基于深度学习的周界报警算法的制作方法
本发明属于安防技术中的视频监控领域,涉及模式识别、图形图像处理、视频分析等,利用深度学习算法实现周界报警。
背景技术:
传统周界报警方法和设备包括红外/激光/微波对射式、振动/泄露电缆式、张力围栏式、电子脉冲围栏式、振动光缆式等。红外/激光/微波对射式由发射装置和接收装置组成,发射装置发射红外线、激光或微波,当有目标入侵时,会阻断红外线、激光或微波,从而在接收装置上接收不到红外线、激光或微波。振动电缆式是利用驻极体振动电缆作为传感器,泄露电缆式利用泄露同轴电缆作为传感器,张力围栏式采用强力拉紧探测光缆作为传感器,电子脉冲围栏式采用极低频率的脉冲高压对入侵者以警告,振动光缆式则是用入侵者的震动或压力等导致光线的相位变化来检测入侵。这些周界报警方法和设备受树叶、小动物的影响,或者受温度湿度、光线变化的影响,会产生大量的误报,而且有些对人体还有某种程度的伤害,所以,在安防系统中,如小区,这些周界报警设备基本都处于停用荒废的状态。
随着视频监控的发展,摄像头的普及,出现了基于视频分析的周界报警算法和产品,此类算法通常利用背景建模如多高斯模型来提取目标,然后判断目标是否破坏了预先设置的规则(虚拟围墙、绊线或入侵区域),从而触发报警。视频分析周界报警产品利用的是原有监控摄像头,造价低廉;不需要额外施工,布放方便;而且不存在射线、激光或高压脉冲等,对人体无害,因此,此类产品曾经风靡一时。但传统的视频分析周界报警由于受前景提取算法的限制,不能很好的对人、树叶、小动物及光线变化导致的背景变化进行区分,所以会产生大量的误报,如车灯扫过围栏,则很有可能导致误报。
基于传统视频分析的周界报警算法,采用的是“经验式”的算法理念,所以得根据现场调整很多参数,这种算法在推广中消耗大量的技术支持力量。
技术实现要素:
本发明为了解决基于视频分析的周界报警中误报多的问题,提供了基于深度学习的周界报警算法。利用深度学习在视频帧上对人体进行检测,将检测到的人体作为候选目标,判断是否触发了周界报警的规则。基于深度学习的目标检测算法,能准确的区分人、树叶、小动物和光线变化等,因此,本发明中基于深度学习的周界报警算法将误报降到了百分之一以内,深度学习采用统一的训练框架,从大量的样本中学习模型,规避了传统视频分析的“经验式”模型,因此本发明中的算法参数极少,很适合推广应用。
本发明提供的基于深度学习的周界报警算法,包括:
从视频连续帧中提取前景。这里假设背景是相对静止的,前景是运动的,所以可以对背景进里模型。然后把符合背景模型的像素点判定为背景,不符合背景模型的像素点则判定为前景。
由于视频图像通常会有噪声扰动,提取出的前景图像通常也带有噪声,这些噪声常常是孤立的像素点,所以可以通过形态学滤波的方法滤除噪声点。形态学滤波过程是先进行腐蚀算子,再进行膨胀算子。
