基于集成学习的果蔬高光谱品质检测方法与流程
本发明属于果蔬检测领域,具体是一种基于集成学习的果蔬高光谱品质检测方法。
背景技术:
高光谱成像系统能获取波长400-1000nm内连续的光谱曲线,波长数众多(有几百甚至上千波长组成),有很多信息是重复的或者是无用信息,甚至是影响到数据模型结果的噪声数据,这对数据分析中模型的准确度、分析的速度都非常不利,也会影响便携式仪器的开发。同时,因为光谱数据信息本身冗余,高光谱成像通常是严重重叠在一起,以致特征吸收峰不明显。因此,通常的做法是采用一定的方法寻找到对于建模有效的波长变量,删除冗余变量,减少波长变量个数,优化模型,提升模型预测精确,我们称为特征变量选择。
特征波长选择方法主要有无信息变量消除法、连续投影算法、遗传算法等,当前相关分析的方法如基于线性的偏最小二乘,多元线性回归及基于非线性的神经网络和支持向量机的,以往都是讲各种单一算法进行对比,优选性能最优提取及相关分析算法来进行作为最终算法。针对采集的数据集某种单一算法表现好,但是如果数据集的改变,相应的最优提取方法也可能随之改变。如果处理预测信息复杂的话,单一特征提取算法出现错误的概率就会越来越大,这样的模型适应性比较弱,现实当中复杂的。
现有的技术方案有如:无信息变量消除法、连续投影算法、遗传算法都是本专利下的子方法,本专利发明将所有的自算法进行融合,集成多个算法成的特征提取器具有比成员提取方法更强的泛化能力。来预测苹果内部品质,提升预测模型性能,稳定性,准确性。
高光谱无损检测品质分析当中,如预测苹果的糖度、硬度、水分等内部品质高光谱检测。针对采集的数据集某种单一算法表现好,但是如果数据集的改变,相应的最优提取和相关性分析方法也可能随之改变。在其研究领域,虽然有很多不同的方法来预测各自领域对象的内部信息,通过对比相关的预测算法。一般来说,这些方法预测得到的结果不是非常稳定和强大的。存在单一性,并不稳定。若同一研究对象下数据的改变可能导致分析结果不同,如果处理预测信息复杂的话,单一特征提取算法出现错误的概率就会越来越大,这样的模型适应性比较弱,现实当中复杂的。学习一个具有较强泛化能力的特征提取,相关性分析技术也成为一个艰巨的任务。
技术实现要素:
本发明根据每种特征提取算法和相关性分析算法的设计原理不同,考虑添加集成学习的技术,集成多个算法成的特征提取器具有比成员提取方法更强的泛化能力。来预测苹果内部品质,提升预测模型性能,稳定性,准确性。
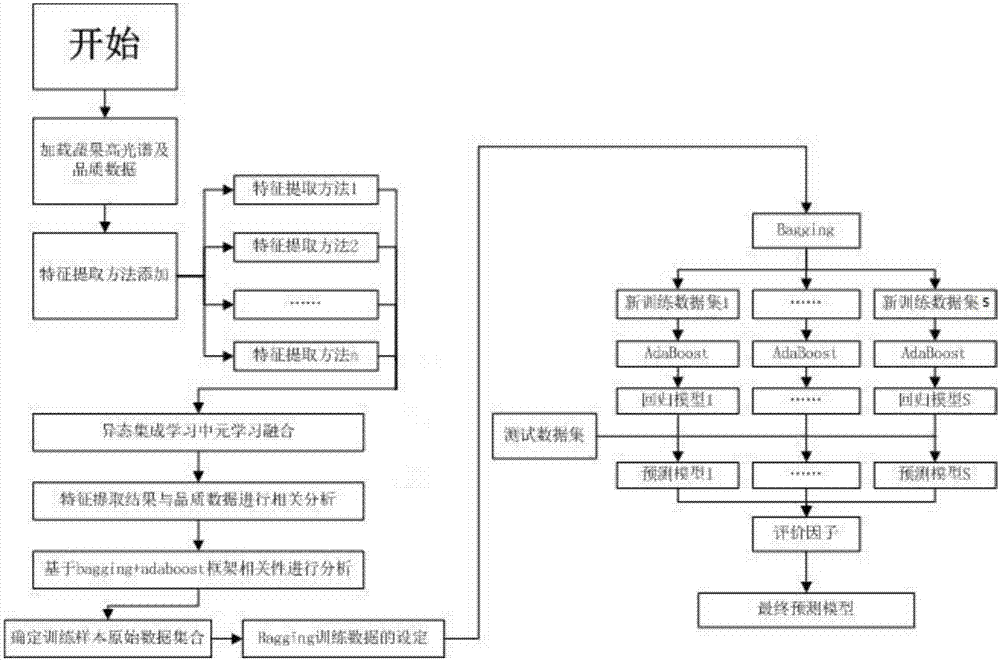
技术方案:一种基于集成学习的果蔬高光谱品质检测方法,开始,选择样本并投入高光谱数据其品质数据,设置并选取若干特征提取的方法,将方法添加到集成学习框架中去,进行分别特征提取;然后由异态集成学习中元学习法针对回归的思想,将每个算法的得到优选波段序号进行加权融合,最终作为融合后得最终提取波段;其次基于bagging+adaboost框架下的多算法高光谱与品质相关分析模型的建立,根据基于集成学习的高光谱和品质相关性分析方法,投入特征高光谱数据、蔬果品质数据;训练数据的设置,默认为训练集为80%,测试集为20%;设置bagging随机抽取比例设置80%-90%,将高光谱数据和品质数据作为原始数据集,将原始数据集进行若干次随机抽样得到若干次新的数据集,设置并选取若干回归分析方法,将方法添加到bagging+adaboost框架中去,依次对新的数据集进行分别回归建模分析,最后根据评价因子得到最终预测模型。
优选的,所述bagging+adaboost框架:bagging随机抽取比例设置形成s次随机,将原始数据集进行随机抽样得到s个新的数据集,依次运用adaboost训练新数据集合进行训练学习,减小弱分类器分类效果较好的数据的概率,增大弱分类器分类效果较差的数据的概率,最终分类器是多个弱分类器的加权平均;思路为设置并选取若干回归分析方法,将方法添加到bagging+adaboost框架中去,依次将新数据集进行回归建模分析,返回结果为各自回归模。
优选的,所述集成学习的高光谱和品质相关性分析方法:特征高光谱数据记为x(n,p);蔬果品质数据记为y(n,1);n为样本数,p为特征波段变量数,
第一步:训练数据的设置,默认为训练集占样本数的80%,测试集占20%;
