种子用户确定方法与流程
本发明涉及数据处理技术,尤其涉及一种种子用户确定方法。
背景技术:
随着web2.0技术和在线社交网络的出现和迅猛发展,人们使用互联网的方式发生了深刻变革——由单纯的网页浏览和信息搜索转向各类社交网络上社会关系的构建与维护、基于社会关系的信息发布、交流和共享。社会影响力是社交网络中常见的一种现象,具体是指由于用户、组织或者社区与其他用户、组织或者社区等具有社交关系,导致自身行为随其他用户、组织或者社区变化而变化的一种现象。通过对社交网络中节点、用户等个体的影响力进行分析,可以发现社交网络中的具有重要影响力的种子用户,可用于企业商业营销、广告定向投放、言论渠道推荐、舆情监控等诸多领域。
目前的一些研究中将种子用户确定的问题转化为对其他用户偏好影响力最大化问题,提出了一种贪心算法对该问题进行求解,即每一步都选择当前对其他用户偏好最具影响力的用户作为当前最高影响力用户,直到将所有数据枚举完时的当前最高影响力用户作为种子用户。
现有技术确定种子用户的效率不高。
技术实现要素:
本发明提供一种种子用户确定方法,包括:
根据预设的区域从属关系确定a个最小签到区域,其中,所述a为大于等于1的整数;
针对每个所述最小签到区域,获取所述最小签到区域对应的签到用户和所述签到用户的偏好话题;
获取所述最小签到区域的第一影响力列表,所述第一影响力列表包含针对所述偏好话题对应的签到用户的影响用户,以及所述影响用户对所述签到用户的影响力值;
根据查询区域、多个查询话题和所述区域从属关系,获取b个子覆盖区域;每个所述子覆盖区域包含一个最小签到区域,和/或,每个所述子覆盖区域包含d个最小签到区域的部分签到位置;其中,所述最小签到区域对应签到用户的偏好话题,所述偏好话题包含x个所述查询话题;所述最小签到区域的部分签到位置对应签到用户的偏好话题,所述偏好话题包含y个所述查询话题,所述b为大于等于2的整数,所述d、x、y分别为大于等于1的整数;
针对每个子覆盖区域,获取所述每个子覆盖区域针对所述查询话题的第二影响力列表,并获取第二影响力列表中针对查询话题的影响力值最大的第二影响力值;
根据获取的b个第二影响力值确定所述查询区域的第一影响力阈值;
获取最大的第二影响力值对应的影响用户在所述查询区域的第三影响力值;
从历史获取的第三影响力值中确定最大第三影响力值,并确定所述最大第三影响力值是否大于或等于所述第一影响力阈值:
若所述最大第三影响力值大于或等于所述第一影响力阈值,则获取所述当前最大第三影响力值对应的影响用户为第一种子用户。
进一步地,还包括:若所述最大第三影响力值小于所述第一影响力阈值,则对所述第二影响力列表进行第一类更新;
根据进行第一类更新后的第二影响力列表,执行所述获取在第二影响力列表中针对查询话题的影响力值最大的第二影响力值,直到获取到所述第一种子用户。
进一步地,还包括:在获取所述第一种子用户之后,从所述第二影响力列表中删除已获取的种子用户获得新的第二影响力列表,所述已获取的种子用户包含所述第一种子用户;
根据新的第二影响力列表获取第二影响力列表中针对查询话题的影响力值最大的第四影响力值,
以获取的b个第四影响力值之和为所述查询区域的第二影响力阈值;
获取所述最大的第四影响力值对应的影响用户在所述查询区域的第五影响力值,并将所述第五影响力值确定为初始状态;从历史获取的第五影响力值中确定最大第五影响力值,并确定所述最大第五影响力值是否大于等于所述第二影响力阈值,
若所述最大第五影响力值小于所述第二影响力阈值,则执行所述获取最大的第四影响力值对应的影响用户在所述查询区域的第五影响力值,
