Hadoop平台下的C‑DBSCAN‑K聚类算法的制作方法
本发明属于计算机数据挖掘技术领域,涉及一种hadoop平台下的c-dbscan-k聚类算法。
背景技术:
如今,互联网技术发展迅速,internet深入人们的生活,现代社会已经进入一个信息化的时代,大量的数据信息星罗棋布。在面对海量的数据时,首要任务就是对其进行合理的归类,聚类分析就是这样一种方法。使用聚类,人们可以从包含大量对象的数据集中智能、自动地辨别出有价值的分类知识,获取数据的分布状态,观察不同簇彼此之间的差异,并在此基础上,对某些特定的簇集合做更深层次的分析。在商务智能、图像模式识别、web搜索等领域,都广泛的使用了聚类分析技术。
然而,随着互联网时代的迅速发展和移动设备的广泛使用,数据信息成指数级的增长,传统的、单机上运行的聚类算法在效率上已经不能满足人们的需求。hadoop分布式平台是处理大数据的利器,它为数据挖掘提供了条件,如何使用hadoop进行数据挖掘,如何将传统的、单机上运行的算法结合mapreduce模型进行分布式设计,使其能够使用hadoop分布式平台高效地处理海量的数据,具有很重要的意义。
技术实现要素:
本发明的目的是提供一种hadoop平台下的c-dbscan-k聚类算法,解决了现有技术中存在的dbscan聚类算法在大规模数据集上聚类效率低下的问题。
本发明所采用的技术方案是,hadoop平台下的c-dbscan-k聚类算法,包括以下步骤:
步骤1,将多台计算机连接到同一局域网中,每台计算机作为一个节点,建立能够相互通信的集群;
步骤2,为集群建立hadoop平台;
步骤3,使用hadoop分布式文件命令dfs–put将待聚类数据集a上传至hadoop分布式文件系统;
步骤4,执行canopy聚类算法对待聚类数据集a中的数据进行初始聚类,得到粗粒度的聚类结果;
步骤5,在步骤4得到的聚类上构造k-d树;
步骤6,对步骤4得到的聚类执行dbscan算法,查询过程中,使用步骤5构造的k-d树查询每个聚类中数据对象的ε-邻域,输出dbscan算法的聚类结果;
步骤7,将步骤6中具有相同数据的聚类进行合并,输出聚类结果。
步骤2具体为:
首先为集群中每一个节点安装redhat6.2操作系统;然后为集群中每一个节点安装hadoop2.2.0文件,并为集群中每一个节点安装jdk1.8.0_65文件;配置集群中每个节点上的redhat6.2系统的.bashrc文件,使得redhat6.2系统关联该节点上的hadoop2.2.0文件和该节点上的jdk1.8.0_65文件;配置每个节点上hadoop2.2.0文件中的hadoop-env.sh文件、mapred-env.sh文件、yarn-env.sh文件、slaves文件、core-site.xml文件、hdfs-site.xml文件、mapred-site.xml文件和yarn-site.xml文件。
步骤4的具体步骤为:
步骤4.1,确定中心点集合;
步骤4.2,根据中心点集合将待聚类数据集a中的数据进行聚类。
步骤4.1的具体步骤为:
步骤4.1.1,启动第一个map任务,扫描并读入待聚类数据集a中的数据;
步骤4.1.2,初始化一个中心点集合key1,令key1为空;对每次读入的数据,如果key1为空,则将读入的数据添加到key1中;如果key1不为空,采用公式(1)计算读入的数据到key1中的中心点的距离dist1:
dist1=dist(di,dj)=|xi1-xj2|+|xi2-xj2|+…+|xip-xjp|(1)