第二步:设置bagging随机抽取比例80%-90%,将原始数据集进行s次随机抽样得到s个新的数据集,每个数据集为n个样本;
第三步:设置并选取m个回归分析方法,将分析方法添加到bagging+adaboost框架中去,依次对s个新的数据集进行分别回归建模分析,返回结果为各自回归模型。
第四步:通过训练,每个训练集得出对应f(x),即{f1(x),f2(x),…,fs(x)},融合依据为均方根误差权重如下:
f(x)=b1f1(x)+b2f2(x).......+bsfs(x)(b1+b2+b3+.......+bs=1)
其中:zi为对应函数f的均方根误差,z为所有均分根误差和,bi为均方根误差因子,f(x)为最终预测函数。
更优的,所述集成学习的高光谱和品质相关性分析方法第三步的具体过程如下:
301:初始化训练数据的权重分布,第i个训练样本最开始时被赋予同样的权重wm,i,初始权重为1/n。其中:wm,i为第m次迭代第i个训练样本对应的权重(1≤i≤n);
302:针对训练数据选取弱回归算法进行训练y=cm(x),其中:m为迭代序号;
303:计算训练中样本误差值,第i个误差值ξi:
ξi=∑wi(k)|ci(xk)-yi|
其中:i为样本序号,k为样本集序号(1≤k≤s),ci所选的回归算法,yi为第i样本的真实值。
304:计算弱分类器对应的权重α:
其中:αm为第m个次迭代使用的回归算法权重,ξi第i个样本误差值;
305:更新训练集的权重分布(目的得到样本的新权值分布),用于下一轮迭代:dm+1=(wm+1,1,wm+1,2,…,wm+1,n)
其中:dm+1为m+1次下的权重集合,wm+1,i为m+1次下第i个权值,zm为m次迭代的规范化因子,且zm=sum(wi);
306:组合各个弱回归模型从而得到次最终回归模型,如下:
其中:αm和cm(x)分别为第m次迭代中对应的算法的权值及算法函数。
本发明的有益效果
高光谱无损检测品质分析当中,如预测苹果的糖度、硬度、水分等内部品质高光谱检测。针对采集的数据集某种单一算法表现好,但是如果数据集的改变,相应的最优提取和相关性分析方法也可能随之改变。在其研究领域,虽然有很多不同的方法来预测各自领域对象的内部信息,通过对比相关的预测算法。一般来说,预测这些方法得到的结果不是非常稳定和强大的。存在单一性,并不稳定。若同一研究对象下数据的改变可能导致分析结果不同,如果处理预测信息复杂的话,单一特征提取算法出现错误的概率就会越来越大,这样的模型适应性比较弱,现实当中复杂的。
本发明学习一个具有较强泛化能力的特征提取,相关性分析技术。本发明根据每种特征提取算法和相关性分析算法的设计原理不同,考虑添加集成学习的技术,集成多个算法成的特征提取器具有比成员提取方法更强的泛化能力。来预测苹果内部品质,提升预测模型性能,稳定性,准确性。
附图说明
图1为本发明基于集成学习的高光谱品质检测流程图
图2为本发明集成框架工作流程图
具体实施方式
下面结合实施例对本发明作进一步说明,但本发明的保护范围不限于此:
实施例1,结合图1:一种基于集成学习的果蔬高光谱品质检测方法,开始,选择样本并投入高光谱数据其品质数据,设置并选取若干特征提取的方法,将方法添加到集成学习框架中去,进行分别特征提取;然后由异态集成学习中元学习法针对回归的思想,将每个算法的得到优选波段序号进行加权融合,最终作为融合后得最终提取波段;其次基于bagging+adaboost框架下的多算法高光谱与品质相关分析模型的建立,根据基于集成学习的高光谱和品质相关性分析方法,投入特征高光谱数据、蔬果品质数据;训练数据的设置,默认为训练集为80%,测试集为20%;设置bagging随机抽取比例设置80%-90%,将高光谱数据和品质数据作为原始数据集,将原始数据集进行若干次随机抽样得到若干次新的数据集,设置并选取若干回归分析方法,将方法添加到bagging+adaboost框架中去,依次对新的数据集进行分别回归建模分析,最后根据评价因子得到最终预测模型。
