基于主题模型的同义词自动发现方法及其系统与流程
本发明涉及自然语言处理技术领域,尤其涉及一种基于主题模型的同义词自动发现方法及其系统。
背景技术:
随着信息化时代的发展,网络文本数据的规模越来越大,因此对自然语言的处理也渐渐变得尤为重要,基于新出现的词汇也越来越多,语义自动分析技术、如同义词自动发现技术的重要性也日渐体现。现有主流同义词自动发现算法需要先验知识以构建同义词发现的参考文本模式,这限制了同义词发现的效率;而另外一种参考文本模式匹配法,需要事先手工对已知词汇的词性、语义进行标注,构建参考文本模式。
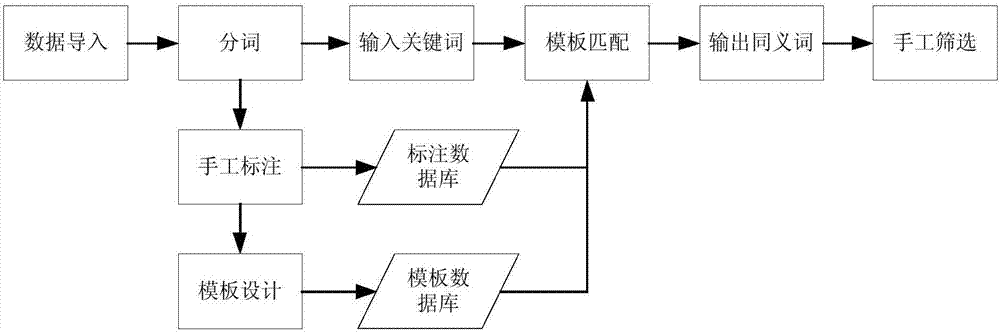
参考图1可见,现有的系统中对于同义词的发现,都需要辅以手工筛选,由于自动发现的同义词的方法存在一定错误率,目前的同义词发现方法均有效率低的问题。
目前在专利申请号为cn201410156107.5的申请中,要求保护一种同义词的确定、搜索方法和服务器,但是根据申请文件中对技术方案的理解,对比文件给出的方案也并不能提高同义词发现的效率。
技术实现要素:
本发明目的是提出一种基于主题模型的同义词自动发现方法,通过分析词的互现概率,构建主题模型,利用吉布斯采样法将同一主题的词聚集到同一聚类,再用迭代最小相关法将各个聚类的词进一步聚类,获得备选的同义词分组。
本发明解决技术问题采用如下技术方案:
一种基于主题模型的同义词自动发现方法,至少包括以下步骤:
导入待发现同义词的数据;
根据数据库的信息对导入的数据进行分词处理;
构建主题模型并进行主题模型聚类;
对主题聚类进行最小相关聚类;
输出同义词。
其中,在输出同义词步骤之后还包括人工筛选同义词的步骤。
其中,所述的主题模型可为隐狄利克雷分配模型,聚类的步骤至少包括:
从狄利克雷分布dirα中取样生成文档i的主题分布θi,其中α是由用户预设的狄利克雷分布的参数,表示主题在文档上分布的均衡程度;θ是dirα上的一个采样;
从主题的分布θi中采样生成文档i第j个词的主题zi,j;
从狄利克雷分布dirβ(β是狄利克雷分布的参数)中取样生成主题zi,j上词的分布
从词语的分布
其中,所述的主题模型的聚类在所有其他词所归属的主题确定的前置条件下,某个词zi属于主题j的后验概率p为:
其中,w是总的词数,t是总的隐含主题数,α、β如上所述是用户设定的参数,
其中,所述的主题聚类为吉布斯采样法的主题聚类,至少包括以下步骤:
a、文档集中的每一个词都随机的分派到一个主题;
b、将文档集的每一个词赋予每一个主题,计算这种情况下词属于这个主题的概率p,最后该词属于p最高的主题;
c、迭代的执行步骤b,直到每次迭代的概率变化量少于用户给定的阈值。
其中,对主题聚类进行最小相关聚类时,通过pearson相关系数计算词在文档集中的共现情况,对于属于主题t的词wi来说,这个词在文档dk中出现的次数是ri,k,构建一个向量
其中,
其中,最小相关聚类至少包括:
a1、将t中的每一个词都随机的赋予一个聚类;
b1、将每一个词赋予每一个主题,计算这个词的向量和每一个主题(排除掉这个词之后)的平均向量之间的pearson相关系数,选择pearson相关系数最低的类作为这个词所属的聚类;
c1、迭代的执行步骤b1,直到每次迭代产生的相关系数改变量低于阈值。
一种基于主题模型的同义词自动发现系统,包括存储有自然语言处理信息的数据库,其特征在于,至少还包括:
数据导入模块,用于导入待发现同义词的数据;
分词处理模块,用于根据所述的数据库的信息对导入的数据进行分词处理;
主题模型聚类模块,用于构建主题模型并进行主题模型聚类;
最小相关聚类模块,用于对主题聚类进行最小相关聚类;
同义词输出模块,用于输出同义词数据本发明具有如下有益效果:
本发明公开了一种基于主题模型的同义词自动发现方法。通过分析词的互现概率,构建主题模型,聚集表述同一主题的词。然后,通过最小相关聚类方法,进一步将主题聚类到备选同义词分组。本发明不需要先验知识,和手工标注,实现同义词的自动聚类,提高了同义词发现的效率;并在一定程度上解决了语义近似性的问题,实施过程中除最后筛选外无需手工干预,从而对同义词自动发现的效率有较大的提升。
