一种蒙古语手写识别方法和装置与流程
本发明涉及手写识别
技术领域:
,具体涉及一种蒙古语手写识别方法和装置。
背景技术:
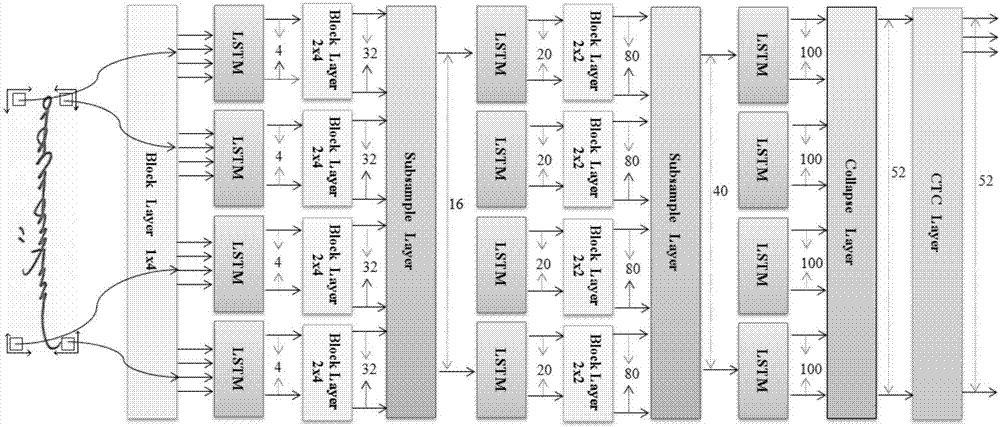
:基于传统的蒙古语字体的蒙古语在中国的内蒙古自治区被广泛使用。在手写识别技术广泛应用的当下,对于像蒙古语这种非通用语言的识别技术也应该被应用。但是,蒙古语被视为词态最复杂的语言之一,在蒙古语中,一个词根,尤其是动词的词根,可通过连接不同词缀而产生成数十上百的单词。例如,单词都是由词根连接不同后缀而衍生。据不完全统计,蒙古语词根近60000,如果考虑衍生的单词,蒙古语单词可能达到上百万。这种词态的丰富导致了高oov(out-of-vocabulary)率、数据稀疏问题以及语言模型高复杂度。这给实蒙古语的手写识别带来巨大挑战。所以,急需一种蒙古语的手写识别方法实现蒙古语的有效识别,解决现有技术中的高oov率问题。技术实现要素:鉴于上述问题,提出了本发明以便提供一种克服上述问题或者至少部分地解决上述问题的蒙古语手写识别方法和相应的装置。依据本发明的一个方面,提供了一种蒙古语手写识别方法,所述方法包括:建立蒙古语字素表;其中,所述蒙古语字素表中的字素与蒙古语字形对应,蒙古语单词由所述蒙古语字素表中的字素组成;训练基于所述蒙古语字素表的蒙古语手写识别模型;将待识别的手写图片输入所述蒙古语手写识别模型,获得所述蒙古语字素表中各字素包含在所述待识别的手写图片的各区域中的概率;根据所述概率,确定所述待识别的手写图片中的蒙古语语句。可选地,所述训练基于所述蒙古语字素表的蒙古语手写识别模型包括:建立二维时间递归神经网络-连续时间分类模型的拓扑结构;根据多个样本手写图片,使用所述拓扑结构训练基于所述蒙古语字素表的蒙古语手写识别模型。可选地,所述根据所述概率,确定所述待识别的手写图片中的蒙古语语句包括:根据所述概率,采用基于连续时间分类令牌传递算法的多单词解码算法,确定所述待识别的手写图片中的蒙古语语句;其中,所述多单词解码算法基于有限态状态传感器表述各蒙古语单词的词库,并在各蒙古语单词的末尾处基于语言模型进行计算。可选地,所述根据所述概率,采用基于连续时间分类令牌传递算法的多单词解码算法,确定所述待识别的手写图片中的蒙古语语句包括:建立蒙古语字典;其中,所述蒙古语字典中包括若干蒙古语单词,以及各蒙古单词对应的字素组成;根据所述概率,计算所述蒙古语字典中各蒙古语单词包含在所述待识别的手写图片中的概率;根据语言模型,依次确定所述待识别的手写图片中的蒙古语语句的各蒙古语单词。可选地,所述根据语言模型,依次确定所述待识别的手写图片中的蒙古语语句的各蒙古语单词包括:根据语言模型,获取所述蒙古语字典中各蒙古语单词作为句子首个单词的概率;计算各蒙古语单词包含在所述待识别的手写图片中的概率和对应的作为句子首个单词的概率的乘积,将乘积最大值对应的蒙古语单词确定为所述待识别的手写图片中的蒙古语语句的首个单词;根据语言模型,获取所述蒙古语字典中各蒙古语单词的上一个单词是确定出的首个单词的概率;计算各蒙古语单词包含在所述待识别的手写图片中的概率和对应的上一个单词是确定出的首个单词的概率的乘积,将乘积最大值对应的蒙古语单词确定为所述待识别的手写图片中的蒙古语语句的第二个单词;根据语言模型,获取所述蒙古语字典中各蒙古语单词的上两个单词是确定出的首个单词和第一个单词的概率;计算各蒙古语单词包含在所述待识别的手写图片中的概率和对应的上两个单词是确定出的首个单词和第一个单词的概率的乘积,将乘积最大值对应的蒙古语单词确定为所述待识别的手写图片中的蒙古语语句的第三个单词;以此类推,直到确定出所述待识别的手写图片中的蒙古语句中的所有单词。根据本发明的另一方面,提供了一种蒙古语手写识别装置,所述装置包括:字素表建立单元,用于建立蒙古语字素表;其中,所述蒙古语字素表中的字素与蒙古语字形对应,蒙古语单词由所述蒙古语字素表中的字素组成;识别模型训练单元,用于训练基于所述蒙古语字素表的蒙古语手写识别模型;字素概率获取单元,用于将待识别的手写图片输入所述蒙古语手写识别模型,获得所述蒙古语字素表中各字素包含在所述待识别的手写图片的各区域中的概率;蒙古语语句确定单元,用于根据所述概率,确定所述待识别的手写图片中的蒙古语语句。