一种基于深度用户画像进行精准营销的系统及实现方法与流程
本发明涉及通信数据处理技术领域,尤其涉及一种基于深度用户画像进行精准营销的系统及实现方法。
背景技术:
目前企业的用户画像,是以简单的数据统计和简单的算法模型作为支持,基于hadoop平台或者其他大数据平台进行离线和部分实时数据处理,以满足报表的多样化功能要求,同时企业管理人员可以根据该用户画像的结果进行企业决策指导。但是在用户画像标签结果层面上并没有进行深度的数据挖掘,对用户画像产生的标签数据没有更深入的利用,使得用户画像没有发挥出更多的功能。在企业精准营销方面,主要采用模型算法,基于协同过滤的基本算法进行商品或者物品的推荐,由于缺少用户的行为数据,难以做到个性化精准营销和同一用户的场景营销。
传统用户画像方法基于原始数据的统计和挖掘,没有将用户产生的标签数据结合其他数据进行更好的利用,没有做到深度的用户信息挖掘。企业缺少系统架构技术和用户的其他行业行为数据,在用户精准营销中由于冷启动问题而难以做到精准营销,同时也难以做到用户场景营销,从而难以抓住用户真实的痛点,缺少用户粘性。
技术实现要素:
针对背景技术中的问题,本发明的目的在于提供一种基于深度用户画像进行精准营销的系统及实现方法,解决传统用户画像对标签数据挖掘不充分的问题,以及基于深度的用户画像解决传统推荐系统中的冷启动问题,帮助企业对用户进行精准营销,从而提高用户的体验度和增加用户粘度。
为了实现上述目的,本发明的技术方案如下:
一种基于深度用户画像进行精准营销的系统,所述系统包括:数据源层、数据处理层、数据平台层、数据响应层和数据展示层;所述数据源层用于储存各种数据源;所述数据处理层用于将数据源中的数据进行汇总处理后再将来源不同的数据进行拉通;
所述数据平台层用于将数据处理层运行出来的数据进行数据处理形成用户初步的标签数据;
所述数据响应层用于将数据平台层运行出来的各种标签数据存储在分布式数据库中;
所述数据展示层用于深层用户画像展示以及用户的精准营销展示,包括个性化推荐模块和场景营销模块。
进一步地,所述数据源包括用户数据源、普林数据源和爬虫数据源;
所述用户数据源的存储介质是mysql数据库、oracle数据库;
所述普林数据源的存储介质为hbase数据库;
所述爬虫数据源的存储介质为hbase数据库。
进一步地,所述数据处理层包括etl处理模块和数据拉通模块;
所述etl处理模块用于对数据源中的用户数据进行汇总处理;所述数据拉通模块用于将来源不同的数据进行拉通。
进一步地,所述数据拉通的主要方式为用户强拉通和用户模糊拉通。
进一步地,所述数据平台层包括大数据计算处理平台spark、列式存储数据库hbase、文档存储数据库mongodb、结构化存储数据库mysql;
所述大数据计算处理平台spark用于数据计算和机器学习方面的建模;所述列式存储数据库hbase和文档存储数据库mongodb用于存储用户画像标签数据;所述mysql模块用于存储元数据。
进一步地,所述标签数据包括数据计算出来的统计类标签数据、建模算法得出的模型类标签数据、单客户标签数据和标签体系用户群数据。
所述统计类标签包括地域信息、人口基本属性信息;所述模型类标签包括用户行为偏好、用户消费价值度、用户消费习惯预测。
进一步地,所述统计类标签数据作为基础数据再次统计;所述模型类标签数据作为基础数据再次建模。
进一步地,保存标签的数据库为mysql或者hbase。
进一步地,所述个性化推荐模块根据用户在本网络或者其他网络中的历史数据进行数据分析,推荐用户可能喜欢或者感兴趣的内容;
所述历史数据包括用户的消费习惯数据、浏览网页数据、购物数据、app使用习惯数据、用户画像结果数据。
进一步地,所述场景营销模块,根据用户的个性化推荐结果,同时结合当前用户的场景位置,推荐用户当前所需要的信息,所述信息包括但不仅限于:美食、路况、住宿、娱乐。
上述的一种基于深度用户画像进行精准营销的系统的实现方法,所述方法包括如下步骤:
(1)获取数据源,包括用户数据源、普林数据源和爬虫数据源;
