一种基于时间衰减的相关搜索词挖掘方法及系统与流程
本发明涉及计算机及其信息检索领域,具体涉及一种基于时间衰减的相关搜索词挖掘方法及系统。
背景技术:
随着计算机技术的不断发展,信息的获取变得极为容易,人们仅需要通过搜索引擎就能查询到自己想要的信息;常用的搜索方式为通过在搜索栏中输入关键词进行搜索,并且会推荐给用户与关键词对应的热搜词。
但是信息检索的过程中,用户搜索了某个关键词,然后通过浏览发现没有合适的链接,经常需要变换查询再重新搜索。很多情况下,用户并不确定需要重新如何进行搜索才能找到目标文档,因此,现有技术中,开发了“相关搜索”功能,通过用户当前搜索词和整站内部的所有搜索行为,可以“推荐”给用户更合适与搜索词相对应的频繁项集。
现有技术的不足之处在于,推荐的频繁项集存在较多的噪音,使推荐的频繁项集过于繁多,人员仍然无法很好的确定相关搜索词;在用户的搜索过程中,时间距离太久远的相关搜索词和最近、最热门的相关搜索词将被以相同的权重呈现给人员,导致人员无法迅速找到想要的相关搜索词。
技术实现要素:
本发明的目的是提供一种基于时间衰减的相关搜索词挖掘方法及系统,以解决上述不足之处。
为了实现上述目的,本发明提供如下技术方案:
一种基于时间衰减的相关搜索词挖掘方法,其特征在于,包括以下步骤:
根据输入的搜索词关联得到频繁项集;
对所述频繁项集进行支持度和置信度的计算,并根据所述计算结果和设定的阈值进行所述频繁项集的过滤;
通过时间衰减函数对过滤后的频繁项集进行累加,得到相关搜索词。
上述相关搜索词挖掘方法,所述频繁项集的获得包括以下步骤:
定义历史搜索日志中的频繁项的粒度;定义为(a)或(a、b);
输入搜索词,并据其在所述历史搜索日志中搜寻相应的频繁项;
将多个所述频繁项归为所述频繁项集。
上述相关搜索词挖掘方法,所述支持度的计算包括以下步骤:
遍历所述频繁项集,获取一项频繁项集和二项频繁项集;
进行所述一项频繁项集和二项频繁项集的支持度计算,计算公式为:支持度=一项或二项项集数/总项集数。
上述相关搜索词挖掘方法,所述置信度的计算包括以下步骤:
计算获得一项频繁项集和二项频繁项集的支持度;
根据所述支持度进行所述一项频繁项集和二项频繁项集的置信度计算,计算公式为:置信度=二项频繁项集支持度/一项频繁项集支持度。
上述相关搜索词挖掘方法,进行所述频繁项集的过滤包括以下步骤:
设定支持度阈值和置信度阈值;
根据所述支持度阈值对所述支持度进行判断,过滤低于所述支持度阈值的频繁项;
根据所述置信度阈值对所述置信度进行判断,过滤低于所述置信度阈值的频繁项。
上述相关搜索词挖掘方法,所述相关搜索词的获得包括以下步骤:
通过半衰期时间衰减函数对过滤后的频繁项集的权重进行衰减处理;
半衰期函数为:m=m*(1/2)^(t/t);其中,m为初始值,m为过一段时间后的值,t为时间跨度,t为半衰期。
对处理结果进行累加,得到相关搜索词。
本发明提供的一种基于时间衰减的相关搜索词挖掘方法,实现以下有益效果:
1)通过搜索词关联到相关词的频繁项集,具有更简单、更快速的效果;
2)通过支持度、置信度对推荐的频繁项集中的噪音进行过滤,使推荐的频繁项集过得到简化,人员可以较为容易的确定相关搜索词;