若所述最大第五影响力值大于等于所述第二影响力阈值,则检测所述最大第五影响力值的状态,
若所述最大第五影响力值为初始状态,则更新所述最大第五影响力值为估计状态,执行所述从历史获取的第五影响力值中确定最大第五影响力值,
若所述最大第五影响力值为估计状态,则更新所述最大第五影响力值为准确状态,执行所述从历史获取的第五影响力值中确定最大第五影响力值,
若所述最大第五影响力值为准确状态,则获取所述最大第五影响力值对应的影响用户为后续种子用户,删除所述历史获取的第五影响力值中所述已获取的种子用户对应的第五影响力值,执行所述从所述第二影响力列表中删除已获取的种子用户获得新的第二影响力列表,直到获取所述后续种子用户的数量满足qk-1,所述qk为查询个数。
进一步地,所述获取所述最小签到区域的第一影响力列表具体包括:
根据获取的针对所述偏好话题的签到用户获取所述影响用户;
根据所述影响用户u对所述签到用户v的影响因子p(u,v)、所述签到用户v对所述最小签到区域的偏好值γ(v,rj)以及所述签到用户v对所述话题t的偏好值
进一步地,所述针对每个子覆盖区域,获取所述每个子覆盖区域的第二影响力列表具体包括:
若所述子覆盖区域包含一个针对查询话题的最小签到区域,则确定所述第二影响力列表包括:针对所述查询话题的签到用户的影响用户,以及所述影响用户对所述签到用户针对所述查询话题的影响力值;
若所述子覆盖区域包含d个针对查询话题的最小签到区域的部分签到位置,则确定所述第二影响力列表包括:在所述部分签到位置针对所述查询话题的签到用户的影响用户,以及所述影响用户对所述签到用户针对所述查询话题的影响力值。
进一步地,所述根据获取的b个第二影响力值确定所述查询区域的第一影响力阈值具体包括:对获取的b个第二影响力值求和获得所述第一影响力阈值。
进一步地,所述对所述第二影响力列表进行第一类更新具体包括:从所述第二影响力列表中删除当前的所述第二影响力值。
进一步地,所述更新所述最大第五影响力值为估计状态的同时还包括:
将所述最大第五影响力值更新为
进一步地,所述更新所述最大第五影响力值为准确状态的同时还包括:
将所述最大第五影响力值更新为σst({u∪s},q)-σst(s,q),其中所述σst({u∪s},q)为已确定的种子用户集合s和估计状态的所述最大第五影响力对应的影响用户u在查询区域针对查询话题的影响力值,所述σst(s,q)为种子用户集合s对查询区域和查询话题的影响力值,q为包含查询区域qr和查询话题qt的查询条件。
进一步地,所述根据预设的区域从属关系确定a个最小签到区域包括:
以所述区域从属关系作为树形节点的层级关系确定一树形索引,所述树形节点存储所述最小签到区域、所述最小签到区域对应签到用户的偏好话题和至少一指向文档的指针,所述指针指向的文档包含所述最小签到区域对应的签到用户、所述签到用户的总签到次数、所述签到用户在所述最小签到区域中的签到次数、所述签到用户的偏好话题及所述用户对所述偏好话题的偏好值。
本发明获取每个子覆盖区域针对查询话题的影响力值最大的第二影响力值;根据获取的b个第二影响力值确定第一影响力阈值;获取最大的第二影响力值对应的影响用户在查询区域的第三影响力值;从历史第三影响力值中确定最大第三影响力值,若最大第三影响力值大于或等于第一影响力阈值,
则获取最大第三影响力值对应的影响用户为第一种子用户。本发明通过上述方法提高了确定种子用户的效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明的一种种子用户确定方法流程图;