可选地,所述识别模型训练单元,用于建立二维时间递归神经网络-连续时间分类模型的拓扑结构;根据多个样本手写图片,使用所述拓扑结构训练基于所述蒙古语字素表的蒙古语手写识别模型。可选地,所述蒙古语语句确定单元,用于根据所述概率,采用基于连续时间分类令牌传递算法的多单词解码算法,确定所述待识别的手写图片中的蒙古语语句;其中,所述多单词解码算法基于有限态状态传感器表述各蒙古语单词的词库,并在各蒙古语单词的末尾处基于语言模型进行计算。可选地,所述蒙古语语句确定单元,用于建立蒙古语字典;其中,所述蒙古语字典中包括若干蒙古语单词,以及各蒙古单词对应的字素组成;根据所述概率,计算所述蒙古语字典中各蒙古语单词包含在所述待识别的手写图片中的概率;根据语言模型,依次确定所述待识别的手写图片中的蒙古语语句的各蒙古语单词。可选地,所述蒙古语语句确定单元具体用于,根据语言模型,获取所述蒙古语字典中各蒙古语单词作为句子首个单词的概率;计算各蒙古语单词包含在所述待识别的手写图片中的概率和对应的作为句子首个单词的概率的乘积,将乘积最大值对应的蒙古语单词确定为所述待识别的手写图片中的蒙古语语句的首个单词;根据语言模型,获取所述蒙古语字典中各蒙古语单词的上一个单词是确定出的首个单词的概率;计算各蒙古语单词包含在所述待识别的手写图片中的概率和对应的上一个单词是确定出的首个单词的概率的乘积,将乘积最大值对应的蒙古语单词确定为所述待识别的手写图片中的蒙古语语句的第二个单词;根据语言模型,获取所述蒙古语字典中各蒙古语单词的上两个单词是确定出的首个单词和第一个单词的概率;计算各蒙古语单词包含在所述待识别的手写图片中的概率和对应的上两个单词是确定出的首个单词和第一个单词的概率的乘积,将乘积最大值对应的蒙古语单词确定为所述待识别的手写图片中的蒙古语语句的第三个单词;以此类推,直到确定出所述待识别的手写图片中的蒙古语句中的所有单词。根据本发明的技术方案,首先建立蒙古语字素表;这里的蒙古语字素表中的字素与蒙古语字形对应,蒙古语单词由蒙古语字素表中的字素组成;训练基于蒙古语字素表的蒙古语手写识别模型;将待识别的手写图片输入蒙古语手写识别模型,获得蒙古语字素表中各字素包含在待识别的手写图片的各区域中的概率;根据概率,确定待识别的手写图片中的蒙古语语句。本发明是结合手写识别算法训练了基于字素的蒙古语识别模型,当利用该模型获得各字素的概率后,再确定待识别的手写图片中的蒙古语语句,有效的提高了蒙古语的手写识别率,降低识别的错词率,解决了高oov率的问题。上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。附图说明通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:图1示出了根据本发明一个实施例的一种蒙古语手写识别方法的流程示意图;图2示出了根据本发明一个实施例的mdlstm-ctc模型的结构示意图;图3示出了根据本发明一个实施例的一种待识别的手写图片的示意图;图4示出了根据本发明一个实施例的待识别的手写图片的解码过程示意图;图5示出了根据本发明一个实施例的单词w1和w2的fst示意图;图6示出了根据本发明一个实施例的单词w1和w2的确定fst示意图;图7示出了根据本发明一个实施例的一种蒙古语手写识别装置的结构示意图。具体实施方式下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。图1示出了根据本发明一个实施例的一种蒙古语手写识别方法的流程示意图。如图1所示,该方法包括:步骤s110,建立蒙古语字素表;其中,蒙古语字素表中的字素与蒙古语字形对应,蒙古语单词由蒙古语字素表中的字素组成。蒙古语是信息处理领域中最难的一种语言。从u+1820到u+1842是蒙古语字母的unicode十六进制代码。但因位置和上下文的不同,所有的字母有不同的字形。尽管蒙古语仅有35个字母,但其有近130种字形。蒙古语单词是由这些字形一个一个沿着垂直线组合的。