3)通过时间衰减函数降低时间距离太久远的相关搜索词的权重,相对的升高了最近、最热门的相关搜索词的权重,使人员可以迅速找到想要的相关搜索词。
本发明实施例还提供一种基于时间衰减的相关搜索词挖掘系统,包括:
关联单元,用以根据输入的搜索词关联得到频繁项集;
计算过滤单元,用以对所述频繁项集进行支持度和置信度的计算,并根据所述计算结果和设定的阈值进行所述频繁项集的过滤;
时间衰减单元,用以通过时间衰减函数对过滤后的频繁项集进行累加,得到相关搜索词。
上述相关搜索词挖掘系统,还包括输入单元,用以输入所述搜索词,或对所述搜索词进行相关变换。
上述相关搜索词挖掘系统,所述设定的阈值为设定的支持度阈值和置信度阈值。
上述相关搜索词挖掘系统,所述时间衰减单元包括:衰减模块和累加模块,
所述衰减模块,用以通过半衰期时间衰减函数对过滤后的频繁项集的权重进行衰减处理;
所述累加模块,对处理结果进行累加,得到相关搜索词。
本发明提供的一种基于时间衰减的相关搜索词挖掘系统,实现以下有益效果:
1)通过关联单元关联到相关词的频繁项集,具有更简单、更快速的效果;
2)通过计算过滤单元对推荐的频繁项集中的噪音进行过滤,使推荐的频繁项集过得到简化,人员可以较为容易的确定相关搜索词;
3)通过时间衰减单元降低时间距离太久远的相关搜索词的权重,相对的升高了最近、最热门的相关搜索词的权重,使人员可以迅速找到想要的相关搜索词。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的相关搜索词挖掘方法的流程示意图;
图2为本发明一优选实施例提供的相关搜索词挖掘方法的流程示意图;
图3为本发明一优选实施例提供的相关搜索词挖掘方法的流程示意图;
图4为本发明一优选实施例提供的相关搜索词挖掘方法的流程示意图;
图5为本发明一优选实施例提供的相关搜索词挖掘方法的流程示意图;
图6为本发明一优选实施例提供的相关搜索词挖掘方法的流程示意图;
图7为本发明实施例提供的相关搜索词挖掘系统的结构示意图。
图8为本发明一优选实施例提供的相关搜索词挖掘系统的结构示意图;
图9为本发明一优选实施例提供的相关搜索词挖掘系统的结构示意图;
图10为本发明实施例提供的以30天为半衰期的时间衰减函数图。
附图标记说明:
10、关联单元;20、计算过滤单元;30、时间衰减单元;301、衰减模块;302、累加模块;40、输入单元。
具体实施方式
为了使本领域的技术人员更好地理解本发明的技术方案,下面将结合附图对本发明作进一步的详细介绍。
如图1所示,为本发明实施例提供的一种基于时间衰减的相关搜索词挖掘方法,包括以下步骤:
s101、根据输入的搜索词关联得到频繁项集;
搜索词为通过搜索栏输入的需要搜索的关键词。频繁项集是指在同一个搜索词下,共同出现的相关词的集合,其可以为一项或者两项。关联是指基于搜索词在历史搜索日志中搜寻到频繁项。用户带着某个特定的意图进行查询时,可能会在同一个session中进行多次查询变换,通过累积全站用户的session内共现的搜索词,我们可以挖掘出相关的(具有某一定联系)的查询query。与普通的频繁项集挖掘不同,相关词的频繁项集更简单也更快速。
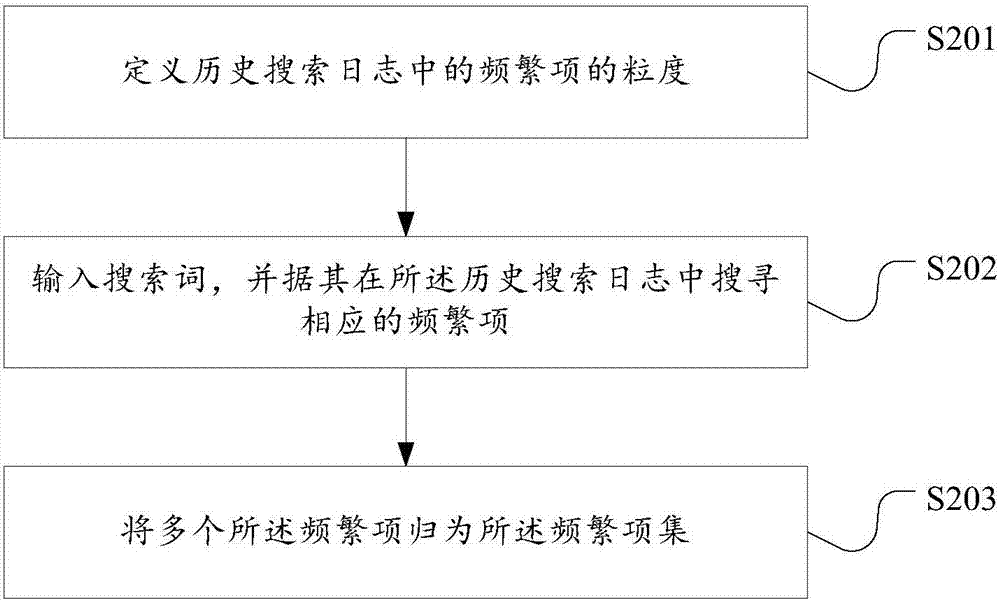
