模块化成果库的构建方法与流程
本发明属于数据挖掘技术领域,尤其是一种模块化成果库的构建方法。
背景技术:
在现实世界中,知识不仅以传统数据库中的结构化数据的形式出现,还以诸如书籍、研究论文、新闻文章、web页面及电子邮件等各种各样的形式出现。面对以这些形式出现的、浩如烟海的信息源,人类的阅读能力、时间精力等等往往不够,需要借助计算机的智能处理技术来帮助人类及时、方便的获取这些数据源中隐藏的有用信息。因此,文本挖掘技术就在这种背景下产生和发展起来的。
文本挖掘的根本价值在于能把从文本中抽取出的特征词进行量化来表示文本信息。将它们从一个无结构的原始文本转化为结构化的计算机可以识别处理的信息,即对文本进行科学的抽象,建立它的数学模型,用以描述和代替文本,使计算机能够通过对这种模型的计算和操作来实现对文本的识别。
现有技术的存在以下问题:(1)传统的篇章结构拆分,只能识别标题,无法形成层级关系;或根据目录生成受限的层级关系;(2)传统的编辑距离,没有考虑语义关系,可能造成编辑距离很小(相似度很高),但描述的是不同事物或表达不同的情感倾向。
技术实现要素:
本发明的目地在于克服现有技术的不足,提出一种设计合理、准确可靠且灵活便捷的模块化成果库的构建方法。
本发明解决其技术问题是采取以下技术方案实现的:
一种模块化成果库的构建方法,包括以下步骤:
步骤1、采用基于信息抽取方法进行科研报告篇章结构拆解;
步骤2、对于同一领域的科研报告,利用标题及关键词相似度进行自上而下的整合,最终形成领域图谱。
所述步骤1包括:将word文档的报告转换为html格式,提取其中的指定标签内容;根据动态规则模板对报告标题进行识别,篇章层级关系以标题所满足的规则模板之间相互关系为依据进行判别。
所述根据动态规则模板对报告标题进行识别的具体方法包括以下步骤:
⑴对整篇报告设立一个根节点,其余所有篇章标题均作为其子节点;
⑵循环遍历每段内容与动态规则模板进行匹配,若满足动态规则模板中的条件,认为是标题;不满足条件,认为是正文内容;
⑶正文内容对应的标题根据就近原则进行匹配;
⑷判断当前标题的规则与上一个标题的规则是否一致,若一致,认为两者是兄弟节点;若不一致,延续上一个标题递归寻找其父节点,判断标题所满足的规则是否一致,直至判断到根节点,若均无规则与之相同,则认为当前标题是上一个标题的子节点;
⑸最后对识别得到的模块化知识点建立倒排索引。
所述步骤2的实现方法为包括如下步骤:
⑴加载特定领域的领域图谱模板文件,其内容为最终领域图谱的枝干标题;
⑵加载属于同一领域的待合并文档的模块化数据;
⑶根据编辑距离计算模板文件与模块化数据之间的标题相似度,建立知识图谱;
⑷重复步骤⑶,直至所有模块化数据遍历完成。
所述步骤⑶包括以下步骤:
①将领域图谱模板文件中的标题进行分词处理;
②将模块化数据的标题进行分词处理;
③对模块化数据的标题分词结果,进行同义词替换,并用替换结果与模板文件的标题分词结果依次进行编辑距离计算,得到相似度最大的匹配结果;
④若相似度大于设定的阈值,则将模块化数据以及其关联的后续模块化数据一同合并到匹配中的模板文件中。
本发明的优点和积极效果是:
1、本发明针对科研报告的模块化过程,构建一个基于信息抽取技术的科研报告篇章结构拆解方法以及基于文本相似度分析的领域图谱构建方法,对模块化成果的元数据建立倒排索引,解决了业务人员快速形成科研报告,减少科研中的重复性工作,提高工作效率,实现科研资源价值显性化的需求。
2、本发明引入信息抽取技术对报告标题进行识别,并根据标题所满足规则的相互关系判断层次结构,突破了根据目录结构对篇章结构识别上的限制,也使得模块化拆分更加灵活。
3、本发明引入了基于分词的编辑距离,来计算两段文字的相似度;并且加入同义词词典,避免由于不同作者用词习惯的区别而造成的相似度计算上的误差,使得领域图谱合并效果更优。
3、本发明利用信息抽取、文本挖掘、知识图谱、倒排索引等技术,构建模块化成果库工作平台;开展模块化成果分析与挖掘,绘制报告脑图、领域知识图谱,实现科研成果的可视化;支持模块化成果的检索、整合、在线组织功能,更好服务于科研工作,为业务人员直接引用有价值的模块化成果撰写报告提供便利,促进科研成果的共享与传播。