(2)使用etl工具或者自己开发代码进行客户数据的清洗、转换和加载;加载好数据后,结合普林数据、爬虫数据进行不同行业之间的数据拉通,实现多方位的用户实体识别,最后将处理完毕的数据导入到hdfs中;
(3)使用spark平台,加载分布式文件系统hdfs中的数据进行数据处理,将spark平台运行出来的标签数据进行保存在数据库中;
(4)个性化推荐:给每个用户推荐自己有可能需要的产品,根据用户的消费习惯数据、浏览网页数据、购物数据、app使用习惯、用户画像结果、购物历史数据等进行数据分析,推荐用户可能喜欢或者感兴趣的内容,进行个性化推荐;
(5)场景营销:锁定一个用户,根据步骤(4)中用户的个性化推荐结果,同时结合用户的位置信息,给用户推荐周边用户可能感兴趣的内容,同时记录分析用户的位置信息,结合用户历史行为,预测用户最新需求,进行精准化营销。
本发明相对于现有技术的有益效果在于:
(1)深度用户画像数据挖掘,将用户画像的标签数据作为基础数据,进行多次循环利用,即统计类标签数据作为基础数据再次统计,模型类标签数据作为基础数据再次建模,从而更深度地挖掘数据信息。
(2)个性化推荐,全方位地提供用户个性化产品推荐。整合不同的数据源,进行数据的统一处理,通过不同行业之间的数据拉通,进行多方位的用户实体识别,解决传统推荐行业中的冷启动问题。
(3)场景营销,打破传统基于用户历史的行为分析推荐营销,全方位结合用户的位置信息、兴趣偏好等,预测当前6小时、12小时、24小时的需求,结合不同的用户场景进行场景营销。
(4)基于spark开源平台,能够快速的处理tb级以上的数据。基于用户的历史数据和行为数据、深度的用户画像数据,可以支持用户的个性化推荐以及用户的场景化营销。
附图说明
图1是基于深度用户画像进行精准营销的系统架构技术架构图。
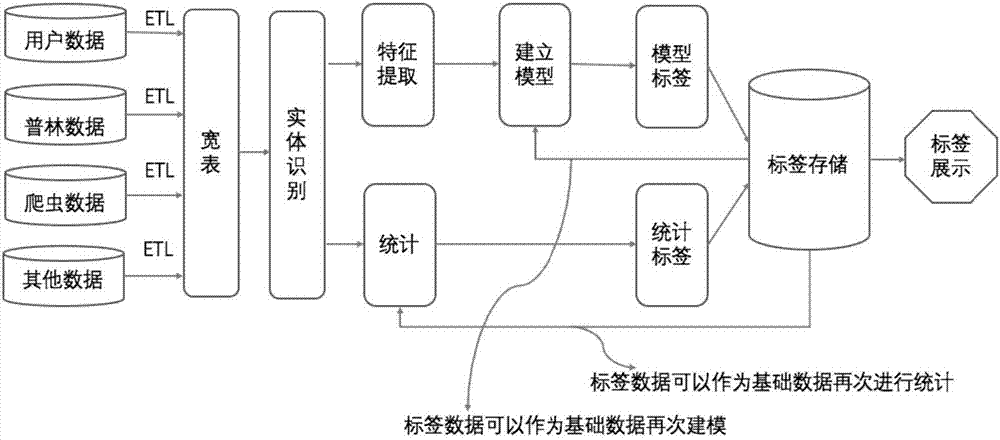
图2基于深度用户画像进行精准营销的系统架构数据流程图。
具体实施方式
下面结合附图和具体实施方式,对本发明的具体实施方案作详细的阐述。这些具体实施方式仅供叙述而并非用来限定本发明的范围或实施原则,本发明的保护范围仍以权利要求为准,包括在此基础上所作出的显而易见的变化或变动等。
本发明是基于spark开源平台,设计深度用户画像系统的框架,从而进行用户的精准营销。如图1所示,系统总体架构由5大层组成:
1.数据源层,该数据源层包括用户数据源、普林数据源、爬虫数据源和其他数据源。
客户数据源,存储介质是mysql、oracle。普林数据源,存储介质hbase数据库。爬虫数据,存储介质hbase数据库。
用户数据,指第三方用户数据,为满足用户实现用户画像系统需求而提供的数据。
普林数据,指公司的内部数据、电信运营商的部分数据以及同其他公司的合作购买的数据等。
爬虫数据,指为了满足用户需求,公司利用爬虫在互联网上爬取的相关数据。
2.数据处理层,将数据源进行汇总处理,经过etl处理后,再将来源不同的数据进行拉通,主要方式为用户强拉通和用户模糊拉通,最大限度的从虚拟世界中寻找真实的用户行为,将不同层面的用户数据进行识别。
使用etl工具或者自己开发代码进行客户数据的清洗、转换和加载。加载好数据后,结合普林数据、爬虫数据进行不同行业之间的数据拉通,实现多方位的用户实体识别,最后将处理完毕的数据导入到hdfs中。
3.数据平台层,数据平台层包括大数据计算处理平台spark、列式存储数据库hbase和文档存储数据库mongodb、结构化存储数据库mysql。
大数据计算处理平台spark作为计算平台提供计算服务,进行数据计算和机器学习方面的建模。列式存储数据库hbase和文档存储数据库mongodb进行标签数据的存储,其中,列式存储数据库hbase存储非结构化数据,文档存储数据库mongodb存储文档数据同时可以提供缓存服务。结构化存储数据库mysql进行元数据的存储,主要存储结构化数据,包括标签名称、标签等级、标签统计值等信息。