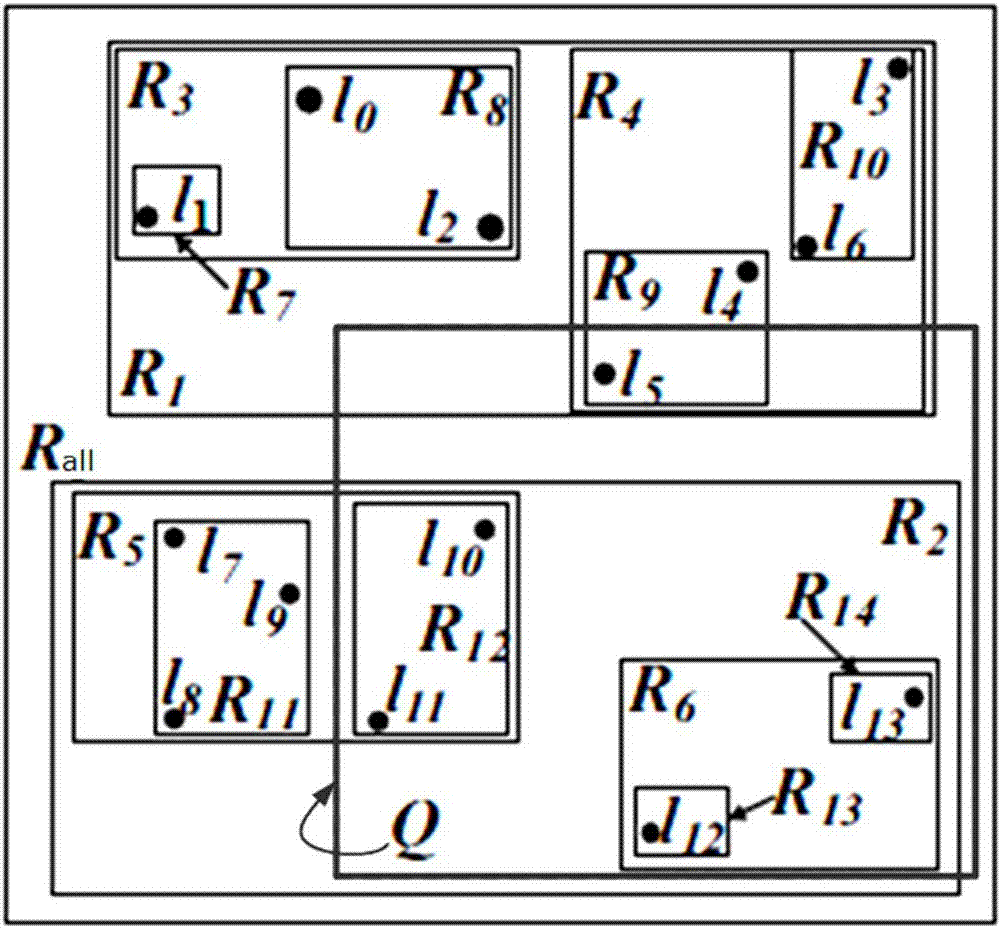
图2为本发明的一种区域从属关系的实施例;
图3为本发明的后续种子用户确定方法流程图;
图4为以预设的区域从属关系作为树形节点的层级关系确定的树形索引结构。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1为本发明的一种种子用户确定方法流程图。如图1所示,本发明提供了一种种子用户确定方法,包括:
s110,根据预设的区域从属关系确定a个最小签到区域,其中,所述a为大于等于1的整数。
图2为本发明的一种区域从属关系的实施例。图2中以矩形框范围划分所示的区域从属关系,每个矩形框为一包含其范围内所有签到位置的最小签到区域。具体地,如图2所示,r3是指包含签到位置l0、l1、l2的最小签到区域,而r3又进一步包含r7和r8。r8是由签到位置l0、l2组成的最小签到区域。r7是由签到位置l1组成的最小签到区域。
本实施例中s110依据预设的所述区域从属关系来对包含签到位置的最小签到区域进行确定。该区域从属关系中签到位置和最小签到区域的划分可以不与实际地理位置完全对应,例如最小签到区域r8包含的签到位置l0为北京,l2为巴基斯坦;r7包含的签到位置l1为南昌。
s120,针对每个所述最小签到区域,获取所述最小签到区域对应的签到用户和所述签到用户的偏好话题。
步骤s120中根据最小签到区域可以获得最小签到区域中的签到用户,而根据签到用户则可以对应获得该用户对应的偏好话题和其他信息,参见表1.表1为本发明的一种签到用户信息表。
表1
s130,获取所述最小签到区域的第一影响力列表,所述第一影响力列表包含针对所述偏好话题对应的签到用户的影响用户,以及所述影响用户对所述签到用户的影响力值。
s130中所述获取所述最小签到区域的第一影响力列表具体包括:
根据获取的针对所述偏好话题的签到用户获取所述影响用户;
根据所述影响用户u对所述签到用户v的影响因子p(u,v)、所述签到用户v对所述最小签到区域的偏好值γ(v,rj)以及所述签到用户v对所述话题t的偏好值
对于每个最小签到区域ri,其中的偏好话题t∈ri.ts都中第一影响力列表
可选地,其中
可选地,为每个用户u存储一个索引列表
s140,根据查询区域、多个查询话题和所述区域从属关系,获取b个子覆盖区域;每个所述子覆盖区域包含一个最小签到区域,和/或,每个所述子覆盖区域包含d个最小签到区域的部分签到位置;其中,所述最小签到区域对应签到用户的偏好话题,所述偏好话题包含x个所述查询话题;所述最小签到区域的部分签到位置对应签到用户的偏好话题,所述偏好话题包含y个所述查询话题,所述b为大于等于2的整数,所述d、x、y分别为大于等于1的整数。
具体地,给定查询条件q={qr,qt,qk},qr为查询区域,qt为查询话题,qk为查询个数。首先从图2所示的区域从属关系的r0开始遍历该区域从属关系,并找到由被查询条件完全覆盖的一个最小签到区域构成的子覆盖区域rq={r1,...,ri,...rn},其中,子覆盖区域
s151,针对每个子覆盖区域,获取所述每个子覆盖区域针对所述查询话题的第二影响力列表。
若所述子覆盖区域包含一个针对查询话题的最小签到区域,则确定所述第二影响力列表包括:针对所述查询话题的签到用户的影响用户,以及所述影响用户对所述签到用户针对所述查询话题的影响力值。对子覆盖区域ri∈rq,每个子覆盖区域ri对应获得一与第一影响力列表相同的第二影响力列表
其中,
在如图2所示的区域从属关系中,查询条件q的查询区域将r12、r6完全覆盖,若查询话题分别与r12、r6的交集不为空集,则r12、r6为两个所述子覆盖区域。
