一种基于规则与层级融合的个性推荐方法与流程
本发明涉及个性化推荐领域,特别涉及一种基于规则与层级融合的个性推荐方法。
背景技术:
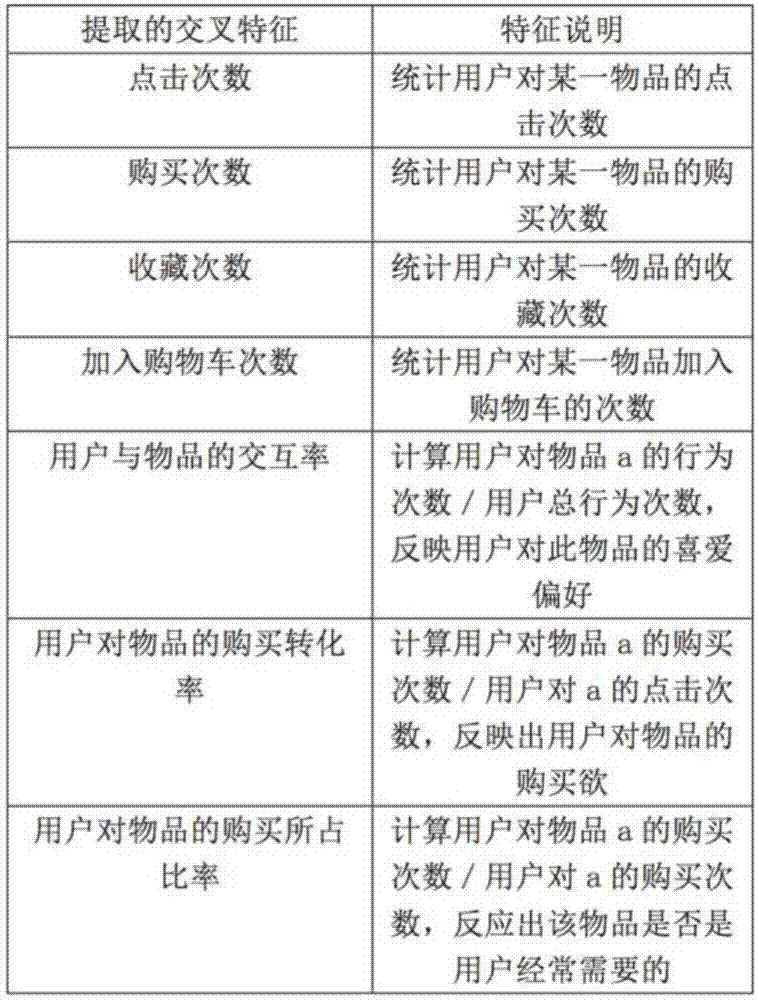
:电子商务的个性推荐一直以来是数据挖掘领域的热点问题,使用最为广泛且较为成熟的方法是协同过滤算法,协同过滤算法不需要领域知识,并且能够推荐出“新产品”。但是协同过滤算法的不足也随着时间的推移显现出来,其稀疏性问题,响应时间较长等问题都制约了推荐系统的性能。虽然近几年有不少学者提出了各种协同过滤算法的改进方法,如基于用户购买记录的改进协同过滤推荐,使用用户的购买记录进行偏好挖掘,并改进相似度计算方法(参见文献何有世,宋翠莉.基于用户购买记录的改进协同过滤推荐[j].计算机工程与设计,2014,35(9):3091-3094)。但是在电子商务问题的推荐上,协同过滤算法在相似度上仍有较大的不足。(1)当用户购买了多个物品时,这些物品在相似度计算时的权值如何确定,都取“1”不合适,会对推荐结果带来不同的影响。(2)基于相似度的推荐结果不对称,例如用户购买了手机,为其推荐手机壳是比较理想的推荐结果,但是当用户购买了手机壳,为其推荐手机则是不合常理的。(3)计算相似度矩阵时,用户的点击、收藏等多种行为无法刻画,只使用购买记录对信息则会造成巨大的浪费。(4)当相似度矩阵极度稀疏时,算法的效率较低。技术实现要素:为了解决传统的推荐方法响应时间较长,因稀疏性、用户数据信息利用率不高等导致推荐效果不理想的问题,本发明提供一种基于规则与层级融合的个性推荐方法,使推荐结果更符合用户期望。为了解决上述技术问题,其技术解决方案为:一种基于规则与层级融合的个性推荐方法,包括以下步骤:步骤1:“用户—物品”行为信息数据采集,采集用户在电子商务网站的对各个物品的行为信息,包括时间、用户id、商品id和行为,所述行为包括点击、收藏、加入购物车和购买;步骤2:对步骤1得到的数据进行预处理与特征提取,所述数据预处理即对数据进行归一化处理,采用离差标准化方法,对步骤1得到的原始数据进行线性变换,使结果值映射到[0-1]之间,转换函数如下:其中,x为样本原数据,max为样本数据的最大值,min为样本数据的最小值,x*为归一化后的新值;所述特征提取通过选取最能反映用户购买导向的特征进行提取计算;步骤3:使用人工规则筛选经过步骤2处理后的初始数据集得到预测结果集set1;步骤4:采用二级融合模型对“用户—物品”进行预测,预测用户可能会购买的物品,预测会购买,则将物品标记为1,否则为0;二级融合模型的第一级模型采用逻辑斯蒂回归模型对经过步骤2处理后的初始数据进行预测,将其预测结果保留;将第一级模型的预测结果作为一个特征加入到经过步骤2处理后的初始数据构成新数据,第二级模型利用此新数据采用随机森林、最近邻、逻辑斯蒂模型分别训练出模型model_1,model_2,model_3,三个模型进行融合,投票得到最终的融合模型,通过融合模型预测得到预测集set2;步骤5:步骤3的预测集set1和步骤4的预测集set2取并集得到最终推荐给用户的商品集。