其中,di为待聚类数据集a中的第i个数据,di=(xi1,xi2,…,xip),xi1,xi2,…,xip为di的p个数值属性,dj为key1中的第j个中心点,dj=(xj1,xj2,…,xjp),xj1,xj2,…,xjp为dj的p个数值属性,dist(di,dj)表示di到dj的曼哈顿距离;
步骤4.1.3,如果对于di,存在dj使得dist(di,dj)<t1,则将di添加到key1中,更新并输出key1;其中,t1是设定的初始距离阈值;
步骤4.1.4,启动第一个reduce任务,读入第一个map任务输出的key1中的数据;初始化一个中心点集合key2,令key2为空,对每次读入的数据,如果key2为空,则将读入的数据添加到key2中;如果key2不为空,使用公式(1)计算读入的数据到key2中的中心点的距离dist2,如果存在中心点使得dist2<t1,将本次读入的数据添加到key2中,更新并输出key2。
步骤4.2的具体步骤为:
步骤4.2.1,启动第二个map任务,读入待聚类集a中的数据和第一个reduce任务输出的key2中的数据;
步骤4.2.2,采用公式(1)计算待聚类集a中的数据到key2中的中心点的距离dist3;
步骤4.2.3,如果存在key2中的中心点使得dist3<t2,该中心点和与之距离小于t2的待聚类数据构成集合b,输出集合b;其中,t2是设定的初始距离阈值;
步骤4.2.4,启动第二个reduce任务,读入第二个map任务输出的若干个集合b,将具有相同中心点的集合b中不等于中心点的数据添加到同一个聚类中,输出聚类(key,list);其中,key表示一个中心点,list表示同一聚类中除key之外的所有数据。
步骤5具体为:启动第三个map任务,读入第二个reduce任务输出的聚类,每次读入一个聚类,在该聚类的数据上构造k-d树。
步骤7的具体步骤为:
步骤7.1,启动第四个map任务,读入步骤6输出的聚类;
步骤7.2,初始化一个集合c,每次读入一个聚类并添加到集合c中;判断每次读入的聚类是否与集合c中的聚类有相同的数据,如果是,将与读入的聚类有相同数据的聚类从集合c中取出,并与读入的聚类进行合并,将合并后的聚类去掉重复数据后添加到集合c中;
步骤7.3,按步骤7.2处理完读入到第四个map任务中的所有聚类后,输出集合c;
步骤7.4,启动第四个reduce任务,读入步骤7.3输出的集合c中的聚类;初始化一个集合d,每次读入一个聚类并添加到集合d中,判断读入的聚类是否与集合d中的聚类有相同的数据,如果是,将与本次读入的聚类有相同数据的聚类从集合d中取出,并与本次读入的聚类进行合并,将合并后的聚类去掉重复数据后添加到集合d中;
步骤7.5,按步骤7.4处理完读入到第四个reduce任务中的所有聚类后,输出集合d,即为聚类结果。
本发明的有益效果是,本发明hadoop平台下的c-dbscan-k聚类算法,首先,使用canopy聚类算法,快速的得到粗粒度的聚类结果;然后,在粗粒度的聚类结果上构造k-d树数据结构,并执行dbscan算法,使用k-d树查询对象的ε-邻域范围,加快了dbscan的运行速度;最后,合并具有相同对象的聚类,得到最终的聚类结果。hadoop平台下的c-dbscan-k聚类算法在处理大数据集时快速有效,在保持聚类准确度不降低的情况下,显著的提高了dbscan算法的执行效率。
附图说明
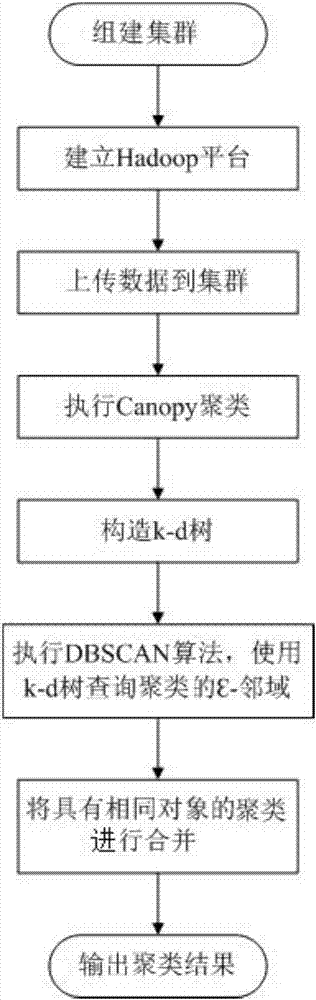
图1是hadoop平台下的c-dbscan-k聚类算法的流程图;
图2是hadoop平台下的c-dbscan-k聚类算法与dbscan算法的聚类结果比较图;