比如,字形可以创造出单词意思是“人”,相应的unicode是“u+1820u+1837u+1820u+1833”。但有时,当两个字形连接在一起时,会形成一个新的字形。例如,字形会创造单词意思是父亲,而非组合成更具体的地,不同字母会有同一种字形,比如字形可能是字母或或显然,unicode不是手写识别的最好选择。在本实施例中,手写识别是基于蒙古语的子词元实现的。蒙古语语法提出了两种不同级别的子词元,一种是字素,一种是音节。但是根据蒙古语语法,音节有七种不同分解方式,即元音、元音+辅音、辅音+元音、辅音+元音+辅音、元音+辅音+辅音、辅音+元音+辅音+辅音、辅音+辅音+元音+辅音。音节总数是有限的,并不是所有元音辅音组合都是合法的音节。如果把字素选择为手写识别的子词元,可以覆盖所有的蒙古语单词,可以提高蒙古语的手写识别率,解决高oov率的问题。本实施例中的字素表是自定义的字素表,字素表中的每一个字素对应一个蒙古语字形。因为蒙古语单词是由蒙古语字形组成的,进而可以用字素表中的字素的不同组成结构代表不同的蒙古语单词。表1为本发明定义的一组字素,该字素表中的字素可以作为蒙古语的最小的分类单元。表1例如,如表1所示,蒙古语单词“人民”可以用字素“aazrazoax”表示。步骤s120,训练基于蒙古语字素表的蒙古语手写识别模型。本实施例中,训练的蒙古语手写识别模型是基于步骤s110中建立的蒙古语字素表进行的,主要是训练带有字素序列标记的连续时间分类(ctc)输出层的多维长短期记忆(mdlstm)。这里的连续时间分类(ctc)是ctc令牌传递算法的一个变体,可以易于与任何现存的n-gram语言模型(n-gramswm)结合。步骤s130,将待识别的手写图片输入蒙古语手写识别模型,获得蒙古语字素表中各字素包含在待识别的手写图片的各区域中的概率。步骤s140,根据概率,确定待识别的手写图片中的蒙古语语句。在步骤s130中获得概率值后并不能实现待识别的手写图片中的蒙古语语句,还需要有对待识别的手写图片进行解码的过程。在本实施例中,根据概率确定待识别的手写图片中的蒙古语语句只要是通过获得的概率值,结合n-gramswm和蒙古语字典进行解码,最终确定待识别的手写图片中的蒙古语语句。在本发明的一个实施例中,步骤s120中的训练基于蒙古语字素表的蒙古语手写识别模型包括:建立二维时间递归神经网络-连续时间分类模型的拓扑结构;根据多个样本手写图片,使用拓扑结构训练基于蒙古语字素表的蒙古语手写识别模型。这里的蒙古语手写识别模型是一个统计字素模型,可以通过下述的统计单词模型来实现。令w是总单词空间,v属于w是固定词库,s为子词空间。我们定义一个统计单词模型,用以分配优先可能性给子词序列:w=s1s2…sn(1)其中w属于w表示单词空间的任意单词,si属于s表示任何来自子词空间的子词,是n-l个子词的上下文。为了简化任务,一次仅仅识别一个单词,因此不考虑单词之间的转移概率。概率可以从v空间估计,并且可以用修正的kneser-ney平滑算法保留一些未知概率的概率质量。在本实施例中,识别模型是带有ctc输出层的深度mdlstm,模型主要由字素级别副本标记的样本手写图片来训练,且未包含关于何时字素会出现在一幅图片里的任何明示。mdlstm-ctc把一堆图片映射到每一时间步骤中字素的概率分布。下面对识别模型进行具体说明:(1)连续时间分类ctc是一个允许使用在输入序列和目标序列之间没有要求任何优先队列的序列副本任务来训练的神经网络的目标函数。通常ctc层是一softmax层,包含了与手稿标签加上额外的对空白f发送进行响应的空白标签的数量一样多的神经元。令是t时刻输出层k的概率,设st为由空格和字素组成的任意长度t的序列。通过输入图片x而产生的输出st的概率是每一时间步的发送概率之积。令st=f(l)为从目标序列到st的映射函数,f是在所有可能位置上的内嵌空白标签。所以概率p(l|x)为这意味着,ctc总结了所有的可能映射到l的序列,这是为何用为分割的数据来训练这个网络的原因。给一个目标文本y*,这个网络可被训练为最小化ctc目标函数。