进一步,所述步骤2中提取的特征包括用户对物品a在某一时间段的点击次数、购买次数、收藏次数、加入购物车次数、用户与物品a的交互率、用户对物品a的购买转化率、用户对物品a的购买所占比例。进一步,所述步骤2中去掉包含电商活动日的数据信息。进一步,所述步骤2中去掉包含电商活动日及前后1至3天的数据信息。进一步,所述步骤2中删除含有缺失值的数据。采用人工规则与基于bagging改进的层级融合模型相结合的方法,将推荐问题转换为预测是否购买的二分类问题,进而对用户进行推荐。本发明将问题转换成二分类问题,基于bagging算法,提出了两级模型融合的方法,解决了单模型的推荐效果较低的问题;本发明提出使用一定的人工规则进行预测,预测出了一些算法不能解释的购买情况,使推荐结果的召回率大大提高,综合效果较为显著。附图说明图1为本发明一种基于规则与层级融合的个性推荐方法的总体流程图。图2为本发明一种基于规则与层级融合的个性推荐方法中涉及的交叉特征。图3为本发明一种基于规则与层级融合的个性推荐方法的二级模型图。具体实施方式下面结合附图和具体实施方式对本发明作进一步详细的说明。如图1所示,一种基于规则与层级融合的个性推荐方法包括以下步骤:步骤1:“用户—物品”行为信息数据采集;步骤2:对步骤1得到的数据进行预处理与特征提取;步骤3:使用人工规则对经过步骤2处理后的初始数据集进行筛选,符合预测集的“用户—物品”对加入到预测集,全部筛选完后得到预测集set1;步骤4:二级融合模型对“用户—物品”对进行预测,预测用户可能会购买的物品,预测会购买,则将物品标记为1,否则为0;步骤5:步骤3和步骤4的预测集取并集得到最终推荐给用户商品集。步骤1中,采集“用户—物品”行为信息数据即采集用户在电子商务网站的对各个物品的行为信息,包括时间、用户id、商品id和行为,其中行为包括点击、收藏、加入购物车、购买。步骤2中包括数据预处理与特征提取。步骤2.1数据预处理为了避免因为用户对某一物品的点击、购买次数过高,对模型带来偏差,因此对数据进行归一化处理,采用离差标准化方法对对步骤1得到的数据进行线性变换,使结果值映射到[0-1]之间。转换函数如下:其中,x为样本原数据,max为样本数据的最大值,min为样本数据的最小值,x*为归一化后的新值。数据预处理还包括对异常值处理,考虑到电商有搞活动的情况(如:双十一,唯品会418等),用户在活动当天及前后几天的购买情况均会受到影响,因此此阶段数据不具有说服力,去掉包含活动日及前后1至3天的数据信息。数据预处理还包括处理空值的情况,将含有缺失值的数据删除,以免对推荐效果带来影响。步骤2.2特征提取如图2所示,特征提取即为统计用户对物品a在某一时间段的点击次数、购买次数、收藏次数、加入购物车次数,以及用户与物品a的交互率、用户对物品a的购买转化率和用户对物品a的购买所占比例,将这些特征作为训练集的特征。用户与物品a的交互率=用户对物品a的行为次数/用户总行为次数,反应用户对此物品的喜爱偏好。