图3是hadoop平台下的c-dbscan-k聚类算法与dbscan算法的执行时间比较图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
如图1所示,hadoop平台下的c-dbscan-k聚类算法,包括以下步骤:
步骤1,将多台计算机连接到同一局域网中,每台计算机作为一个节点,建立能够相互通信的集群;
步骤2,为集群建立hadoop平台;
步骤2具体为:首先为集群中每一个节点安装redhat6.2操作系统;然后为集群中每一个节点安装hadoop2.2.0文件,并为集群中每一个节点安装jdk1.8.0_65文件;配置集群中每个节点上的redhat6.2系统的.bashrc文件,使得redhat6.2系统关联该节点上的hadoop2.2.0文件和该节点上的jdk1.8.0_65文件;配置每个节点上hadoop2.2.0文件中的hadoop-env.sh文件、mapred-env.sh文件、yarn-env.sh文件、slaves文件、core-site.xml文件、hdfs-site.xml文件、mapred-site.xml文件和yarn-site.xml文件。
步骤3,使用hadoop分布式文件命令dfs–put将待聚类数据集a上传至hadoop分布式文件系统;
步骤4,执行canopy聚类算法对待聚类数据集a中的数据进行初始聚类,得到粗粒度的聚类结果;
步骤4的具体步骤为:
步骤4.1,确定中心点集合;
步骤4.1的具体步骤为:
步骤4.1.1,启动第一个map任务,扫描并读入待聚类数据集a中的数据;
步骤4.1.2,初始化一个中心点集合key1,令key1为空;对每次读入的数据,如果key1为空,则将读入的数据添加到key1中;如果key1不为空,采用公式(1)计算读入的数据到key1中的中心点的距离dist1:
dist1=dist(di,dj)=|xi1-xj2|+|xi2-xj2|+…+|xip-xjp|(1)
其中,di为待聚类数据集a中的第i个数据,di=(xi1,xi2,…,xip),xi1,xi2,…,xip为di的p个数值属性,dj为key1中的第j个中心点,dj=(xj1,xj2,…,xjp),xj1,xj2,…,xjp为dj的p个数值属性,dist(di,dj)表示di到dj的曼哈顿距离;
步骤4.1.3,如果对于di,存在dj使得dist(di,dj)<t1,则将di添加到key1中,更新并输出key1;其中,t1是设定的初始距离阈值;
步骤4.1.4,启动第一个reduce任务,读入第一个map任务输出的key1中的数据;初始化一个中心点集合key2,令key2为空,对每次读入的数据,如果key2为空,则将读入的数据添加到key2中;如果key2不为空,使用公式(1)计算读入的数据到key2中的中心点的距离dist2,如果存在中心点使得dist2<t1,将本次读入的数据添加到key2中,更新并输出key2。
步骤4.2,根据中心点集合key2将待聚类数据集a中的数据进行聚类。
步骤4.2的具体步骤为:
步骤4.2.1,启动第二个map任务,读入待聚类集a中的数据和第一个reduce任务输出的key2中的数据;
步骤4.2.2,采用公式(1)计算待聚类集a中的数据到key2中的中心点的距离dist3;
步骤4.2.3,如果存在key2中的中心点使得dist3<t2,该中心点和与之距离小于t2的待聚类数据构成集合b,输出集合b;其中,t2是设定的初始距离阈值;
步骤4.2.4,启动第二个reduce任务,读入第二个map任务输出的若干个集合b,将具有相同中心点的集合b中不等于中心点的数据添加到同一个聚类中,输出聚类(key,list);其中,key表示一个中心点,list表示同一聚类中除key之外的所有数据。