ctc(x)=-log(p(y*|x))(2)两维循环神经网络(rnn)循环神经网络最开始被作为扩展feedforward神经网络为数据强关联于一个单轴的序列数据的方法。但是手写图片是二维信息,因此用二维rnn处理更加合适。令x(i,j)为一个图片(尺寸为m*n)上的当前点,x(i-1,j)和x(i,j-1)是在当前点之前的两个维度的点。一个二维rnn计算了隐藏的向量序列h和通过迭代下面的等式输出向量序列y,其中i=1至m,j=1至n。hi,j=h(w1xi,j+w2hi-1,j+w3hi,j-1+b1)yi,j=w4hi,j+b2其中,w项表示权重矩阵,b项表示偏差矩阵,h是隐藏层激励方程。通常,x(i,j)是一个矢量(比如用一个小模块代替点)不是一个单一的数值。在上式中,当前点x(i,j)仅仅和x(i-1,j)x(i,j-1)相关,但实际上当前点应当也与x(i+1,j)x(i,j+1)相关。为找到所有附近的上下文,在四个方向扫描图片,然后把其放至分离的隐藏层中。标准rnns的一个缺点是未考虑梯度问题,阻止了长期依赖性。本实施例中的长短期记忆是一种特殊的rnn,可以学习长期依赖。(3)mdlstm-ctc模型的拓扑结构图2示出了根据本发明一个实施例的mdlstm-ctc模型的结构示意图。如图2所示,需要说明的是,如图2所示的模型从模块层(blocklayer)到坍缩层(collapselayer),所有的数据流都是二维序列。为了说明清楚,以一个具体的例子进行详细说明。令i(h,w,d)为一个高h宽w的图片,图片中的每个点为d维矢量。一个100*32的二进制手写图片可以表达成i(100,32,1),一个rgb颜色图片可以表达成i(100,32,3)。如图2所示,第一个模块层通过将每一个1*4(高*宽)的模块将i(h,w,1)转化为i(h,w/4,4)。从四个方向扫描i(h,w/4,4),然后将它们连接到到四个单独的lstm隐藏层,每一个隐藏的单元里有4个元胞,在第一个lstm隐藏层,把得到的四个新的i(h,w/4,4)图片进行转化。为了获得高水准特征,再分别通过2*4模块层,把在i(h,w/4,4)上的8个像素合并为一个像素,因此可以得到4个i(h/2,w/16,32)图片。第一个子采样层(subsamplelayer)仅是一个有16个神经元的feedforwardtanh层。所有的i(h/2,w/16,32)都被一起连接到子采样层,并转移到单一的i(h/2,w/16,16)图片。这些层的目的是大大减少权重。上面的结构可以被堆栈到层次结构中。第二个lstm隐藏层有20个元胞,第三个有100个元胞。坍缩层通过加和水平轴向的图片把四个i(h/4,w/32,100)图片转换为一个i(h/4,1,100)。最后,ctc层收到从坍缩层来的激励,并计算每一个字素的分布概率。ctc层的尺寸等于字素(表1中的50个字素)和两个额外空白和空间(表1未显示的两字素间的分类差距)的标签数之和,即52。还需要说明的是,在识别模型训练的过程中,还进行了参数的最优选择的过程,通过实验确定了mdlstm-ctc模型的最优参数。如表2、表3和表4所示。实验中仅从主数据库中选取了1200张图片集,其中1000张图片作为训练集,200张图片作为有效性集合。在最好路径解码下的有效集字符错误率(cer)被选为评估标准。需要优化的参数有区域尺寸,lstm隐藏区尺寸以及子采样层尺寸。在所有实验中,通过实验固定学习率为2e-4。最开始,我们固定隐藏层尺寸为2,10,50,子采样层为10,20。表2中指明,mdlstm区域层尺寸为1*4,2*2,2*2和1*4,2*4,2*2的结果最好,因此选择一个更大的区域1*4,2*4,2*2作为最优参数。表3指明,不同尺寸隐藏区在有效检验中表现几乎一样,因此选择在训练集中结果最好的4,20,100作为参数。表4指明,子采样层的尺寸为16*40的结果最好,因此选择子采样层的尺寸为16*40作为最优参数。