其中,spark平台中包括4个模块,分别为:streaming:实时处理模块;sparksql:spark访问hdfs数据的一种工具;普林算法库:公司沉淀的自己的数据挖掘和机器学习算法库;mllib:开源的机器学习算法库。4个模块共同组成用户画像系统基本的计算平台。
数据平台层使用spark平台,加载hdfs中的数据进行数据处理,包括使用统计技术和算法技术,形成用户初步的标签数据,保存在mysql数据库中,同时,该数据也可以作为其他标签数据的输入,进行深度层次的数据计算和挖掘。
4.数据响应层,数据响应层是指数据经过数据平台层处理后,将生成的各种标签存储在分布式数据库中。
该层将spark平台运行出来的标签数据进行保存,保存的数据库有mysql和hbase。
该层包括数据计算出来的标签结果数据、建模算法出的标签数据、单客户标签存储和标签体系用户群数据存储等。
其中,统计类标签包括地域信息、人口基本属性信息等。模型类标签包括用户行为偏好,用户消费价值度,用户消费习惯预测等。单客户标签是指在整个的标签体系中,给某个指定的用户赋值的标签。用户群数据是指符合某些特征的用户群体。
所述统计类标签数据作为基础数据再次统计;所述模型类标签数据作为基础数据再次建模,如图2所示。
5.数据展示层,将数据响应层的标签进行展示。本层可以进行深层用户画像展示,以及进行用户的精准营销展示。数据展示层可以锁定一个用户,查看该时间段的用户地理位置,进行场景营销。
系统功能模块是精准营销,精准营销包括2个模块:
1.个性化推荐,给每个用户推荐自己有可能需要的产品。根据用户在本网络中的购物历史数据,推荐用户可能喜欢或者感兴趣的内容。根据用户在其他网络中的购物历史数据,推荐用户可能喜欢或者感兴趣的内容。根据用户的消费习惯数据、浏览网页数据、购物数据、app使用习惯、用户画像结果等进行数据分析,推荐用户可能喜欢或者感兴趣的内容。
全方位的提供用户个性化产品推荐,通过不同行业之间的数据拉通,进行多方位的用户实体识别,解决传统推荐行业中的冷启动问题,彻底打破企业对冷启动问题的噩梦。同时结合知识图谱等社交网络技术,分析用户的当前需求和需求心理,个性化的推荐产品。
2.场景营销,记录分析用户的位置信息,结合用户历史行为,预测用户最新需求,进行精准化营销,结合当前用户的场景位置,推荐用户当前所需要的信息,包括但不仅限于:美食、路况、住宿、娱乐等。打破传统基于用户历史的行为分析推荐营销,全方位结合用户的位置信息、兴趣偏好、预测当前6小时、12小时、24小时的需求,结合不同的用户场景进行场景营销。
根据上述用户的个性化推荐结果,同时结合用户的位置信息,给用户推荐周边用户可能感兴趣的内容。
上述的基于深度用户画像进行精准营销的系统的实现方法包括如下步骤:
(1)获取数据源,包括用户数据源、普林数据源和爬虫数据源;
(2)使用etl工具或者自己开发代码进行客户数据的清洗、转换和加载;加载好数据后,结合普林数据、爬虫数据进行不同行业之间的数据拉通,实现多方位的用户实体识别,最后将处理完毕的数据导入到hdfs中;
(3)使用spark平台,加载分布式文件系统hdfs中的数据进行数据处理,将spark平台运行出来的标签数据进行保存在数据库中。保存标签的数据库为mysql或者hbase。所述标签数据包括数据计算出来的统计类标签数据、建模算法得出的模型类标签数据、单客户标签数据和标签体系用户群数据。
所述统计类标签数据作为基础数据再次统计;所述模型类标签数据作为基础数据再次建模。
(4)个性化推荐:给每个用户推荐自己有可能需要的产品,根据用户的消费习惯数据、浏览网页数据、购物数据、app使用习惯、用户画像结果、购物历史数据等进行数据分析,推荐用户可能喜欢或者感兴趣的内容,进行个性化推荐;
(5)场景营销:锁定一个用户,根据步骤(4)中用户的个性化推荐结果,同时结合用户的位置信息,给用户推荐周边用户可能感兴趣的内容,同时记录分析用户的位置信息,结合用户历史行为,预测用户最新需求,进行精准化营销。
- 还没有人留言评论。精彩留言会获得点赞!