实施例2,结合图2:如实施例1所述的基于集成学习的果蔬高光谱品质检测方法,所述bagging+adaboost框架:bagging随机抽取比例设置形成s次随机,将原始数据集进行随机抽样得到s个新的数据集,依次运用adaboost训练新数据集合进行训练学习,减小弱分类器分类效果较好的数据的概率,增大弱分类器分类效果较差的数据的概率,最终分类器是多个弱分类器的加权平均;思路为设置并选取若干回归分析方法,将方法添加到bagging+adaboost框架中去,依次将新数据集进行回归建模分析,返回结果为各自回归模。
实施例3:如实施例1所述的及预计称学习的果树高光谱品质检测方法,所述集成学习的高光谱和品质相关性分析方法:特征高光谱数据记为x(n,p);蔬果品质数据记为y(n,1);n为样本数,p为特征波段变量数,
第一步:训练数据的设置,默认为训练集占样本数的80%,测试集占20%;
第二步:设置bagging随机抽取比例80%-90%,将原始数据集进行s次随机抽样得到s个新的数据集,每个数据集为n个样本;
第三步:设置并选取m个回归分析方法,将分析方法添加到bagging+adaboost框架中去,依次对s个新的数据集进行分别回归建模分析,返回结果为各自回归模型。
第四步:通过训练,每个训练集得出对应f(x),即{f1(x),f2(x),…,fs(x)},融合依据为均方根误差权重如下:
f(x)=b1f1(x)+b2f2(x).......+bsfs(x)(b1+b2+b3+.......+bs=1)
其中:zi为对应函数f的均方根误差,z为所有均分根误差和,bi为均方根误差因子,f(x)为最终预测函数。
实施例4:如实施例3所述的及预计称学习的果树高光谱品质检测方法,所述集成学习的高光谱和品质相关性分析方法第三步的具体过程如下:
301:初始化训练数据的权重分布,第i个训练样本最开始时被赋予同样的权重wm,i,初始权重为1/n。其中:wm,i为第m次迭代第i个训练样本对应的权重(1≤i≤n);
302:针对训练数据选取弱回归算法进行训练y=cm(x),其中:m为迭代序号;
303:计算训练中样本误差值,第i个误差值ξi:
ξi=∑wi(k)|ci(xk)-yi|
其中:i为样本序号,k为样本集序号(1≤k≤s),ci所选的回归算法,yi为第i样本的真实值。
304:计算弱分类器对应的权重α:
其中:αm为第m个次迭代使用的回归算法权重,ξi第i个样本误差值;
305:更新训练集的权重分布(目的得到样本的新权值分布),用于下一轮迭代:dm+1=(wm+1,1,wm+1,2,…,wm+1,n)
其中:dm+1为m+1次下的权重集合,wm+1,i为m+1次下第i个权值,zm为m次迭代的规范化因子,且zm=sum(wi);
306:组合各个弱回归模型从而得到次最终回归模型,如下:
其中:αm和cm(x)分别为第m次迭代中对应的算法的权值及算法函数。
发明点,第一次将组合bagging和adaboost集成用于苹果品质信息(糖度,硬度,水分)预测。建立精度高,稳定性强的苹果内部品质检测模型。针对苹果高光谱品质检测,第一次应用集成的思想将多算法(特征波长提取算法、相关性分析算法)集成起来,来提出了提高建模的性能,更趋近于更高的精度。
解决高光谱品质相关性分析中分析算法(如神经网络和遗传算法等)带参数的学习器的参数选择问题。这些模型的参数多数是根据经验来设定的,没有确定的规则可以依据,参数稍微有所不同,性能可能就有很大的差距。因此,可以学习多个相关分析算法,再通过集成融合得到最后的结果。提高回归结果的稳定性。
本发明的优点:在已知样本集上单个算法,过分的追求正确率,使其在己知样本集上取得很好效果,但是到了测试数据集上效果变得很不好,也就是缺乏泛化能力,这种现象被称为过拟合。根据集成学习的思路,学习多个算法进行融合,即使其中某些会有过拟合,最终形成集成模型也能有很好的泛化能力,不会出现过拟合。
对于不稳定的学习器,不同的训练样本训练以后对同一测试样本可能具有不同结果。因此,可以学习多个学习器(不同的训练样本),在通过集成融合得到最后的结果,可以提高回归结果的稳定性。当高光谱内在品质检测中无法确定最优特征提取算法或相关分析算法时,可以通过集成多算法的思路来解决。
本文中所描述的具体实施例仅仅是对本发明精神做举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!