步骤5,在步骤4得到的聚类上构造k-d树;
步骤5具体为:启动第三个map任务,读入第二个reduce任务输出的聚类,每次读入一个聚类,在该聚类的数据上构造k-d树。
步骤6,对步骤4得到的聚类执行dbscan算法,查询过程中,使用步骤5构造的k-d树查询每个聚类中数据对象的ε-邻域,输出dbscan算法的聚类结果;
步骤7,将步骤6中具有相同数据的聚类进行合并,输出聚类结果。
步骤7的具体步骤为:
步骤7.1,启动第四个map任务,读入步骤6输出的聚类;
步骤7.2,初始化一个集合c,每次读入一个聚类并添加到集合c中;判断读入的聚类是否与集合c中的聚类有相同的数据,如果是,将与本次读入的聚类有相同数据的聚类从集合c中取出,并与本次读入的聚类进行合并,将合并后的聚类去掉重复数据后添加到集合c中;
步骤7.3,按步骤7.2处理完读入到第四个map任务中的所有聚类后,输出集合c;
步骤7.4,启动第四个reduce任务,读入步骤7.3输出的集合c中的聚类;初始化一个集合d,每次读入一个聚类并添加到集合d中,判断每次读入的聚类是否与集合d中的聚类有相同的数据,如果是,将与读入的聚类有相同数据的聚类从集合d中取出,并与读入的聚类进行合并,将合并后的聚类去掉重复数据后添加到集合d中;
步骤7.5,按步骤7.4处理完读入到第四个reduce任务中的所有聚类后,输出集合d,即为聚类结果。
以r语言包生成的四组模拟数据集:face数据集、spirals数据集、cassini数据集、hypercube数据集分别作为待聚类数据集为例,分别采用hadoop平台下的c-dbscan-k聚类算法与dbscan算法对4个数据集中的数据进行聚类;图2(a)、图2(b)为hadoop平台下的c-dbscan-k聚类算法与dbscan算法在face数据集上的运行结果,图2(c)、图2(d)为hadoop平台下的c-dbscan-k聚类算法与dbscan算法在spirals数据集上的运行结果,图2(e)、图2(f)为hadoop平台下的c-dbscan-k聚类算法与dbscan算法在cassini数据集上的运行结果,图2(g)、图2(h)为hadoop平台下的c-dbscan-k聚类算法与dbscan算法在hypercube数据集上的运行结果;图2中的矩形框代表噪声点,其他不同灰度的形状代表不同的聚类,由图2可以得出:hadoop平台下的c-dbscan-k聚类算法与dbscan算法在各个数据集上生成的聚类是相同的,并且识别出的噪声点也是相同的,即两种算法的准确率相同。
如图3所示,hadoop平台下的c-dbscan-k聚类算法与dbscan算法对对包含120k条数据的face数据集、包含150k条数据spirals数据集、包含180k条数据cassini数据集、包含200k条数据hypercube数据集进行聚类时,hadoop平台下的c-dbscan-k聚类算法均比dbscan算法运行时间短,hadoop平台下的c-dbscan-k聚类算法有更高的执行效率。
综上所述,本发明hadoop平台下的c-dbscan-k聚类算法,首先,使用canopy聚类算法,快速的得到粗粒度的聚类结果;然后,在粗粒度的聚类结果上构造k-d树数据结构,并执行dbscan算法,使用k-d树查询对象的ε-邻域范围,加快了dbscan的运行速度;最后,合并具有相同对象的聚类,得到最终的聚类结果。hadoop平台下的c-dbscan-k聚类算法在处理大数据集时快速有效,在保持聚类准确度不降低的情况下,显著的提高了dbscan算法的执行效率。
- 还没有人留言评论。精彩留言会获得点赞!