附图说明
图1为本发明的知识拆解流程图;
图2为本发明的篇章结构识别流程图;
图3为本发明的域图谱合并流程图;
图4为本发明的基于分词的编辑距离流程图。
具体实施方式
以下结合附图对本发明实施例做进一步详述。
一种模块化成果库的构建方法,包括以下步骤:
步骤1、采用基于信息抽取方法进行科研报告篇章结构拆解。
本步骤是针对科研报告的模块化过程,构建一个基于信息抽取技术的科研报告篇章结构拆解方法。包括两部分内容:(1)word文档首先转换为html格式,提取其中的指定标签内容;(2)根据动态规则模板对报告标题进行识别,具体篇章层级关系以标题所满足的规则模板之间相互关系为依据进行判别。
如图1所示,本步骤包括加载动态规则模板、上传报告、图片读取与保存、word文档转html、html解析表格、基于ie的知识点识别、动态规则对特点知识点识别、特征抽取识别根节点标题、节点结果封装(包括关键字、主题词抽取、段落类型识别等)、建立模块知识点索引。具体实现方法如下:
加载信息抽取技术,用于识别标题;
上传报告,并转换为html格式文档;
识别html文档css样式头信息,用于在html转word时保持样式的一致性;
提取html中图片内容,对于jpeg、png、bmp格式图片直接存储;emf、wmf格式图片进行jpeg格式转换后存储;
提取html中表格信息;
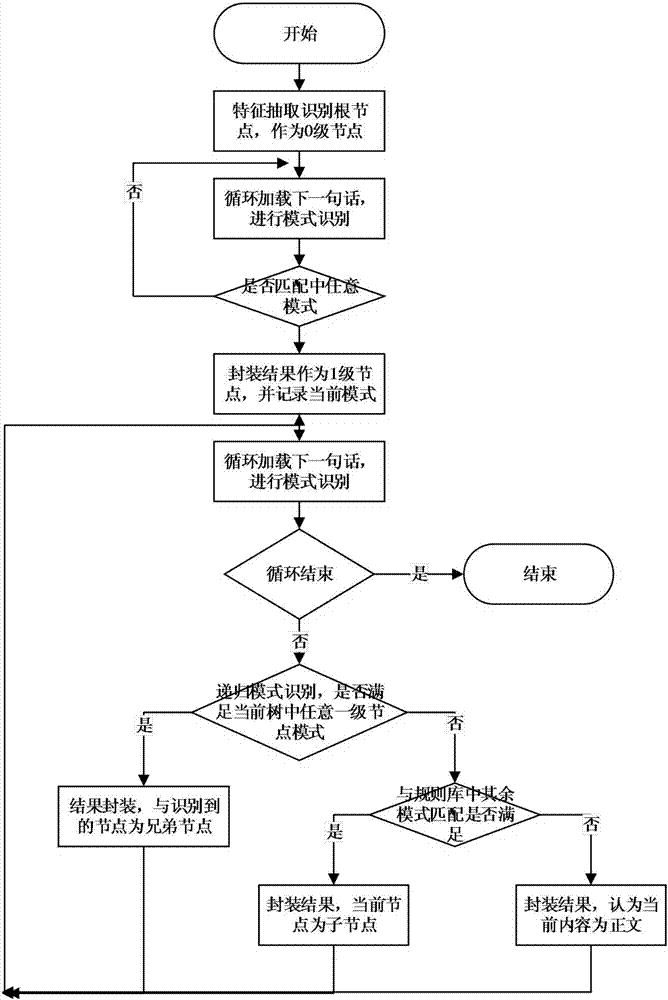
如图2所示,在进行标题识别及篇章结构整理过程中,动态规则对<span>标签下内容进行标题识别及篇章结构整理,识别模块化知识点,具体实现方法如下:
新建根节点root,以文档编号作为其标题;
循环遍历寻找span标签下的内容,进行标题模式识别,直至匹配中一次,作为1级节点,记为node,并记录匹配中的规则;
继续遍历寻找span标签下的内容,进行标题模式识别。若匹配中标题规则,则与node的匹配规则进行比较,若相同,则两者为兄弟节点,若不相同,取node的父节点,继续进行规则匹配。若找到与之匹配的节点,两者为兄弟节点,若没有匹配的节点,则认为是正文,根据就近原则将正文归到对应的node中。
重复上述两个步骤,直至整篇文档遍历完成,可识别到所有的模块化知识点以及报告的篇章结构。
最后对识别得到的模块化知识点建立倒排索引。
步骤2、领域图谱合并操作步骤。
本步骤是对于同一领域的科研报告,利用标题及关键词相似度进行自上而下的整合,最终形成领域图谱,具体实现方法如图3所示,包括以下步骤:
(1)加载特定领域的领域图谱模板文件,其内容为最终领域图谱的枝干标题;
(2)加载属于同一领域的待合并文档的模块化数据,即特定领域下所有模块化知识点内容;
(3)根据编辑距离计算模板文件与模块化数据之间的标题相似度,建立知识图谱。
本步骤是利用基于分词的编辑距离,计算模块化知识点的标题与领域图谱模板文件中标题的相似度,记录相似度最大的匹配结果。其方法是循环遍历所有模块化知识点内容,计算与模板文件标题的相似度,当相似度大于设定阈值时,则将模块化知识及其后续节点(子节点)一同合并到领域图谱模板中,最终形成领域的知识图谱,该知识图谱可以反映出特定领域的发展历史及发展趋势等。具体方法,如图4所示,包括以下步骤:
①将模板文件中的标题进行分词处理;
②将模块化数据的标题进行分词处理;
③对模块化数据的标题分词结果,进行同义词替换,并用替换结果与模板文件的标题分词结果依次进行编辑距离计算,得到相似度最大的匹配结果;
④若相似度大于设定的阈值,则可将模块化数据以及其关联的后续模块化数据(子节点)一同合并到匹配中的模板文件中。
(4)重复步骤(3),直至所有模块化数据遍历完成。
需要强调的是,本发明所述的实施例是说明性的,而不是限定性的,因此本发明包括并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!