一种基于RDMA的分布式内存数据库查询引擎系统的制作方法
本发明涉及分布式内存数据库研究领域,具体地,涉及一种基于rdma的分布式内存数据库查询引擎系统。
背景技术:
在当前的数据库市场,传统数据库已经渐渐退出历史舞台,nosql和newsql增长势头十分强劲。newsql是对所有新型可扩展、高性能数据库的简称,它们不仅有nosql对海量数据库的存储管理能力,还保持了传统数据库支持acid和sql等特性。但是磁盘读写速度较慢,极大地阻碍了newsql数据库的执行速度,因此诞生了面向联机分析处理(olap,onlineanalyticalprocessing)的大规模分布式内存数据库。分布式内存查询引擎是newsql的核心部分,负责整个查询任务的sql解析和查询任务执行。
spark-sql是一种数据仓库查询引擎,负责接受用户的sql语句,在hdfs上进行数据处理,spark-sql底层采用spark计算模型而不是mapreduce计算模型。spark-sql采用了基于内存的列簇存储方案;“部分dag执行引擎”,对sql语句进行了基于代价的查询优化;同时支持语言级别的数据共同分片等方式对传统的hive进行优化。
impala是cloudera开源的大数据查询引擎,采用mpp架构,通过进程间通信的方式,能够极大地提高系统的执行效率。impala在生成查询计划的时候,遵循两个基本目标:最大程度地进行并行化;最大化数据局部性,尽可能减少网络传输。
spark-sql和impala提供了很好的查询性能,但是它们多个查询引擎进程之间都采用基于tcp/ip的socket进行通信,由于tcp网络的复杂性和高延迟,大数据查询引擎的数据量又十分庞大,查询任务的主要瓶颈都在网络传输上。
综上所述,本申请发明人在实现本申请发明技术方案的过程中,发现上述技术至少存在如下技术问题:
在现有技术中,现有的大规模分布式内存数据库查询引擎存在任务执行过程中海量数据传输速度慢的技术问题。
技术实现要素:
本发明提供了一种基于rdma(远程直接数据存取)的分布式内存数据库查询引擎系统,解决了现有的大规模分布式内存数据库查询引擎存在任务执行过程中海量数据传输速度慢的技术问题,实现了如何降低了分布式内存数据库查询引擎的数据传输开销,提高了查询速度的技术效果。
为解决上述技术问题,本申请提供了一种基于rdma的分布式内存数据库查询引擎系统,所述系统包括:
多个查询引擎模块、任务调度模块、元数据信息收集模块、任务执行模块;其中,查询引擎模块包括主查询引擎模块和从查询引擎模块;元数据信息收集模块从分布式内存数据库存储引擎收集数据分布情况,为每张表的每个列生成统计信息;主查询引擎模块基于关系代数的变换将sql语句解析为逻辑计划,将逻辑计划发送给任务调度模块;任务调度模块根据执行引擎数据分布情况和rdma的数据传输特性,生成物理计划将物理计划发送给查询引擎模块;主查询引擎模块根据物理计划生成至少两个子任务,并将子任务下发到多个从查询引擎模块;从查询引擎模块将子任务加入任务队列,当前任务完成后,通过rdma的方式,将数据发送给后继子任务,所有子任务完成后,通知客户端在从查询引擎系统获取结果数据。
本发明采用基于infiniband(无限带宽技术)的rdma网络,进行子任务执行过程中的数据交换。而不会出现impala和spark-sql任务执行过程中,后继任务长时间等待前驱任务,导致cpu利用率很低。同时,基于infiniband的rdma网络双向传输速度互补影响的特性,本发明提出一种基于rdma网络的dag(有向无环图)任务调度策略,充分利用rdma特性。因此,采用本发明提供的基于rdma的分布式内存数据库的查询方法,可以得到良好的查询效率。其中,rdma技术全称远程直接数据存取。
进一步的,所述系统的处理流程为:
步骤1:元数据收集模块从分布式内存数据库存储引擎收集数据分布情况,为每张表的每个列生成统计信息,即数据分布图;
步骤2:客户端将sql语句发送给查询引擎模块,根据负载均衡策略指定一个主查询引擎模块;
步骤3:主查询引擎模块将sql语句解析为执行计划,并将执行计划发送给任务调度模块;