附图说明
图1为现有技术中同义词发现系统的方法流程图;
图2为本发明的基于主题模型的同义词自动发现方法的流程示意图。
具体实施方式
下面结合实施例及附图对本发明的技术方案作进一步阐述。
本发明提供的一种基于主题模型的同义词自动发现方法,至少包括以下步骤:
导入待发现同义词的数据;
根据数据库的信息对导入的数据进行分词处理;
构建主题模型并进行主题模型聚类;
对主题聚类进行最小相关聚类;
输出同义词。
在本发明的方法中,在输出同义词步骤之后还包括人工筛选同义词的步骤,对于人工筛选同义词的技术可以采用现有技术来实现,因此在本实施例中不再进行赘述。
在本发明中,所述的主题模型可为隐狄利克雷分配模型,聚类的步骤至少包括:
从狄利克雷分布dirα中取样生成文档i的主题分布θi,其中α是由用户预设的狄利克雷分布的参数,表示主题在文档上分布的均衡程度;θ是dirα上的一个采样;
从主题的分布θi中采样生成文档i第j个词的主题zi,j;
从狄利克雷分布dirβ(β是狄利克雷分布的参数)中取样生成主题zi,j上词的分布
从词语的分布
所述的主题模型的聚类在所有其他词所归属的主题确定的前置条件下,某个词zi属于主题j的后验概率p为:
其中,w是总的词数,t是总的隐含主题数,α、β如上所述是用户设定的参数,
所述的主题聚类为吉布斯采样法的主题聚类,至少包括以下步骤:
a、文档集中的每一个词都随机的分派到一个主题;
b、将文档集的每一个词赋予每一个主题,计算这种情况下词属于这个主题的概率p,最后该词属于p最高的主题;
c、迭代的执行步骤b,直到每次迭代的概率变化量少于用户给定的阈值。
另外,对主题聚类进行最小相关聚类时,通过pearson相关系数计算词在文档集中的共现情况,对于属于主题t的词wi来说,这个词在文档dk中出现的次数是ri,k,构建一个向量
其中,
最小相关聚类至少包括以下步骤:
a1、将t中的每一个词都随机的赋予一个聚类;
b1、将每一个词赋予每一个主题,计算这个词的向量和每一个主题(排除掉这个词之后)的平均向量之间的pearson相关系数,选择pearson相关系数最低的类作为这个词所属的聚类;
c1、迭代的执行步骤b1,直到每次迭代产生的相关系数改变量低于阈值。
另外本发明还提供一种采用上述方法的基于主题模型的同义词自动发现系统,包括存储有自然语言处理信息的数据库,同时参考图2,至少还包括:
数据导入模块,用于导入待发现同义词的数据;
分词处理模块,用于根据所述的数据库的信息对导入的数据进行分词处理;
主题模型聚类模块,用于构建主题模型并进行主题模型聚类;
最小相关聚类模块,用于对主题聚类进行最小相关聚类;
同义词输出模块,用于输出同义词数据。
本发明所述的方法可以应用在海量无标注文本材料的分析上,尤其适合于语料库冷启动以及缺乏已知的同义词数据的情况。
进一步参考图2可见,本发明的系统流程中,包括有数据导入,分词,主题模型聚类,最小相关聚类,输出同义词以及可选的手工筛选模块。其中,所述的数据导入是指:将作为基础数据的一定量文本导入到系统,这里的一个文本可以是一则新闻,一则广告,一篇学术论文等。通常这是与企业特定业务相关的一组文档的集合。所述的分词是指:由于中文语境的词与词之间没有分隔符,为了进一步处理导入的文本集,实现语义分析,需要对文本进行分词。分词的相关技术可以采用现有技术来实现,因此在此不再进行赘述。另外,在本发明的实施例中也选择的采用手工标注,通常分为对分词后的结果进行词性标注、语义标注,词性标注指标注一个词是动词、名词、还是连词等等;语义标注指进一步将词根据预设的类别分类,如“哈士奇”属于动物类,“钢笔”属于办公用品类,等等。而分析词出现的规律,发现频繁的语义序列,即产生模板。在同一个语义序列的同一位置出现的词可能是同义词,例如“今天英语考试”转换成语义序列是“时间-课程-动词”,于是同一语义序列的“明天数学测验”的“测验”与“今天英语考试”的“考试”在同一位置,可能是同义词。有关模板的生成也完全可以采用现有的技术来实现,因此不再进行赘述。另外对于输出同义词是指:对于用户输入的关键词,系统在模板库中寻找适合这一关键词的模板,用模板在输入的文本集中发现关键词的备选同义词,最后通过手工筛选,确定同义词关系。在本发明的实施例中,图2中的数据导入,分词,手工标注,模板生成以及同义词输出均可采用与图1中相同的技术实现。
