一种主题相关的影响力用户发现和追踪方法与流程
本发明涉及机器学习技术领域,特别是指一种主题相关的影响力用户发现和追踪方法。
背景技术:
近年来,社交媒体发展迅速,许多商业应用(如广告、推荐)在社交媒体平台大量涌现。在社交媒体中,用户的影响力可以影响他人的观点和行为。因此,如何充分利用用户的影响力来提升商业应用的效果,成为了急需解决的技术问题。
通常,人们想要找到的是当下有影响力的用户,而影响力会随着时间推移动态变化,为了更准确地衡量用户的影响力,除了利用链接的数量,如何利用链接生成的时间来捕捉影响力的动态变化趋势也极其重要。然而现有技术中,例如现有技术中的link-lda方法和flda方法,通常只利用累积的链接数,如用户的粉丝数,来衡量用户在不同主题上的影响力,以至于他们通常会找到那些影响力已经过时的用户。
技术实现要素:
有鉴于此,本发明的目的在于提出一种主题相关的影响力用户发现和追踪方法,能够发现和追踪社交媒体中主题相关的当下最具有影响力的用户,优化广告和推荐的应用。
基于上述目的本发明提供的一种主题相关的影响力用户发现和追踪方法,包括:
建立tit模型:获取用户的目标社交媒体中的文本数据、链接以及链接生成的时间数据,并建立所述tit模型;
确定隐含参数:利用吉布斯抽样,确定所述tit模型中的隐含参数;其中,所述隐含参数包括用户在主题上的多项式分布θ、主题在单词上的多项式分布
分析用户主题相关影响力分布:通过所述隐含参数和模型参数,得到不同时间在不同主题下的用户主题相关影响力分布σ,得出用户主题相关影响力随时间的变化,从而得出当前时刻或之前任意时刻的用户主题相关影响力;其中,所述模型参数包括:α、β、γ、ε和ρ,其中α、β、γ、ε分别为θ、
可选地,所述tit模型包括用户-链接-时间模块和用户-单词模块;
所述用户-链接-时间模块对用户u的链接f以及链接生成的时间t进行建模,将链接f生成时间t到当前时刻的时间段分成t'个时间片,其中u表示第u个用户,u∈[1,u],u为用户的数量,同时,将整个链接网络当做一个文档,在该文档中,链接f和链接的生成时间t的组合(f,t)被作为该文档的单词;所述用户-链接-时间模块包含一个上层的伯努利混合模型μ、一个下层的多项式混合模型σ以及一个下层的多项式混合模型π,其中,μ用来判断f的生成是否是基于用户u的主题兴趣,通过μ生成二元指示符y,若y=1,即f的生成是基于用户u的主题兴趣,则利用用户u的主题x在(f,t)上的多项式分布σ来生成(f,t);若y=0,即f的生成并非基于用户u的主题兴趣,则利用全局的多项式分布π来生成(f,t);
所述用户-单词模块对用户的目标社交媒体内容进行建模,将各个用户的目标社交媒体内容分别整合为一个文档,并对整合后的所有文档利用lda主题模型来发现用户潜在的主题,从而得到用户在主题上的多项式分布θ,以及主题在单词上的多项式分布
可选地,所述tit模型的生成过程为:利用用户u的主题分布θu,生成一个单词分布主题zu,m,利用单词分布主题zu,m在单词上的分布
可选地,所述利用吉布斯抽样,确定所述tit模型中的隐含参数,包括:
单词分布主题zu,m的抽样公式为:
其中,u表示第u个用户,u∈[1,u],u为用户的数量,m表示用户u的第m个单词,m∈[1,nu],nu为用户u的单词数量,l表示用户u的第l个链接,l∈[1,lu],lu为用户u的链接数量;w表示第w个单词,w∈[1,w],w为不重复的单词的总量;抽样j表示(u,m);次数
链接fu,l和链接生成时间tu,l的抽样公式为:
当yu,l=1时:
当yu,l=0时
其中,抽样i表示(u,l);次数
经过预定次数的抽样迭代后,所述隐含参数确定为:
其中,t代表链接生成时间到当前时间中的某一时刻。
可选地,所述分析用户影响力分布的方法为:
通过所述不同时间在不同主题下的用户主题相关影响力分布σ,利用指数衰减得出用户u在第k个主题下在时间t时的影响力influence(u)@k&t:
其中,λ为控制影响力衰减速度的的参数,λ>0,t为链接f的生成时间。
本发明的另一方面,还提供一种主题相关的影响力用户发现和追踪方法,包括:
建立otit模型:获取用户的目标社交媒体中的文本数据、链接以及链接生成的时间数据,建立所述otit模型;
确定隐含参数:利用吉布斯抽样,确定所述otit模型中的隐含参数;其中,所述隐含参数包括用户在主题上的多项式分布θ、主题在单词上的多项式分布
实时更新模型参数:利用当前数据流中得到的模型参数,作为下一个数据流中模型参数的先验,替换原有模型参数,实现对所述模型参数的实时更新;其中,所述模型参数包括αs、βs、γs、εs和ρs,αs、βs、γs、εs分别为θ、
分析用户主题相关影响力分布:通过所述隐含参数和更新后的所述模型参数,得到用户主题相关影响力分布σ,得出用户主题相关影响力随时间的变化,从而得出当前数据流下的用户主题相关影响力。
可选地,所述otit模型包括用户-链接-时间模块和用户-单词模块:
所述用户-链接-时间模块对用户u的链接f以及链接生成的时间t进行建模,将链接f生成时间t到当前时刻的时间段分成t'个时间片,其中u表示第u个用户,u∈[1,u],u为用户的数量,同时,将整个链接网络当做一个文档,在该文档中,链接f和链接的生成时间t的组合(f,t)被作为该文档的单词;所述用户-链接-时间模块包含一个上层的伯努利混合模型μ、一个下层的多项式混合模型σ以及一个下层的多项式混合模型π,其中,μ用来判断f的生成是否是基于用户u的主题兴趣,通过μ生成二元指示符y,若y=1,即f的生成是基于用户u的主题兴趣,则利用用户u的主题x在(f,t)上的多项式分布σ来生成(f,t);若y=0,即f的生成并非基于用户u的主题兴趣,则利用全局的多项式分布π来生成(f,t);
所述用户-单词模块对用户的目标社交媒体中的内容进行建模,将各个用户的目标社交媒体中的内容分别整合为一个文档,并对整合后的所有文档利用lda主题模型来发现用户潜在的主题,从而得到用户在主题上的多项式分布θ,以及主题在单词上的多项式分布
可选地,所述otit模型的生成过程为:利用用户u的主题分布θu,生成一个单词分布主题zu,m,利用单词分布主题zu,m在单词上的分布
可选地,所述利用吉布斯抽样,确定所述otit模型中的隐含参数,包括:
所述单词分布主题zu,m的抽样公式为:
其中,u表示第u个用户,u∈[1,u],u为用户的数量,m表示用户u的第m个单词,m∈[1,nu],nu为用户u的单词数量,l表示用户u的第l个链接,l∈[1,lu],lu为用户u的链接数量;w表示第w个单词,w∈[1,w],w为不重复的单词的总量;抽样j表示(u,m);次数
所述链接fu,l和链接生成时间tu,l的抽样公式为:
当yu,l=1时:
当yu,l=0时
其中,抽样i表示(u,l);次数
经过预定次数的抽样迭代后,流s中所述隐含参数确定为:
其中,(*)s表示流s中的对应参数。
可选地,所述利用当前数据流中得到的模型参数,作为下一个数据流中模型参数的先验,替换原有模型参数的方法为:
其中,λ'和λ均为控制影响力衰减速的的参数,可根据实际需要进行设置,λ'>0,λ>0;