步骤4:任务调度模块基于数据分布图,将所查询的列的数据平均地分为n份,总份数n等于所有从查询引擎模块的所有机器总核数,将执行计划中的每个子任务分为n个,生成新的任务执行dag图,在新的任务执行dag图中,前置子任务将数据发送给多个后继子任务;
步骤5:为每个子任务指定物理机ip后,将任务发送部署到物理机。
进一步的,负载均衡策略为所有的sql引擎模块都有一个任务队列,选择任务队列中任务最少的那一个。
进一步的,所述步骤4具体包括:
步骤4-1:任务调度模块基于数据分布图,将所查询的列的数据平均地分为n份,总份数n等于所有从查询引擎模块的所有机器总核数,将执行计划中的每个子任务分为n个,前驱和后继子任务通过预设的数据传输规则,将分裂后的子任务关联起来,生成新的任务执行dag图;
步骤4-2:在新的任务执行dag图中,round-robin(轮询)调度策略前置子任务将数据发送给多个后继子任务,使后继所有子任务处于一台物理机。
进一步的,所述步骤5具体包括:
步骤5.1:任务执行完毕后,如果没有后继子任务,通知客户端获取sql语句查询结果,否则通过rdma网络,将数据发送给后继子任务;
步骤5.2:对rdma网络接口进行封装,提供前后任务基于hash分布和range分布的消息队列语义;
步骤5.3:后继子任务接受到前驱任务的消息后,判定自身是否可以执行,判定规则为是否接受前驱任务所有数据,任务执行完毕后,重复步骤5.1。
进一步的,提供前后任务基于hash分布和range分布的消息队列语义通过以下两个步骤实现:首先基于rdma网络提供上层的同步非阻塞网络编程框架,然后在框架上层提供消息队列语义。
本申请提供的一个或多个技术方案,至少具有如下技术效果或优点:
本发明提供了一种基于rdma的分布式内存数据库查询引擎,解决了现存分布式内存数据库系统中网络交换速度慢的瓶颈。本发明提出基于round-robin调度策略,解决了rdma高速网络交换机中hol(排头阻塞)阻塞问题;同时提出了一套基于rdma的消息队列模型,分布式数据库引擎不必关心网络传输问题,只需要为rdma消息队列指定网络传输方式。进一步的,各个子任务相互独立,满足了分布式内存数据库查询引擎横向扩展的需求。
附图说明
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定;
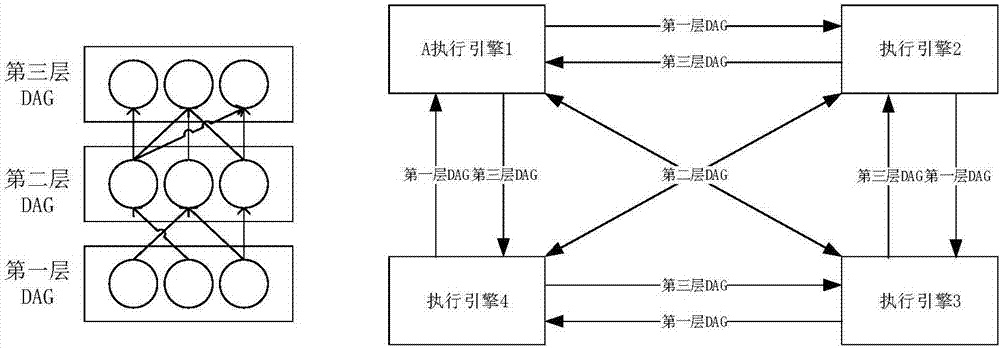
图1是本申请中基于rdma的分布式内存数据库查询引擎架构图;
图2是本申请中步骤4-2任务调度策略示意图;
图3是本申请中基于rdma的分布式内存数据库查询引擎执行流程图。
具体实施方式
本发明提供了一种基于rdma的分布式内存数据库查询引擎系统,解决了现有的大规模分布式内存数据库查询引擎存在任务执行过程中海量数据传输速度慢的技术问题,实现了如何降低了分布式内存数据库查询引擎的数据传输开销,提高了查询速度的技术效果。
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在相互不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述范围内的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
本发明所要解决的是采用rdma的方式,解决大规模分布式内存数据库查询引擎任务执行过程中海量数据传输速度慢的问题。
请参考图1-图3,本方案通过下述技术方案实现:
一种基于rdma的分布式内存数据库查询引擎系统,包括多个查询引擎模块,任务调度模块,元数据信息收集模块和任务执行模块。元数据信息收集模块分布式内存数据库存储引擎收集数据分布情况,为每张表的每个列生成统计信息;在查询引擎到来时,主查询引擎模块基于关系代数的变换将sql语句解析为本领域研究人员知道的逻辑计划;将逻辑计划发送给任务调度模块,任务调度模块根据执行引擎数据分布情况和rdma的数据传输特性,生成本领域研究人员知道的物理计划;将物理计划发送给查询引擎模块,主查询引擎模块根据物理计划生成至少两个子任务,下发到多个从查询引擎模块;从查询引擎模块将子任务加入任务队列;当前任务完成后,通过rdma的方式,将数据发送给后继子任务;所有子任务完成后,通知客户端在从查询引擎获取结果数据。