如图2所示,在步骤s101中,所述频繁项集的获得包括以下步骤:
s201、定义历史搜索日志中的频繁项的粒度;定义为(a)或(a、b);
历史搜索日志为通过累积全站用户的session内共现的搜索词而得来,其由多个频繁项组成,每个频繁项至少具有关键词a本身,或者为具有关键词a本身和相关词b的小项;即通过定义可以实现每个频繁项包含的规则关系粒度均小于等于1,比如“啤酒”“尿布”->“牛奶”的频繁项将不会在历史搜索日志中出现。但在相关搜索词挖掘中,仅考虑粒度只有1的规则关系。
s202、输入搜索词,并据其在所述历史搜索日志中搜寻相应的频繁项;
具体而言,输入一个搜索词“啤酒”,从历史搜索日志中搜寻到包含“啤酒”的频繁项,比如:“(啤酒、鲜花),(啤酒),(啤酒、尿布),(啤酒、牛奶)”等。
s203、将多个所述频繁项归为所述频繁项集。
将上述的频繁项归为同一个集合,得到频繁项集;比如通过上述频繁项得到:{(啤酒、鲜花),(啤酒),(啤酒、尿布),(啤酒、牛奶)}的集合。
s102、对所述频繁项集进行支持度和置信度的计算,并根据所述计算结果和设定的阈值进行所述频繁项集的过滤;
如图3所示,在步骤s102中,所述支持度的计算包括以下步骤:
s301、遍历所述频繁项集,获取一项频繁项集和二项频繁项集;
s302、进行所述一项频繁项集和二项频繁项集的支持度计算;
计算公式为:支持度=一项或二项项集数/总项集数。频繁项集的挖掘包含两个指标:支持度表示数据集中包含该项集的记录所占的比例。如5条频繁项集中包含3条啤酒的频繁项,则啤酒的支持度是3/5;如5条频繁项集中包含2条“啤酒”“尿布”同时存在的频繁项,则(啤酒,尿布)的支持度为2/5。
如图4所示,在步骤s102中,所述置信度的计算包括以下步骤:
s401、计算获得一项频繁项集和二项频繁项集的支持度;
s402、根据所述支持度进行所述一项频繁项集和二项频繁项集的置信度计算;
计算公式为:置信度=二项频繁项集支持度/一项频繁项集支持度。根据步骤s301、s302中得到的支持度进行置信度的计算;置信度是针对某条关联规则来定义的,在本发明实施例中,“啤酒”->“尿布”的置信度为支持度(啤酒,尿布)/支持度(啤酒)=2/3。
如图5所示,在步骤s102中,进行所述频繁项集的过滤包括以下步骤:
s501、设定支持度阈值和置信度阈值;
s502、根据所述支持度阈值对所述支持度进行判断,过滤低于所述支持度阈值的频繁项;
s503、根据所述置信度阈值对所述置信度进行判断,过滤低于所述置信度阈值的频繁项。
通过设置包含两项的项集支持度阈值,可以过滤掉两项频数出现过少的项集;进一步的,包含两项的项集没有被过滤掉留下来的,它们内部的仅包含一项的项集支持度必然满足支持度阈值。通过设置置信度的阈值,可以过滤掉关联规则关系不够强的频繁项集中的频繁项。
s103、通过时间衰减函数对过滤后的频繁项集进行累加,得到相关搜索词。
如图6所示,在步骤s103中,所述相关搜索词的获得包括以下步骤:
s601、通过半衰期时间衰减函数对过滤后的频繁项集的权重进行衰减处理;
半衰期函数为:m=m*(1/2)^(t/t);其中,m为初始值,m为过一段时间后的值,t为时间跨度,t为半衰期。
s602、对处理结果进行累加,得到相关搜索词。
