缓冲后由ddr非标准浮点数存储单元存储。
[(子)流程3]
如图4中所示,(子)流程3可涉及从ddr非标准浮点数缓冲单元取得非标准浮点数,经非标准浮点数缓冲单元缓冲后,由非标准浮点数-定点数转换器转换为定点数,并将结果提供给重建算法。
[(子)流程4]
如图5中所示,(子)流程4可涉及从ddr非标准浮点数缓冲单元取得非标准浮点数,经非标准浮点数缓冲单元缓冲后,由非标准浮点数-定点数乘法器将其与一组定点数相乘,并将结果提供给重建算法。
以ct重建算法为例,其通常包括反投影算法和迭代算法。通常,反投影算法可例如用到其中的第1、2种(子)流程;迭代算法可例如用到第1、2、3、4种(子)流程。本领域技术人员应理解,根据实际需要,本领域普通技术人员可现成地对上述4种(子)流程进行各种排列组合以达到预期的目的。
如前所述,本公开设计的示例性定点数-非标准浮点数加法器可在提高计算精度的情况下,在例如2个时钟周期内完成一次定点数-非标准浮点数加法,避免定点数-非标准浮点数转换过程中的延迟,并减少一次截位(或舍入)计算;同理,本公开涉及的示例性定点数-非标准浮点数乘法器也能够相应地提高计算精度并减少延迟和计算资源。此外,本公开的定点数-非标准浮点数转换器、非标准浮点数的缓冲单元、非标准浮点数的存储单元、非标准浮点数-定点数逆转换器以及非标准浮点数-标准浮点数转换器均能够实现相应的性能提升。
因此,上述(子)流程中的每一者均能基于其所用到的单元而获得相应改善的性能,而通过组合上述(子)流程来实现的各种算法进一步能够获得相应的性能提升。不仅如此,根据偏好和需要,本领域普通技术人员能够对其参数进行设置和改动,以便适应于迭代重建的需要,以及灵活适应于各种现行/将来标准。
图6是根据本公开一示例性方面的ct图像重建系统600。该ct图像重建系统600包括扫描器610以及与之耦合的处理模块620和显示器630。扫描器610进一步包括检测器611。
在一示例性而非限定性的实施例中,扫描器610通过使用检测器611来对人体或其部位等进行扫描并获得原始数据。所获得的数据可被传递到处理模块620以进行处理。例如,根据一示例性而非限定性的实施例,以上所描述的各种单元(例如,单元1–7)或其任何组合、参照图2–图5描述的各种(子)流程及其任何组合、以及其他各种相关处理可在处理模块620处执行。本领域普通技术人员将理解,根据不同实现,处理模块620也可被纳入在扫描器610内或显示器630内或实现为单独的硬件等。
经处理模块620重建得到的数据可被传送给例如扫描器610、显示器630、和/或其他组件(未示出)以进行相应的进一步操作(例如,提供给显示器630显示等)。
本领域普通技术人员应理解,本发明的有益效果并非由任何单个实施例来全部实现。各种组合、修改和替换均为本领域普通技术人员在本发明的基础上所明了。
此外,术语“或”旨在表示包含性“或”而非排他性“或”。即,除非另外指明或从上下文能清楚地看出,否则短语“x采用a或b”旨在表示任何自然的可兼排列。即,短语“x采用a或b”藉由以下实例中任何实例得到满足:x采用a;x采用b;或x采用a和b两者。另外,本申请和所附权利要求书中所用的冠词“一”和“某”一般应当被理解成表示“一个或多个”,除非另外声明或者可从上下文中清楚看出是指单数形式。
各个方面或特征将以可包括数个设备、组件、模块、及类似物的系统的形式来呈现。应理解和领会,各种系统可包括附加设备、组件、模块等,和/或可以并不包括结合附图所讨论的全部设备、组件、模块等。也可以使用这些办法的组合。
结合本文所公开的实施例描述的各种说明性逻辑、逻辑块、模块、和电路可用通用处理器、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或其它可编程逻辑器件、分立的门或晶体管逻辑、分立的硬件组件、或其设计成执行本文所描述功能的任何组合来实现或执行。通用处理器可以是微处理器,但在替换方案中,处理器可以是任何常规的处理器、控制器、微控制器、或状态机。处理器还可以被实现为计算设备的组合,例如dsp与微处理器的组合、多个微处理器、与dsp核心协同的一个或多个微处理器、或任何其它此类配置。此外,至少一个处理器可包括可作用于执行以上描述的一个或多个步骤和/或动作的一个或多个模块。
此外,结合本文中所公开的方面描述的方法或算法的步骤和/或动作可直接在硬件中、在由处理器执行的软件模块中、或在这两者的组合中实施。
本发明中通篇描述的各种方面的要素为本领域普通技术人员当前或今后所知的所有结构上和功能上的等效方案通过引述被明确纳入于此,且意在被权利要求书所涵盖。此外,本文所公开的任何内容都并非旨在贡献给公众——无论这样的公开是否在权利要求书中被显式地叙述。
- 还没有人留言评论。精彩留言会获得点赞!