表2blocksizetrainsetcer(%)validationsetcer(%)1x42x22x213.7540.951x42x42x221.4041.541x42x42x442.1152.812x22x22x228.9751.132x42x21x233.4345.811x42x42x221.4041.54表3hiddensizetrainsetcer(%)validationsetcer(%)2,10,5021.4041.544,20,10020.8241.678,30,15022.1341.15表4sub-samplesizetrainsetcer(%)validationsetcer(%)8,2029.2142.5716,4020.6939.3332,8033.0941.08在本发明的一个实施例中,图1所示的步骤s140中的根据概率,确定待识别的手写图片中的蒙古语语句包括:根据概率,采用基于连续时间分类令牌传递算法的多单词解码算法,确定待识别的手写图片中的蒙古语语句;其中,多单词解码算法基于有限态状态传感器表述各蒙古语单词的词库,并在各蒙古语单词的末尾处基于语言模型进行计算。上述的确定待识别的手写图片中的蒙古语语句的过程可以认为是一个解码的过程,解码过程主要是根据概率,结合n-gramswm和字典进行蒙古语语句的解码,以获得识别结果。具体地,上述的根据概率,采用基于连续时间分类令牌传递算法的多单词解码算法,确定待识别的手写图片中的蒙古语语句包括:建立蒙古语字典;其中,蒙古语字典中包括若干蒙古语单词,以及各蒙古单词对应的字素组成,这里的字典中的蒙古语单词可以自定义;根据概率,计算蒙古语字典中各蒙古语单词包含在待识别的手写图片中的概率;根据语言模型,依次确定待识别的手写图片中的蒙古语语句的各蒙古语单词。进一步地,上述的根据语言模型,依次确定待识别的手写图片中的蒙古语语句的各蒙古语单词包括:根据语言模型,获取蒙古语字典中各蒙古语单词作为句子首个单词的概率;计算各蒙古语单词包含在待识别的手写图片中的概率和对应的作为句子首个单词的概率的乘积,将乘积最大值对应的蒙古语单词确定为待识别的手写图片中的蒙古语语句的首个单词;根据语言模型,获取蒙古语字典中各蒙古语单词的上一个单词是确定出的首个单词的概率;计算各蒙古语单词包含在待识别的手写图片中的概率和对应的上一个单词是确定出的首个单词的概率的乘积,将乘积最大值对应的蒙古语单词确定为待识别的手写图片中的蒙古语语句的第二个单词;根据语言模型,获取蒙古语字典中各蒙古语单词的上两个单词是确定出的首个单词和第一个单词的概率;计算各蒙古语单词包含在待识别的手写图片中的概率和对应的上两个单词是确定出的首个单词和第一个单词的概率的乘积,将乘积最大值对应的蒙古语单词确定为待识别的手写图片中的蒙古语语句的第三个单词;以此类推,直到确定出待识别的手写图片中的蒙古语句中的所有单词。因为在进行待识别的手写图片的识别时,是无法确定图片中的蒙古语语句是否全部识别结束,所以在本实施例中,主要是根据待识别的手写图片在经过识别模型时,被分割的模块的个数来确定的,当所有的模块均识别一遍,则可结束解码过程,解码结束后去掉空白部分就是识别出来的蒙古语语句。为了对上述方法过程进行详细说明,下面通过一个具体的例子进行说明,该例子中以中文为例。图3示出了根据本发明一个实施例的一种待识别的手写图片的示意图。如图3所示,在该待识别的手写图片中需要识别的中文语句是“我曾听人说过”。解码过程就是从字典(有限字的集合,所有解码字必须来自字典,字典外的词肯定无法解码)找合适的字的序列。解码算法的ctc和ngram都是概率。ctc是用根据图片计算出来的每一帧对应的字素(字素是构成文字的基本单位,比如“听”可分解成“口”和“斤”两个字素组成,蒙古文的字素如表1所示)概率。ngram是语言模型概率,比如,p(人|听),就是“听”字后头出现“人”字的概率。图4示出了根据本发明一个实施例的待识别的手写图片的解码过程示意图。如图4所示,假设字典只有六个字“我、曾、听、人、说、过”,在解码时:走红色路径就是“我我我我我我”;走绿色路径就是“人听人曾听过”;走黑色路径就是“我曾听人说过”。理论上,字典中的6个字可以组成无限多的句子,但根据语法只有少数的语句才有意义。所以,对所有路径计算概率,概率最高的路径就是最有可能的目标输出。