可选地,所述分析用户影响力分布的方法为:
通过更新了所述模型参数后的所述otit模型,得到当前数据流下的用户主题相关影响力分布σ,从而得到用户主题相关影响力的分布及变化,则用户u在第k个主题下在时间t时的影响力influence(u)@k&t:
influence(u)@k&t=σk,t,u。
从上面所述可以看出,本发明提供的一种主题相关的影响力用户发现和追踪方法通过结合考虑时间因素以及主题相关性的手段,适应影响力随时间的动态变化,并且通过调控数据流的大小,能够获得具有不同时间粒度的结果,通过在线的方式全面而准确地发现和追踪有影响力的用户,更精确地反映用户的影响力变化,克服了仅仅利用累计链接找到过时的影响力用户的技术缺陷,能够得出用户影响力的动态变化及趋势,并进行实时跟踪。
附图说明
图1为本发明实施例1一种主题相关的影响力用户发现和追踪方法流程示意图;
图2为本发明实施例1一种主题相关的影响力用户发现和追踪方法tit模型示意图;
图3为本发明实施例2一种主题相关的影响力用户发现和追踪方法流程示意图;
图4为本发明实施例2一种主题相关的影响力用户发现和追踪方法otit模型示意图;
图5为本发明实施例一种主题相关的影响力用户发现和追踪方法在不同主题下与现有技术的准确度比较示意图;其中图5(a)为在医疗主题下不同方法准确度比较示意图,图5(b)为在电影主题下不同方法准确度比较示意图,图5(c)为在所有主题不同方法平均准确度比较示意图;
图6为本发明实施例一种主题相关的影响力用户发现和追踪方法人工评判对比示意图;
图7为本发明实施例一种主题相关的影响力用户发现和追踪方法效率比较示意图;
图8为本发明实施例一种主题相关的影响力用户发现和追踪方法内存消耗比较示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。
实施例1:
本发明实施例1提供的一种主题相关的影响力用户发现和追踪方法利用tit(topic-levelinfluenceovertime,主题相关的时间影响力分析模型)模型,能够以离线的方式发现主题相关当下有影响力的用户。
如图1所示,为本发明实施例1一种主题相关的影响力用户发现和追踪方法流程图。所述一种主题相关的影响力用户发现和追踪方法包括:
1.建立tit模型:获取用户的目标社交媒体中的文本数据、链接以及链接生成的时间数据,建立所述tit模型;
2.确定隐含参数:利用吉布斯抽样,确定所述tit模型中的隐含参数,所述隐含参数包括用户在主题上的多项式分布θ、主题在单词上的多项式分布
3.分析不同时间在不同主题下的用户主题相关影响力分布:通过所述隐含参数和模型参数,得到不同时间在不同主题下的用户主题相关影响力分布σ,得出用户主题相关影响力随时间的变化,从而得出当前时刻或之前任意时刻的用户主题相关影响力;
所述模型参数包括:α、β、γ、ε和ρ,其中α、β、γ、ε分别为θ、
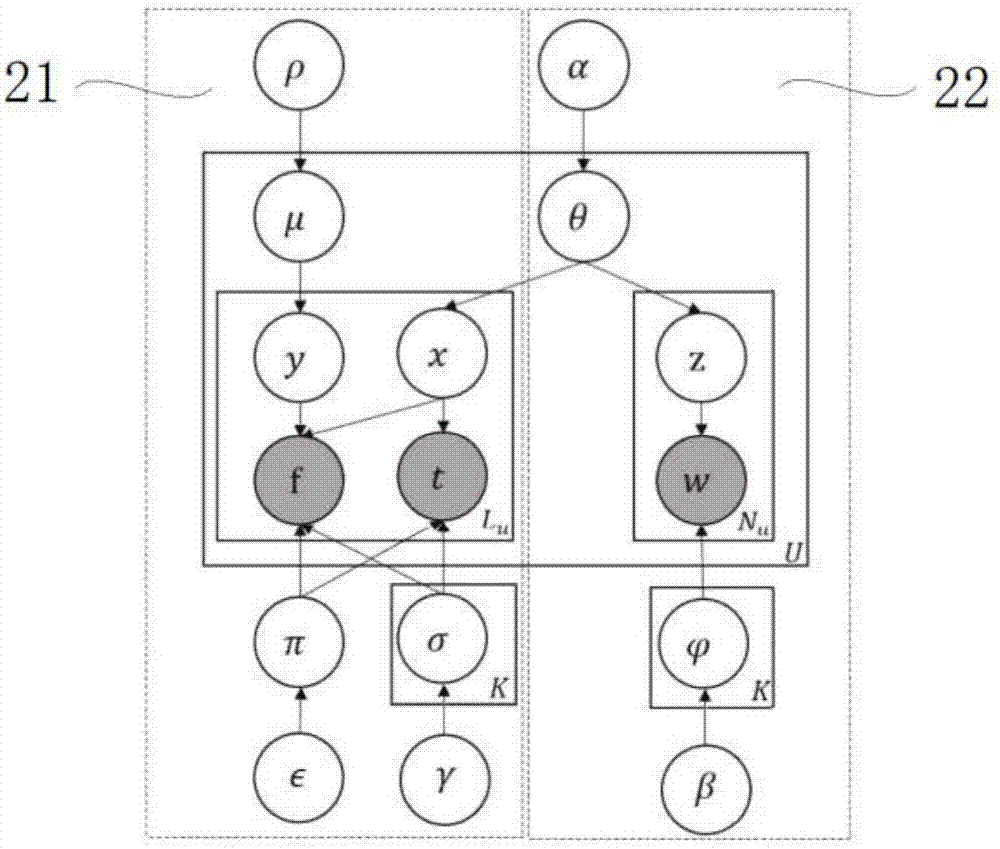
如图2所示,为本发明实施例1一种主题相关的影响力用户发现和追踪方法tit模型示意图,所述tit模型包括用户-链接-时间模块11和用户-单词模块12,其中,u表示第u个用户,u∈[1,u],u为用户的数量;w表示第w个单词,w∈[1,w],w为不重复的单词的总量;f表示用户u关注另一用户产生的链接,t为链接f的生成时间;t'为第t'个时间片,所述时间片长度为δ,t'∈[1,t'],t'为时间片的数量;x表示指派给链接f的主题;z表示指派给单词w的主题;y为二元指示符,指示用户u产生的链接f是否基于用户u的主题兴趣;k表示主题的数量;nu为用户u的单词数量;lu为用户u的链接数量。