若所述子覆盖区域包含d个针对查询话题的最小签到区域的部分签到位置,则确定所述第二影响力列表包括:在所述部分签到位置针对所述查询话题的签到用户的影响用户,以及所述影响用户对所述签到用户针对所述查询话题的影响力值。对于子覆盖区域r0,获得由多个二元组
p(u,v)是影响用户u对偏好子覆盖区域r0的签到用户v的影响因子,
在如图2所示的区域从属关系中,查询条件q的查询区域将r9的部分签到位置(签到位置l5)覆盖,获取签到位置l5上签到用户的偏好话题,若查询话题与l5上签到用户的偏好话题的交集不为空集,则l5包含于所述子覆盖区域r0中。可选地,第二影响力列表
在一种可选的实施例中包含b=3个子覆盖区域。表2为一种3个子覆盖区域对应获取的3个第二影响力列表的示例。第二影响力列表中按照
表2
s152,获取第二影响力列表中针对查询话题的影响力值最大的第二影响力值。
对于b个第二影响力列表
s160,根据获取的b个第二影响力值确定所述查询区域的第一影响力阈值
作为一种可选的第一影响力阈值计算方法,包括以获取的所述b个第二影响力值求和获得所述第一影响力阈值
表2中首次获取的第二影响力值10、30、50对应的首次获取的第一影响力阈值为90。
s170,获取最大的第二影响力值对应的影响用户在所述查询区域的第三影响力值。
具体地,获取
由于第二影响力列表
s180,从历史获取的第三影响力值中确定最大第三影响力值,并确定所述最大第三影响力值是否大于或等于所述第一影响力阈值。
可选地,动态优先队列
s181,若所述最大第三影响力值大于或等于所述第一影响力阈值,则获取所述当前最大第三影响力值对应的影响用户为第一种子用户。结束第一种子用户的获取流程。
图3为本发明的后续种子用户确定方法流程图。
如图3所示,还包括s182,若所述最大第三影响力值小于所述第一影响力阈值,则对所述第二影响力列表进行第一类更新;根据进行第一类更新后的第二影响力列表,执行s152所述获取在第二影响力列表中针对查询话题的影响力值最大的第二影响力值,直到获取到所述第一种子用户。
可选地,所述对所述第二影响力列表进行第一类更新具体包括:从所述第二影响力列表中删除当前的所述第二影响力值。
由于后续种子用户可能与当前已获得的种子用户集合有共同的影响力,因此,需要对如何选择第一个种子用户和如何选择后续种子用户分别求解。
在查询个数大于1的情况下,在获取所述第一种子用户之后还包括:
s210,从所述第二影响力列表中删除已获取的种子用户获得新的第二影响力列表,所述已获取的种子用户包含所述第一种子用户。
s220,根据新的第二影响力列表获取第二影响力列表中针对查询话题的影响力值最大的第四影响力值。
对于第二影响力列表
s230,以获取的b个第四影响力值之和为所述查询区域的第二影响力阈值。
s240,获取所述最大的第四影响力值对应的影响用户在所述查询区域的第五影响力值,并将所述第五影响力值确定为初始状态。本步骤的计算方法参见前述步骤s170。将最大第四影响力值对应的影响用户和其在查询区域上的第五影响力值σst(u,qr)加入一动态优先队列
s250,从历史获取的第五影响力值中确定最大第五影响力值,并确定所述最大第五影响力值是否大于等于所述第二影响力阈值。
可选地,动态优先队列
若所述最大第五影响力值小于所述第二影响力阈值,则执行s240,
若所述最大第五影响力值大于等于所述第二影响力阈值,则进入s260。
如图3所示,s260进一步包括:
s261,检测所述最大第五影响力值的状态.