本实施例中,有关于主题模型聚类:
根据隐狄利克雷分配(latentdirechletallocation,lda)模型对自然语言文本中各个词产生频率的研究,其中还模型存在着一个隐含的主题(topic)集,语义上说,文档集中的各个文档是对这个主题集中某个(多个)主题的表述,而文档中每个词都可以归于某一个主题(topic)。根据lda模型,一个文档的生成过程如下:
a)从狄利克雷分布dirα中取样生成文档i的主题分布θi,其中α是狄利克雷分布的参数,表示主题在文档上分布的均衡程度,一般由用户预设;θ是dirα上的一个采样;
b)从主题的分布θi中采样生成文档i第j个词的主题zi,j;
c)从狄利克雷分布dirβ(β是狄利克雷分布的参数)中取样生成主题zi,j上词的分布
d)从词语的分布
而事实上,由于不知道隐含主题的分布情况,一般都需要通过文档集中词的分布反算主题的分布,进行拟合,使得反算出来的主题分布尽量符合实际的词分布情况。一般常用的拟合方法有最大似然法和吉布斯采样法两种,两者计算复杂度均为o(n*t*i),处于同一水平。在所有其他词所归属的主题确定的前置条件下,某个词zi属于主题j的后验概率p的计算公式为(公式1):
在公式1中,w是总的词数,t是总的隐含主题数,α、β如上所述是用户设定的参数,
由此根据公式1,吉布斯采样法的主题聚类实现方法如下:
a)文档集中的每一个词都随机的分派到一个主题;
b)根据公式1,将文档集的每一个词赋予每一个主题,计算这种情况下词属于这个主题的概率p,最后该词属于p最高的主题;
c)迭代的执行b),直到每次迭代的概率变化量少于用户给定的阈值。
在本实施例中,主题模型聚类的输入是切词后的文档集,输出是每个词所属的主题聚类,下面对最小相关聚类进行进一步的说明:
1、在进行最小相关聚类处理时,属于同一主题的词不一定是同义词,例如,讲述灾害主题的新闻中,“唐山”,“大地震”两个词在讲述同一事件,属于同一主题,但并非同义词,因为他们两者分别属于不同的语义分组。因此,需要对同一主题中的词进一步聚类,形成分组,每个分组中的词更可能是同义词。
鉴于现有解决方案中关于上下文模式的内容,同义词通常会出现在不同文档中同一模式的位置,也就是说,同义词一般不会在同一文档中出现。因此,可以根据词的共现情况将同一主题中的词进一步聚类,互相共现都很少的一组词更有可能是同义词。
2、在进行最小相关聚类处理时,可以通过pearson相关系数计算词在文档集中的共现情况。对于属于主题t的词wi来说,这个词在文档dk中出现的次数是ri,k。于是,对于每一个词,都可以构建一个向量
在公式2中,
在采用最小相关聚类方法将同一主题中的词进一步聚类,产生出备选的同义词分组。最小相关聚类方法的含义是,产生一批聚类,每一个聚类中各个词之间两两pearson相关系数最小。
最小相关聚类的实现方法如下:
a)将t中的每一个词都随机的赋予一个聚类;
b)将每一个词赋予每一个主题,计算这个词的向量和每一个主题(排除掉这个词之后)的平均向量之间的pearson相关系数,选择pearson相关系数最低的类作为这个词所属的聚类;
c)迭代的执行b),直到每次迭代产生的相关系数改变量低于阈值。
在本发明中,主题模型聚类的输入是每个词所属的主题聚类,输出是对主题进一步细分的备选同义词分组,其中每个分组中的词都属于同一个语义类别,属于同义词。
综上所述,本发明的方法通过分析词的互现概率,构建主题模型,聚集表述同一主题的词。然后,通过最小相关聚类方法,进一步将主题聚类到备选同义词分组。本发明在一定程度上解决了语义近似性的问题,实施过程中除最后筛选外无需手工干预,从而对同义词自动发现的效率有较大的提升。
以上实施例的先后顺序仅为便于描述,不代表实施例的优劣。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!