用户-链接-时间模块11对用户u的链接f以及链接生成的时间进行建模,将链接f生成时间t到当前时刻的时间段分成t'个时间片,同时,将整个链接网络当做一个文档。在该文档中,链接f和链接的生成时间t的组合(f,t)被作为该文档的单词。用户-链接-时间模块11包含一个上层的伯努利混合模型μ、一个下层的多项式混合模型σ以及一个下层的多项式混合模型π。其中,μ用来判断f的生成是否是基于f产生者(用户u)的主题兴趣,通过μ生成二元指示符y,若y=1,即f的生成是基于用户u的主题兴趣,则利用用户u的主题x在(f,t)上的多项式分布σ来生成(f,t);若y=0,即f的生成并非基于用户u的主题兴趣,则利用全局的多项式分布π来生成(f,t)。
用户-单词模块12对用户的目标社交媒体中的内容进行建模,将各个用户的目标社交媒体中的内容分别整合为一个文档,并对整合后的所有文档利用基于lda(latentdirichletallocation,隐含狄利克雷分布)的lda主题模型来发现用户潜在的主题,从而得到用户在主题上的多项式分布θ,以及主题在单词上的多项式分布
所述tit模型的生成过程为:
一方面,利用用户u的主题分布θu,生成一个单词分布主题zu,m,其中m表示用户u的第m个单词,m∈[1,nu],利用单词分布主题zu,m在单词上的分布
本发明实施例1利用吉布斯采样来推断并生成所述tit模型中的隐含参数。则所述单词分布主题zu,m的抽样公式为:
抽样j表示(u,m),
所述链接fu,l和链接生成时间tu,l的抽样公式为:
当yu,l=1时:
当yu,l=0时
其中,抽样i表示(u,l),次数
在经过预定次数的抽样迭代后,通过如下公式确定所述隐含参数:
所述抽样迭代的次数根据实际需求进行设定。通过所述tit模型,可以得到用户在主题上的多项式分布θ、主题在单词上的多项式分布
本发明实施例1提供的分析用户影响力分布的方法为:
通过所述不同时间在不同主题下的用户主题相关影响力分布σ,得到用户主题相关影响力随时间的变化,利用指数衰减得出用户u在第k个主题下在时间t时的影响力influence(u)@k&t:
其中,λ为控制影响力衰减速度的的参数,λ>0。当t为当前时间时,即可得到当前时间用户u在主题k下的影响力。
从上面所述可以看出,本发明实施例1提供的一种主题相关的影响力用户发现和追踪方法通过结合考虑时间因素以及主题相关性的手段,适应影响力随时间的动态变化,能够通过离线的方式全面而准确地发现和追踪有影响力的用户,克服了仅仅利用累计链接找到过时的影响力用户的技术缺陷,并且能够得出用户影响力的动态变化及趋势。
实施例2
本发明实施例2提供的一种主题相关的影响力用户发现和追踪方法,通过构建otit(onlinetopic-levelinfluenceovertime,在线主题相关的时间影响力分析模型)对以数据流形式到达的数据进行处理,实现在动态数据流中发现并追踪主题相关的影响力用户。
如图3所示,为本发明实施例2一种主题相关的影响力用户发现和追踪方法流程图。所述一种主题相关的影响力用户发现和追踪方法包括:
1.建立otit模型:获取用户的目标社交媒体中的文本数据、链接以及链接生成的时间数据,建立所述otit模型。
2.确定otit模型的隐含参数:通过吉布斯抽样,确定所述otit模型的隐含参数,所述隐含参数包括用户u在主题上的多项式分布θ、主题在单词上的多项式分布