经过滤波后,用连通域标记算法将前景像素点连成一片区域,即连通域,用左上角坐标和区域宽高表示。在本发明中的连通域是4连通的,同时用8连通补充。连通域标记经过两步扫描:第一步是标记过程,即给每个像素点做标记;第二步是连通坐标过程,即通过连通关系得到区域的坐标。
连通域标记得到的区域,在本发明中称为感兴趣区域(roi),通过roi的坐标,从图像中截取出子图作为后续进行人体检测的图像。从原始输入图像中截取roi子图,采用从左到右,从上到下的流程,并且利用前景图像作为模板,这样可以去除候选目标周围的行人的干扰。
接下去在roi子图上进行深度学习的人体检测,将子图缩放到统一分辨率480x480的图像i,然后在i上利用卷积神经网络提取特征,将i划分为15x15个块,每个块上估计属于人体的概率和坐标,最终将大于一定阈值的块合并,形成人体检测的结果。人体检测的结果用中心坐标和宽高,以及概率表示。
通过人工标定物标出场景的景深信息,人工标定由五条不同位置不同景深的标线组成,通过这些标线计算整个场景的景深。然后根据人体检测的坐标和宽高,结合标定的景深信息,估计出人体的纵深信息,从而得到人体的三维坐标。
将人体的三维坐标输入周界报警的规则中,与周界的位置坐标相比较,判断该人是否闯入周界,如果闯入,则触发报警。
与传统的物理式周界报警设备相比,及基于传统视频分析的周界报警装置相比,本发明中基于深度学习的周界报警算法具有更高的准确率,接近零的误报率,极少的参数配置。
附图说明
图1是本发明基于深度学习的周界报警算法流程图。其中人工标定模块是需要用户参与标定过程。
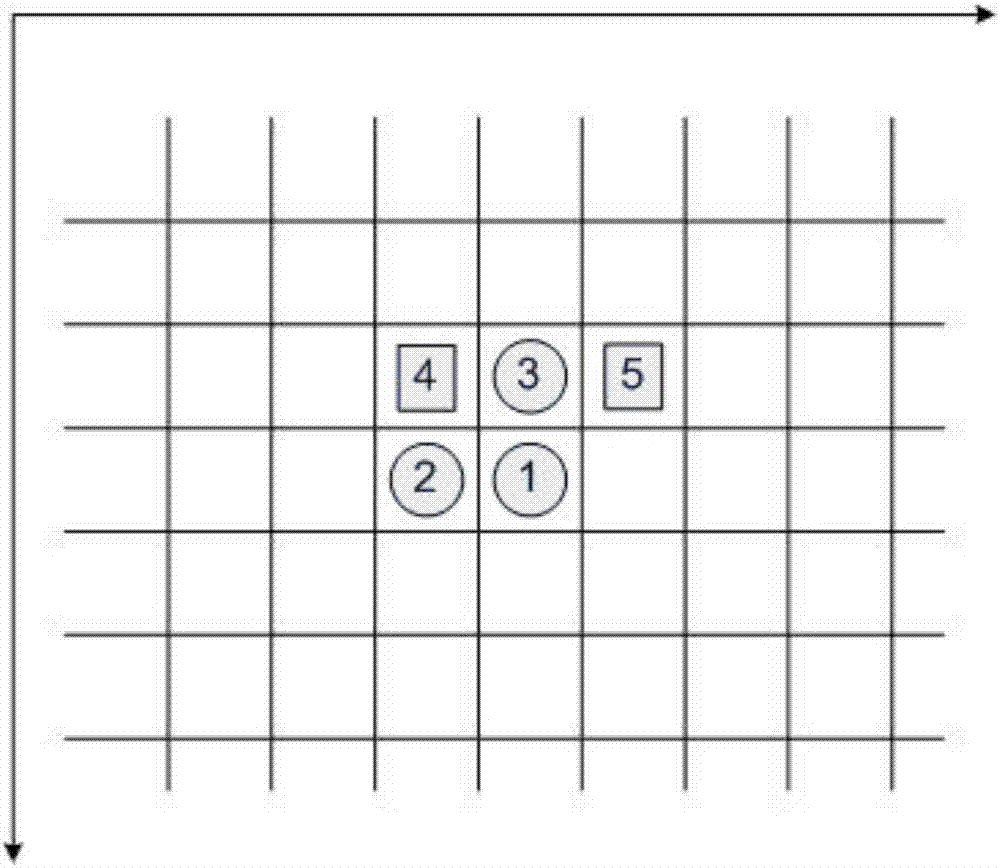
图2是连通域标记示意图。
图3是本方面神经网络各层说明示意图。
图4是人工标定景深的示意图。
具体实施方式
下面结合附图和具体实例对本发明进行进一步解释。应该指出的是,下文所描述的实例旨在更好的理解本发明,只是本发明中的一部分,并不因此而限制本发明的保护范围。
如图1所示,本发明实现由前景提取到报警联动等一系列步骤。
步骤101中,前景提取基于混合高斯背景模型,本发明认为图像中每个背景像素点服从多个高斯的混合模型,本发明设定高斯的个数是k,则若每个像素点的像素值用变量xt表示,则混合高斯模型可用下面的公式表示:
其中,gk(xt,μk,t,σk,t)表示t时刻的第k个高斯分量,其均值为μk,t,协方差矩阵为σk,t,ωk,t为第k个高斯分量在t时刻的权重,且有
上式中n表示xt的维数
本发明用一段没有运动目标的背景视频对上述的混合高斯模型进行训练,得到高斯模型的初始参数,然后在实时视频中通过在线更新的机制实时更新混合高斯的参数。