这里的路径概率来自两部分,就是根据识别模型计算出的字的概率,和字与字之间的概率(利用ngram计算)。上图黑色路径的概率计算过程:p(我曾听人说过)=p(我|输入图片)*p(我|句子开始)*p(曾|输入图片)*p(曾|我)*p(听|输入图片)*p(听|我曾)*p(人|输入图片)*p(人|我曾听)*p(说|输入图片)*p(说|我曾听人)*p(过|输入图片)*p(过|我曾听人说)。其中,p(我|输入图片)、p(曾|输入图片)、p(听|输入图片)、p(人|输入图片)、p(说|输入图片)、p(过|输入图片)用ctc计算获得;p(曾|我)、p(听|我曾)、p(人|我曾听)、p(说|我曾听人)、p(过|我曾听人说)就是ngram中提供的概率信息。从图4可知,路径有无限多,所以无法计算出所有路径的概率再选最大值。实际中采取的策略是每计算一步,选择概率最大的路径往下一步步的计算。第一步计算:(我|输入图片)*p(我|句子开始);(曾|输入图片)*p(曾|句子开始);(听|输入图片)*p(听|句子开始);(人|输入图片)*p(人|句子开始);(说|输入图片)*p(说|句子开始);(过|输入图片)*p(过|句子开始);选择最大的路径“我”(假设“我”的计算概率最大)。第二步计算:(我|输入图片)*p(我|我);(曾|输入图片)*p(曾|我);(听|输入图片)*p(听|我);(人|输入图片)*p(人|我);(说|输入图片)*p(说|我);(过|输入图片)*p(过|我);选择最大的路径“曾”(假设“我曾”的计算概率最大)。第三步计算:(我|输入图片)*p(我|我曾);(曾|输入图片)*p(曾|我曾);(听|输入图片)*p(听|我曾);(人|输入图片)*p(人|我曾);(说|输入图片)*p(说|我曾);(过|输入图片)*p(过|我曾);选择最大的路径“听”(假设“我曾听”的计算概率最大)。以此类推,直到计算出图片中的所有中文字。需要说明的是,为了便于理解,上述是以中文举例进行的说明,但本领域的技术人员可以理解该方法同样适用于蒙古语,且上述方法是在实施方案上的说明,所针对的适用语言更加广泛,应均在本发明所保护的范围内。下面将从算法上具体说明上述的解码识别过程。最简单的解码ctc网络的算法是最优路径解码,即在每一时间步骤选择单一最可能输出标签。其优点在于快速,不依赖词库。但是其在单词错误率上表现很糟,而精确的解码可以由词汇库或者语言模型来表达。(1)单个单词解码令d为固定单词表,n=|d|为d中的单词数量。在给定图像x中,单一词汇解码算法找到了最可能的单词w属于d。可由下式表述:令w为标签w=k1k2...ks的一个序列,s=|w|,是时刻t输出标签k的ctc概率,t是x的总帧数,概率p(w|x)=p(k1k2...ks|x)的计算方式如下:w′=blankk1blankk2…blankksblank(insertblankinw)l=|w′|=2s+1ift==0elsefort=2totfors=1tol但是,在计算中如果两个单词w1和w2有同样的前缀w*n=|w*|,概率qnt=p(w*|x,t)在w1和w2中有相同的值。因此,通过除去相同前缀的重复计算以节约计算时间。令w1=aazrazoax,w2=aazrazo,采用加权有限状态传感器(weightedfinite-statetransducer,fst)以代表d中的每一个单词,因为算法的搜索空间可由带权重的有限态状态传感器(fst)建模,可以减少蒙古语单词里相同词根的重复计算。fst转化的输入标签对应于字素,输出标签对应于单词和,权重对应于前缀概率w1和w2的fst如图5所示,其中#0为公用的开始标签,ε表示空。用fst表示d中的每一个单词,其中所有的单词共享一个开始状态和结束状态。然后,确定fst让带有任意输入标签的每一个状态最多有一个转移。w1和w2的确定fst示例如图6所示,可以得知w1和w2公用同样的状态0到状态6。对一个代表6733个单词的fst进行统计,在确定之前,状态数为52646,确定之后为27323。这对提高计算p(w|x)速度带来很大影响。在实际的算法中,下述的伪代码描述了基于fst固定单词表的单个单词搜索程序。