3.实时更新模型参数:利用当前数据流中得到的模型参数,作为下一个数据流中模型参数的先验,替换原有模型参数,实现对所述模型参数的实时更新,所述模型参数包括αs、βs、γs、εs和ρs,其中αs、βs、γs、εs分别为θ、
4.分析不同时间在不同主题下的用户主题相关影响力分布:通过所述隐含参数和更新后的所述模型参数,得到用户主题相关影响力分布σ,得出用户主题相关影响力随时间的变化,从而得出当前数据流下的用户主题相关影响力。
如图4所示,为本发明实施例2一种主题相关的影响力用户发现和追踪方法otit模型示意图,所述otit模型包括用户-链接-时间模块41和用户-单词模块42,其中,u表示第u个用户,u∈[1,u],u为用户的数量;w表示第w个单词,w∈[1,w],w为不重复的单词的总量;f表示用户u关注另一用户产生的链接;t为链接f的生成时间;t'为第t'个时间片,所述时间片长度为δ,t'∈[1,t'],t'为时间片的数量;s表示第s个数据流,其大小为δ',s=0,1,2,…,δ'的取值可根据结果的时间粒度需求设定;x表示指派给链接f的主题;z表示指派给单词w的主题;y为二元指示符,指示用户u产生的链接f是否基于用户u的主题兴趣;k表示主题的数量;nu为用户u的单词数量;lu为用户u的链接数量。
用户-链接-时间模块41对用户u的链接f以及链接生成的时间进行建模,将链接f生成时间t到当前时刻的时间段分成t'个时间片,同时,将整个链接网络当做一个文档。在该文档中,链接f和链接的生成时间t的组合(f,t)被作为该文档的单词。用户-链接-时间模块11包含一个上层的伯努利混合模型μ、一个下层的多项式混合模型σ以及一个下层的多项式混合模型π,其中,μ用来判断f的生成是否是基于f产生者(用户u)的主题兴趣,通过μ生成二元指示符y,若y=1,即f的生成是基于用户u的主题兴趣,则利用用户u的主题x在(f,t)上的多项式分布σ来生成链接f和链接生成时间t的组合(f,t);若y=0,即f的生成并非基于用户u的主题兴趣,则利用全局的多项式分布π来生成(f,t)。
用户-单词模块42对用户的目标社交媒体中的内容进行建模,将各个用户的目标社交媒体中的内容分别整合为一个文档,并对整合后的所有文档利用基于lda(latentdirichletallocation,隐含狄利克雷分布)的lda主题模型来发现用户潜在的主题,从而得到用户在主题上的多项式分布θ,以及主题在单词上的多项式分布
所述otit模型的生成过程为:
一方面,利用用户u的主题分布θu,生成一个单词分布主题zu,m,其中m表示用户u的第m个单词,m∈[1,nu],利用单词分布主题zu,m在单词上的分布
本发明实施例2利用吉布斯采样来推断并生成所述otit模型中的隐含参数。则所述单词分布主题zu,m的抽样公式为:
抽样j表示(u,m),
所述链接fu,l和链接生成时间tu,l的抽样公式为:
当yu,l=1时:
当yu,l=0时
其中,抽样i表示(u,l),次数
在经过足够次数的抽样迭代后,通过如下公式确定所述隐含参数:
其中,(*)s表示流s中的对应参数;通过所述otit模型,可以得到用户在主题上的多项式分布θ、主题在单词上的多项式分布
所述利用当前数据流中得到的模型参数,作为下一个数据流中模型参数的先验,替换原有模型参数的方法为:
其中,λ'和λ均为控制影响力衰减速的的参数,可根据实际需要进行设置,λ'>0,λ>0;
本发明实施例2提供的分析用户影响力分布的方法为:
通过更新了所述模型参数后的所述otit模型,得到当前数据流下的用户主题相关影响力分布σ,从而得到用户主题相关影响力的分布及变化,则用户u在第k个主题下在时间t时的影响力influence(u)@k&t:
influence(u)@k&t=σk,t,u
从上面所述可以看出,本发明实施例2提供的一种主题相关的影响力用户发现和追踪方法通过结合考虑时间因素以及主题相关性的手段,适应影响力随时间的动态变化,并且通过调控数据流的大小,能够获得具有不同时间粒度的结果,通过在线的方式全面而准确地发现和追踪有影响力的用户,更精确地反映用户的影响力变化,克服了仅仅利用累计链接找到过时的影响力用户的技术缺陷,能够得出用户影响力的动态变化及趋势,并进行实时跟踪。
利用本发明提供的一种主题相关的影响力用户发现和追踪方法(otit模型)与现有技术中的link-lda方法和flda方法,同时对同一数据集进行处理,发掘所述数据集中的主题相关影响力用户,得到的比较结果如下:
所述数据集为来自新浪微博的时间跨度为从2015年12月1号到2016年1月5号的数据所述数据集包含0.4m用户、207m的单词和4.6m的用户关注关系(其中0.7m的用户关注关系包含时间信息),时间片长度δ=1.5天,时间片数量t的范围为1到24,第24各个时间片表示距离现在最近的时间片。其中一个数据流包含4个时间片,数据流的大小δ'=6,数据流个数s的范围为1到6。对于没有时间信息的关注信息,随机指派一个从-400到0的值,这部分数据作为数据流s=0的信息;主题数k=100,otit模型的初始模型参数设置为:
如图5所示,为本发明实施例一种主题相关的影响力用户发现和追踪方法在不同主题下与现有技术的准确度比较示意图;其中图5(a)为在医疗主题下不同方法准确度比较示意图,图5(b)为在电影主题下不同方法准确度比较示意图,图5(c)为在所有主题不同方法平均准确度比较示意图,所述准确度比较以新浪微博给出的不同主题下用户流行度的前100名为参考标准,将不同方法得到的排名中前k名用户中出现在参考标准中的比例做为准确度,可以看出,本发明实施例提供的一种主题相关的影响力用户发现和追踪方法相比现有技术能够更准确地发掘数据集中的影响力用户。
如图6所示,为本发明提供的人工评判对比示意图,分别提取每一不同主题下由3种方法得到的排序结果中的前20个用户,并将提取得到的每一不同主题下的不超过60个用户的充分混合的结果作为待测样本,由同一组由大量用户组成的评判组对每一不同主题下的待测样本进行相关性评判,所述相关性评判依据相应主题下用户的流行程度,评价标准为:3分:极好、2分:好、1分:一般和0分:差。3种方法取得的结果的平均得分如图5所示,可以看出本采用发明实施例提供的一种主题相关的影响力用户发现和追踪方法得到的用户影响力结果更符合人工评判的标准,准确性更高。
如图7所示,为本发明提供的效率比较示意图,如图8所示,为本发明提供的内存消耗比较示意图,3种方法处理相同的数据时的时间消耗和内存消耗分别如图7和图8所示,可以看出在处理相同的数据的情况下,本发明实施例提供的一种主题相关的影响力用户发现和追踪方法具有更低的内存消耗和时间消耗,由于采用了otit模型进行在线发现和追踪,每次仅需要对新到的数据流进行处理,内存消耗和处理时间都仅仅取决于新到的数据流的大小,相比现有技术的处理方式,处理效率和系统消耗都大大降低,大大提高了影响力用户的发现和追踪效率。
所属领域的普通技术人员应当理解:以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!