用户对物品a的购买转化率=用户对物品a的购买次数/用户对a的点击次数,反应用户对此物品的购买欲。用户对物品a的购买所占比例=用户对物品a的购买次数/用户总购买次数,反应该物品是否是用户经常需要的。通过大量的实验和研究对比,虽然可将问题转换成二分类问题进行预测,但是仍有较大数量的物品在预测的用户非购买列表中,但是用户最终却购买了,这也是推荐系统总体召回率不高的原因。因此步骤3中采用了人工规则。利用条件概率的知识,假定一些条件,如:1、用户a在1天前把物品b加入购物车;2、用户a在前几天频繁浏览物品b。基于以上条件,我们可以推出,用户a很有可能在接下来的时间购买物品b。因此,我们制定了一些人工规则,对数据集进行规则筛选,选出符合规则的“用户—物品”对,形成一个初步的预测集set1。另外,把人工预测的数据集范围缩小,越靠近预测日的用户行为越有参考价值。本发明最终使用的人工规则有:1、如果某用户在在预测日前一天将某物品加入购物车,那么将此类物品推荐给该用户;2、如果某用户在前一段时间经常购买的某物品,购买次数超过10次,或者一周内有好几天有购买记录,那么将此类物品推荐给该用户;3、如果某用户在预测日前两周内几乎每天都有点击某商品,那么将此类物品推荐给该用户;4、如果某用户在预测时间之前最后一次访问的是某物品,那么将此类物品推荐给该用户。人工规则不限于上述四种,还可以根据场景进行改变和增删。步骤4中基于bagging算法的二级融合模型包括第一级模型和第二级模型。步骤4.1第一级模型处理集成学习对于基分类模型的组合没有一个比较完善的方法,且大多数的研究都是在改进基分类器的选择,因此本发明采用了两级模型融合的策略,在第一级通过逻辑斯蒂回归模型,利用sigmoid函数进行分类。并对经过步骤2处理后的初始数据的训练集train进行预测,并将预测结果pre_1加入到训练集中,形成训练集train_1,使用此新的训练集作为第二级模型的训练集。模型的回归系数如表1所示,可以看到,在第二级训练时,结果具有更好的解释性,第一次预测购买的用户最终预测结果为购买的机率提高了6倍,使数据更加贴近模型真实情况。表1回归系数步骤4.2第二级模型投票表决根据泛化误差上届定理,对于二分类问题,假设空间是有限个函数的集合f={f1,f2,…,fd},对任意一个函数都至少以概率δ,使得r(f)表示二分类函数f的期望值,表示二分类函数f的经验风险。其中d表示假设空间中函数的个数,n表示样本容量,δ表示概率值。可知,训练误差越小泛化误差越小,推荐系统的效果就会越好。由经验风险最小化原则可知,经验风险最小的模型是最优模型。假设分类函数为f:rn→{c1,c2}其中rn表示n维实数向量空间,c1,c2表示向量空间的两个值误分类的概率为p(y≠f(x)=1-p(y=f(x))其中y表示输入随机变量的实际分类值,f(x)表示输入随机表量x的预测分类值那么多个模型的预测结果的误分类率为其中k表示模型个数,nk(x)表示第k个模型的随机变量空间投票表决等价于经验风险最小化。当数据量增大时,经验风险最小化的效果能够逐渐变好。