在实际fst中,在每一个单词中会插入图5和图6没有显示的空白。单个单词的解码算法具体为:如果单词的边界信息是未知的,可以通过约束在某一语言模型的多单词解码算法来解码。因此,本发明提出了多单词解码算法,其主要基于ctc令牌传递算法。其中,词库由fst表述;在每个单词的末尾而非开头考虑语言模型的概率。传统的ctc令牌传递算法在最糟的情况计算复杂度为o(tw2),最好的情形下为o(twlogw),但本发明中的计算复杂度减小到了近o(tw/2),且不需要任何分类过程。下述打算发提供了多单词解码算法的伪代码。其中,与单个单词解码算法相同的定义不再重复。本发明中的主要思路是:在每一时间步骤选择前一步的一个最大值token,在每个单词的末尾,然后通过fst传递最大的token。当通过fst传递token时,计算和传统算法一样,但是在到达每个单词末尾,这个值会被n-gram概率plm(a.o|a.tok[t].path)倍乘。传统算法认为语言模型为每个单词选择不同的最大token值,但本发明中的算法在选择最大值时考虑了语言模型,为所有的单词选择同样的最大token值。传统算法非常难以采用3-gram或者更高的n-gram语言模型,但本发明中的算法很容易与之结合,因为本发明中考虑了lm对现有值的贡献,如果2-gram,其贡献为p(w|tok.path[i]);如果3-gram其贡献为p(w|tok.path[i],tok.path[i-1]),以此类推。在上述的多单词解码算法中,在每一时间步骤仅选择了一个最大的概率,可以进一步将其从1到k拓展,进行集束算法,具体如下:在一个具体的实验中,采用mhw数据集来评估不同级别子词的表现。基于双音节的子词swm在数据集一测试的最好表现是18.32%错词率(wer),在数据集二的测试中为23.22%,相比于开放词表基准系统分别减少了23.14%和19.16%。可见,采用集束搜索算法以及使用混合类型的子词元会提高算法对同一词库的识别表现。图7示出了根据本发明一个实施例的一种蒙古语手写识别装置的结构示意图。如图7所述,该蒙古语手写识别装置700包括:710字素表建立单元,用于建立蒙古语字素表;其中,蒙古语字素表中的字素与蒙古语字形对应,蒙古语单词由蒙古语字素表中的字素组成;720识别模型训练单元,用于训练基于蒙古语字素表的蒙古语手写识别模型;730字素概率获取单元,用于将待识别的手写图片输入蒙古语手写识别模型,获得蒙古语字素表中各字素包含在待识别的手写图片的各区域中的概率;740蒙古语语句确定单元,用于根据概率,确定待识别的手写图片中的蒙古语语句。在本发明的一个实施例中,识别模型训练单元720,用于建立二维时间递归神经网络-连续时间分类模型的拓扑结构;根据多个样本手写图片,使用拓扑结构训练基于蒙古语字素表的蒙古语手写识别模型。在本发明的一个实施例中,蒙古语语句确定单元740,用于根据概率,采用基于连续时间分类令牌传递算法的多单词解码算法,确定待识别的手写图片中的蒙古语语句;其中,多单词解码算法基于有限态状态传感器表述各蒙古语单词的词库,并在各蒙古语单词的末尾处基于语言模型进行计算。具体地,蒙古语语句确定单元740,用于建立蒙古语字典;其中,蒙古语字典中包括若干蒙古语单词,以及各蒙古单词对应的字素组成;根据概率,计算蒙古语字典中各蒙古语单词包含在待识别的手写图片中的概率;根据语言模型,依次确定待识别的手写图片中的蒙古语语句的各蒙古语单词。进一步地,蒙古语语句确定单元740具体用于,根据语言模型,获取蒙古语字典中各蒙古语单词作为句子首个单词的概率;计算各蒙古语单词包含在待识别的手写图片中的概率和对应的作为句子首个单词的概率的乘积,将乘积最大值对应的蒙古语单词确定为待识别的手写图片中的蒙古语语句的首个单词;根据语言模型,获取蒙古语字典中各蒙古语单词的上一个单词是确定出的首个单词的概率;计算各蒙古语单词包含在待识别的手写图片中的概率和对应的上一个单词是确定出的首个单词的概率的乘积,将乘积最大值对应的蒙古语单词确定为待识别的手写图片中的蒙古语语句的第二个单词;根据语言模型,获取蒙古语字典中各蒙古语单词的上两个单词是确定出的首个单词和第一个单词的概率;计算各蒙古语单词包含在待识别的手写图片中的概率和对应的上两个单词是确定出的首个单词和第一个单词的概率的乘积,将乘积最大值对应的蒙古语单词确定为待识别的手写图片中的蒙古语语句的第三个单词;以此类推,直到确定出待识别的手写图片中的蒙古语句中的所有单词。