在提取前景时,凡是符合混合高斯模型的像素点则认为是背景点,否则认为是前景像素点。
步骤102中,本发明用腐蚀和膨胀算子来过滤噪声,腐蚀和膨胀都是图像进行卷积运算。采用的是3x3大小的核,这对于3x3以下的孤立的噪声点,能有效的滤除。
步骤103中,连通域标记是对检测出的前景点进行整体性的描述,通常使得处于同一物体上的前景点属于同一个连通域。如图2所示,设当前需要标记的像素点为1(前景点),它的已经标记过的邻点为4、3、5和2,标记过程如下:
(a)如果2和3都不是前景点。此时4是前景点,则将1标记为4的标记;此时4不是前景点,5是前景点,则1标记为5的标记;此时4和5都不是前景点,则1标记为新的连通域。
(b)如果2和3都为前景点,又如果2和3的标记相同,则将1标记为2或3的标记,如果2和3的标记不同,则将1标记与2的标记等同,并用另外的变量注明2和3的标记为等价的标记;
(c)如果2和3中只有一个为前景点,2是前景点,则将1标记为2的标记,3是前景点,则1标记为3的标记。
连通域标记后初步建立当前帧侯选物体的基本参数,包括各个连通域的长度、宽度和中心点坐标。
步骤104,通过连通域的左上角坐标和连通域的宽高,从左到右,从上到下,截取出彩色yuv子图。该yuv子图里包含候选目标。
步骤105,如图3所示,本发明采用14个卷积层、4个池化层、3个全连接层的深度学习网络。卷积层采用7x7、5x5和3x3的卷积核。池化层采用2x2的窗口,以一层一层减少特征空间的大小。网络的参数训练先用标定类别的一百二十万张样本进行预训练,然后用监控场景中的人的图像进行训练,最后收敛后得到深度学习的网络参数。检测时,将子图缩放到统一分辨率480x480的图像i,然后利用深度学习网络提取特征,将i划分为15x15个块,每个块上估计属于人体的概率和坐标,最终将大于一定阈值的块合并,形成人体检测的结果。人体检测的结果用中心坐标和宽高,以及概率表示。
步骤106,如图4所示,在xy平面(地面)上5个不同的位置上设立标定物,可以让同一个人站在5个不同的位置作为标定物,图4中的401、402、403、404、405是同一个人在场景中由近及远、从左到右的5个不同位置的成像效果,由于近大远小,所以远处的人较小,通过这5个位置的标定,可以得到xy平面上任意一点的景深信息,即通过xz坐标(像平面上的坐标)估计得到y轴的坐标大小。
步骤107通过步骤106的标定结果,可以得到周界附近人的xyz三维坐标,然后在步骤108中判断是否触发了周界,并联动报警。
本发明采用的算法参数,从大量的样本中学习模型,规避了传统视频分析的“经验式”模型,因此本发明中的算法参数极少,在现场实施中很容易。
- 还没有人留言评论。精彩留言会获得点赞!