因此第二级模型采用bagging方法,避免了单个弱学习器的预测效果不足的缺点,通过装袋投票的方式减小训练误差。选用knn、随机森林、逻辑斯蒂回归等单模型,对train_1随机抽样,分别训练出模型model_1,model_2,model_3,三个模型进行融合,投票得到最终的融合模型。通过融合模型预测得到预测集set2,采用两级模型如附图3,能够使数据通过第一级的模型更加贴近实际,更加具有可靠性。步骤5中将步骤3中得到的预测集set1与步骤4中通过二级融合模型得到的预测集set2合并,得到最终的推荐商品集。反映本发明效果的实验验证过程如下所示:数据集选取淘宝4个月(4月15日-8月15日)的用户行为信息对本发明推荐方法进行验证,包括用户id,物品id,行为时间,行为种类等信息,各字段如表2。该数据集包括181882条用户物品行为信息,经过对各种行为统计,共有78873条记录。表2实验验证的数据集说明字段字段说明user_id用户标识brand_id商品标识time用户对商品的行为时间behavior_type用户对商品的行为类型验证的评价标准:对个性推荐系统的评价,不能单纯的看预测的正确率情况,本发明采用国际惯用方式,用经典的精确度(precision)、召回率(recall)和f1值作为评估指标。具体计算公式如下。其中predictionset为算法预测的购买数据集合,referenceset为真实的答案购买数据集合。我们以f1值作为最终的唯一评测标准。协同过滤算法和本发明基于规则与层级融合模型方法的推荐效果对比与分析如下所示:1、协同过滤算法推荐效果在此项推荐任务中,主要利用用户行为的相似度来计算兴趣的相似度,例如用户a和用户b,用n(a)表示用户a购买过的物品集合,n(b)表示用户b购买过的物品集合,采用余弦相似度公式计算兴趣相似度,公式为为了避免因用户数量过多计算两两用户的相似度耗时太长,采取了建立倒查表,即对于每个物品有过购买行为的用户列表,先求出行为交集不为0的用户对{a,b}的方法。最终通过调整k(对某个商品品牌最感兴趣的k个用户),m(向用户推荐的前m个商品品牌)值,得到了推荐最终结果,见表3。表3协同过滤算法推荐结果2、基于规则与层级融合模型方法的推荐效果在测试集上利用人工规则筛选出推荐用户物品对,与二级融合模型融合推荐出的结果相结合。其中逻辑斯蒂模型采用正负样本比1:11,knn模型中近邻数取前8个,随机森林模型生成树为30棵,实验结果如表4。表4基于规则与层级模型融合的推荐结果3、结果分析从上表对比结果分析可以看到,协同过滤算法的确不适合此类任务,无论如何调整k,m值对结果影响较小,总体效果较差,且当相似度矩阵稀疏时,计算花费时间较长;本发明提出的基于规则与层级模型融合的推荐方法,由于基于bagging算法进行的改进,各预测函数并行生成,时间花费较少,并且由于加入了人工规则,效果也显著提高了。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1