s262,若所述最大第五影响力值为初始状态,则更新所述最大第五影响力值为估计状态,执行s250。
具体地,所述更新所述最大第五影响力值为估计状态的同时还包括:
将所述最大第五影响力值更新为
s263,若所述最大第五影响力值为估计状态,则更新所述最大第五影响力值为准确状态,执行s250。
具体地,所述更新所述最大第五影响力值为准确状态的同时还包括:
将所述最大第五影响力值更新为σst({u∪s},q)-σst(s,q),其中所述σst({u∪s},q)为已确定的种子用户集合s和估计状态的所述最大第五影响力对应的影响用户u在查询区域针对查询话题的影响力值,所述σst(s,q)为种子用户集合s对查询区域和查询话题的影响力值,q为包含查询区域qr和查询话题qt的查询条件。
s264,若所述最大第五影响力值为准确状态,则获取所述最大第五影响力值对应的影响用户为后续种子用户。
s265,判断后续种子用户的数量是否满足qk-1,所述qk为查询个数。
s266,若后续种子用户的数量满足qk-1,则确定所述第一种子用户和所述后续种子用户为种子用户结合s;
s267,若后续种子用户的数量不满足qk-1,则删除所述历史获取的第五影响力值中所述已获取的种子用户对应的第五影响力值,执行s210。直到获取所述后续种子用户的数量满足qk-1。
对第五影响力值设置状态,根据状态进行响应的更新计算,能够有效地对加速计算过程。准确状态下第五影响力值的计算的过程较为繁杂,需要相对较多的计算量。而在本方法的s240-s260中,初始状态和估计状态相对较小的影响用户可以避开准确状态下第五影响力值的计算,将计算量集中在当前
步骤s250-s260的一种可选实施例为:
动态优先队列
选择
如果u的状态是“初始”且第五影响力值
如果u的状态是“估计”且第五影响力值
如果u的状态是“准确”且第五影响力值
否则,再返回当前第二影响力列表
本发明将确定种子用户集合s的问题转换为找一个集合s',使得集合s'中用户满足针对查询区域和查询话题的影响力值最大,且集合s'中的成员总量为查询个数,即
作为一种实现方式,所述根据预设的区域从属关系确定a个最小签到区域包括:
以所述区域从属关系作为树形节点的层级关系确定一树形索引,如图4所示。
所述树形节点存储所述最小签到区域、所述最小签到区域对应签到用户的偏好话题和至少一指向文档的指针,所述指针指向的文档包含所述最小签到区域对应的签到用户、所述签到用户的总签到次数、所述签到用户在所述最小签到区域中的签到次数、所述签到用户的偏好话题及所述用户对所述偏好话题的偏好值。
图4为以预设的区域从属关系作为树形节点的层级关系确定的树形索引结构。如图4,rj为根据预设的区域从属关系确定的最小签到区域,j=all,1,2,3,4,5,6。d_*为所述指针指向的文档,*=0,1,…,14。图4中的t1,t2,t3,t4,t5,t6为表1中所示的签到用户的偏好话题。图4中树形的节点分布依据图2所示的区域从属关系来确定。
给定一个查询条件,目标用户是对查询位置以及查询话题有偏好的用户,设计一个如图4所示的树形索引结构,并利用该树形索引结构,快速得到目标用户以及计算他们对查询的偏好值。
如图4所示,树形索引的结构具体包括:
1、叶子节点o:是由多个实体e组成的,每个实体包含一个三元组<pd,m,ts>,其中pd代表该实体指向文档d的指针,m代表该实体上所有位置组成的最小签到区域rj,ts代表该实体的话题集合。表3为本发明的最小签到区域r3对应节点指向的文档示例。如表3所示,实体e指向的文档d包含以下四部分:
u:对实体e的m和ts有偏好的用户集合;
tv:签到用户的话题偏好向量;
tn:签到用户所有签到的位置以及总次数;
ln:签到用户在m内签到的次数。
除此之外,叶子节点o还有一个指向文档o.d的指针,该文档o.d是通过合并所有属于叶子节点o的实体的文档构造的。o.d也由上述四部分组成。
表3
2、非叶子节点n:是由多个实体组成的,每个实体包含一个三元祖<pc,m,ts>,其中,pc代表指向孩子节点的指针,m代表该实体其所有孩子节点的最小签到区域,ts代表该实体其所有孩子节点的话题集合的交集。一个非叶子节点也包含一个指针指向文档n.d,该文档是通过合并所有孩子节点的文档构造的。其构造过程和叶子节点的文档的构造过程类似。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!