历史挖掘的相关搜索词能够为现在提供参考价值,但时间越长远,所能参考的意义就越低。越近的时间挖掘的相关搜索词越有参考意义,越能反映当下的舆论热点、搜索热点。这并意味着历史挖掘的结果就再无价值,我们可以通过时间衰减的方式,将历史挖掘的相关搜索词以较低权重迭代累加至最新的挖掘结果中。
以30天为半衰期,可以获得如图10所示的函数图形。
可以设定一个半衰期的时间长度,每日挖掘的相关搜索词对的权重都会按照半衰期进行衰减,然后累加到最新的过滤后的频繁项集中,因此越新的过滤后的频繁项集占的权重越大,越旧的过滤后的频繁项集占得权重越小,从而可以大幅度降低时间久远的频繁项集对相关搜索词的影响。
本发明提供的一种基于时间衰减的相关搜索词挖掘方法,实现以下有益效果:
1)通过搜索词关联到相关词的频繁项集,具有更简单、更快速的效果;
2)通过支持度、置信度对推荐的频繁项集中的噪音进行过滤,使推荐的频繁项集过得到简化,人员可以较为容易的确定相关搜索词;
3)通过时间衰减函数降低时间距离太久远的相关搜索词的权重,相对的升高了最近、最热门的相关搜索词的权重,使人员可以迅速找到想要的相关搜索词。
如图7-9所示,为本发明实施例提供的一种基于时间衰减的相关搜索词挖掘系统,包括:关联单元10,用以根据输入的搜索词关联得到频繁项集;计算过滤单元20,用以对所述频繁项集进行支持度和置信度的计算,并根据所述计算结果和设定的阈值进行所述频繁项集的过滤;时间衰减单元30,用以通过时间衰减函数对过滤后的频繁项集进行累加,得到相关搜索词。作为本实施例中优选的,还包括输入单元40,用以输入所述搜索词,或对所述搜索词进行相关变换;人员可以在输入的搜索词关联出的相关词不符合时,再输入其他关键词进行搜索。作为本实施例中优选的,所述设定的阈值为设定的支持度阈值和置信度阈值,根据所述支持度阈值对所述支持度进行判断,过滤低于所述支持度阈值的频繁项;根据所述置信度阈值对所述置信度进行判断,过滤低于所述置信度阈值的频繁项。作为本实施例中优选的,所述时间衰减单元包括:衰减模块和累加模块,所述衰减模块,用以通过半衰期时间衰减函数对过滤后的频繁项集的权重进行衰减处理;所述累加模块,对处理结果进行累加,得到相关搜索词。半衰期函数为:m=m*(1/2)^(t/t);其中,m为初始值,m为过一段时间后的值,t为时间跨度,t为半衰期;将得到的相关搜索词受时间影响降低到最小。
本发明提供的一种基于时间衰减的相关搜索词挖掘系统,实现以下有益效果:
1)通过关联单元10关联到相关词的频繁项集,具有更简单、更快速的效果;
2)通过计算过滤单元20对推荐的频繁项集中的噪音进行过滤,使推荐的频繁项集过得到简化,人员可以较为容易的确定相关搜索词;
3)通过时间衰减单元30降低时间距离太久远的相关搜索词的权重,相对的升高了最近、最热门的相关搜索词的权重,使人员可以迅速找到想要的相关搜索词。
以上只通过说明的方式描述了本发明的某些示范性实施例,毋庸置疑,对于本领域的普通技术人员,在不偏离本发明的精神和范围的情况下,可以用各种不同的方式对所描述的实施例进行修正。因此,上述附图和描述在本质上是说明性的,不应理解为对本发明权利要求保护范围的限制。
- 还没有人留言评论。精彩留言会获得点赞!