本发明采用基于infiniband的rdma网络,进行子任务执行过程中的数据交换。而不会出现impala和spark-sql任务执行过程中,后继任务长时间等待前驱任务,导致cpu利用率很低。同时,基于infiniband的rdma网络双向传输速度互补影响的特性,本发明提出一种基于rdma网络的dag任务调度策略,充分利用rdma特性。因此,采用本发明提供的基于rdma的分布式内存数据库的查询方法,可以得到良好的查询效率。
基于rdma的分布式内存数据库查询引擎有如下步骤:
步骤1:元数据收集模块从分布式内存数据库存储引擎收集数据分布情况,为每张表的每个列生成统计信息,称为数据分布图;
步骤2:客户端将sql语句发送给查询引擎模块,由于有多个查询引擎模块,可以根据负载均衡策略指定一个主查询引擎模块,负载均衡策略为所有的sql引擎模块都有一个任务队列,选择任务队列中任务最少的那一个;
步骤3:主查询引擎模块将sql语句解析为执行计划,并将执行计划发送给任务调度模块。
步骤4-1:任务调度模块根据步骤一提到数据分布图,将所查询的列的数据平均地分为n份,总份数n等于所有从查询引擎的所有机器的总核数。将执行计划中的每个子任务分为n个,前驱和后继子任务通过预设的数据传输规则,将分裂后的子任务关联起来,产生新的任务执行dag图。
步骤4-2:在新的任务执行dag图中,某个前置子任务会把数据发送给多个后继子任务。如果随机分布任务到多台机器,由于rdma转发速度很快,数据会在交换机产生head-of-line(hol)阻塞,降低数据转发速度。这里我们采用简单而有效的round-robin调度策略,使后继所有子任务处于一台物理机,这样前置任务只会向一台物理机发送数据,避免了hol阻塞。
步骤5:为每个子任务指定物理机ip后,将任务发送部署到这些物理机。
步骤5.1:任务执行完毕后,如果没有后继子任务,通知客户端获取sql语句查询结果,否则通过rdma高速网络,将数据发送给后继子任务。
步骤5.2:rdma只提供了访问远程内存的基本语义,为了满足分布式内存数据库查询引擎在数据传输的需求,对rdma网络接口进行封装,提供前后任务基于hash分布和range分布的高级消息队列语义。主要通过两个步骤实现,首先基于rdma网络提供上层的同步非阻塞网络编程框架,然后在框架上层提供消息队列语义。
步骤5.3:后继子任务接受到前驱任务的消息后,会判定自身是否可以执行,判定规则为是否接受前驱任务所有数据。任务执行完毕后,重复步骤5.1。
本发明与现有技术相比,具有如下的优点和效果:
一种基于rdma的分布式内存数据库查询引擎,主要特征包括:基于rdma高速网络服务于分布式内存数据库查询引擎的消息队列,基于rdma告诉网络的分布式任务调度策略。
基于rdma高速网络服务于分布式内存数据库查询引擎的消息队列,首先基于rdma网络提供上层的同步非阻塞网络编程框架;然后在框架上层提供分布式消息分发语义。
基于rdma告诉网络的分布式任务调度策略,主要采用round-robin调度策略,使后继所有子任务处于一台物理机,这样前置任务只会向一台物理机发送数据,避免了hol阻塞。
本发明提供了一种基于rdma的分布式内存数据库查询引擎,解决了现存分布式内存数据库系统中网络交换速度慢的瓶颈。本发明提出基于round-robin调度策略,解决了rdma高速网络交换机中head-of-line(hol)阻塞问题;同时提出了一套基于rdma的消息队列模型,分布式数据库引擎不必关心网络传输问题,只需要为rdma消息队列指定网络传输方式。进一步的,各个子任务相互独立,满足了分布式内存数据库查询引擎横向扩展的需求。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!