需要说明的是,图7所示的装置的各实施例与图1所示方法的各实施例对应相同,上文已有详细说明,在此不再赘述。综上所述,根据本发明的技术方案,首先建立蒙古语字素表;这里的蒙古语字素表中的字素与蒙古语字形对应,蒙古语单词由蒙古语字素表中的字素组成;训练基于蒙古语字素表的蒙古语手写识别模型;将待识别的手写图片输入蒙古语手写识别模型,获得蒙古语字素表中各字素包含在待识别的手写图片的各区域中的概率;根据概率,确定待识别的手写图片中的蒙古语语句。本发明是结合手写识别算法训练了基于字素的蒙古语识别模型,当利用该模型获得各字素的概率后,再确定待识别的手写图片中的蒙古语语句,有效的提高了蒙古语的手写识别率,降低识别的错词率,解决了高oov率的问题。需要说明的是:在此提供的算法和显示不与任何特定计算机、虚拟装置或者其它设备固有相关。各种通用装置也可以与基于在此的示教一起使用。根据上面的描述,构造这类装置所要求的结构是显而易见的。此外,本发明也不针对任何特定编程语言。应当明白,可以利用各种编程语言实现在此描述的本发明的内容,并且上面对特定语言所做的描述是为了披露本发明的最佳实施方式。在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。类似地,应当理解,为了精简本公开并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本发明要求比在各权利要求中所明确记载的特征更多的特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中各权利要求本身都作为本发明的单独实施例。本领域那些技术人员可以理解,可以对实施例中的设备中的模块进行自适应性地改变并且把它们设置在与该实施例不同的一个或多个设备中。可以把实施例中的模块或单元或组件组合成一个模块或单元或组件,以及此外可以把它们分成多个子模块或子单元或子组件。除了这样的特征和/或过程或者单元中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何方法或者设备的所有过程或单元进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的各特征可以由提供相同、等同或相似目的的替代特征来代替。此外,本领域的技术人员能够理解,尽管在此所述的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本发明的范围之内并且形成不同的实施例。例如,在下面的权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。本发明的各个部件实施例可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。本领域的技术人员应当理解,可以在实践中使用微处理器或者数字信号处理器(dsp)来实现根据本发明实施例的蒙古语手写识别装置中的一些或者全部部件的一些或者全部功能。本发明还可以实现为用于执行这里所描述的方法的一部分或者全部的设备或者装置程序(例如,计算机程序和计算机程序产品)。这样的实现本发明的程序可以存储在计算机可读介质上,或者可以具有一个或者多个信号的形式。这样的信号可以从因特网网站上下载得到,或者在载体信号上提供,或者以任何其他形式提供。应该注意的是上述实施例对本发明进行说明而不是对本发明进行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权利要求中的元件或步骤。位于元件之前的单词“一”或“一个”不排除存在多个这样的元件。本发明可以借助于包括有若干不同元件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1