一种基于混合字典学习的人脸识别方法及装置与流程
本发明属于计算机技术领域,尤其涉及一种基于混合字典学习的人脸识别方法及装置。
背景技术:
人脸识别技拥有广阔的应用前景、巨大的社会效益和经济效益,一直是计算机视觉领域的一个研究热点。在现实环境中,人脸可能存在遮挡、光照、表情以及姿态的变化,导致现实环境中待识别的人脸图像与人脸识别数据库中人脸图像存在较大差异,人脸识别技术需要非常好的鲁棒性,才能在这种情形下依然能够准确地判别待识别人脸图像的身份。
近年来,字典学习被应用于人脸识别并且取得了较好的识别效果。yang等研究人员提出了fisher判别字典学习(fddl)的方法,学习得到的字典的元素对应于类别标签,重构残差和编码系数都采用了判别信息。由于fddl是类专用字典学习方法,其字典只包括类专用字典,而不包括类共享字典和干扰字典,同时,没有在类专用子字典之间采用判别信息,所以fddl学习得到的字典鲁棒性差,导致人脸识别精度较低。
kong等研究人员提出了包括类共享字典和类专用字典的混合字典学习方法(copar),copar的类专用子字典间引入了不相关罚项,类专用子字典被用来分类。由于copar是包括类共享字典和类专用字典的混合字典学习方法,而不包括干扰字典,同时,编码系数没有采用判别信息,所以copar学习得打的字典鲁棒性差,导致人脸识别精度较低。
deng等研究人员认为某个人的人脸的类内变化,比如遮挡、光照和表情变化,能被其他人的人脸的类内变化所共享,也就是某个人的人脸的类内变化可以近似表示为其他人的人脸的类内变化的稀疏线性组合,提出了扩展稀疏表示(esrc),esrc从一个和训练数据库不相关的人脸数据集中构造一个类内变化字典来表示训练图像和测试图像之间的变化。其中,干扰字典包括真实干扰字典和模拟干扰字典,类内变化字典属于真实干扰字典,可见esrc的字典只包括类专用字典和真实干扰字典,不包括类共享字典和模拟干扰字典,同时,编码系数和类专用子字典之间均没有采用判别信息,而且没有进行字典学习,所以esrc得到的字典鲁棒性差,导致人脸识别精度较低。
技术实现要素:
本发明的目的在于提供一种基于混合字典学习的人脸识别方法及装置,旨在解决现有技术中基于混合字典学习的人脸识别方法鲁棒性较差,导致人脸识别精度较低的问题。
一方面,本发明提供了一种基于混合字典学习的人脸识别方法,所述方法包括下述步骤:
接收输入的待识别人脸图像,提取所述待识别人脸图像的人脸特征;
计算所述人脸特征在训练好的混合字典上的编码系数,所述混合字典包括类共享字典、类专用字典、模拟干扰字典和真实干扰字典;
根据所述编码系数计算所述人脸特征在所述类专用字典的每个类专用子字典上的重构残差;
获取所述所有重构残差中最小的重构残差,根据所述最小的重构残差对应的所述类专用子字典的类别,确定所述待识别人脸图像的身份。
另一方面,本发明提供了一种基于混合字典学习的人脸识别装置,所述装置包括:
特征提取模块,用于接收输入的待识别人脸图像,提取所述待识别人脸图像的人脸特征;
系数计算模块,用于计算所述人脸特征在训练好的混合字典上的编码系数,所述混合字典包括类共享字典、类专用字典、模拟干扰字典和真实干扰字典;
残差计算模块,用于根据所述编码系数计算所述人脸特征在所述类专用字典的每个类专用子字典上的重构残差;以及
身份确定模块,用于获取所述所有重构残差中最小的重构残差,根据所述最小的重构残差对应的所述类专用子字典的类别,确定所述待识别人脸图像的身份。
本发明预先训练好包括类共享字典、类专用字典、模拟干扰字典和真实高干扰字典的混合字典,计算待识别人脸图像的人脸特征在该混合字典上的编码系数,根据该编码系数计算待识别人脸图像的人脸特征在类专用字典的每个类专用子字典上的重构残差,在所有重构残差中获取最小的重构残差,该最小的重构残差对应的类专用子字典的类别即待识别人脸图像的类别,继而可确定待识别人脸图像的身份,从而通过包括了类共享字典、类专用字典、真实干扰字典和模拟干扰字典的混合字典能够有效地对人脸图像进行表示,同时有效地提高了人脸识别的鲁棒性,此外,在字典学习模型的编码系数和混合字典间都采用了判别信息,进而有效地提高人脸识别的识别效率和准确率。
附图说明
图1是本发明实施例一提供的基于混合字典学习的人脸识别方法的实现流程图;
图2是本发明实施例二提供的基于混合字典学习的人脸识别方法中生成混合字典的实现流程图;
图3是本发明实施例三提供的基于混合字典学习的人脸识别装置的结构示意图;
图4是本发明实施例三提供的基于混合字典学习的人脸识别装置的优选结构示意图;以及
图5是本发明实施例三提供的基于混合字典学习的人脸识别装置与fddl、copap、esrc在标准人脸库ar上的人脸识别结果的实验示例图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
以下结合具体实施例对本发明的具体实现进行详细描述:
实施例一:
图1示出了本发明实施例一提供的基于混合字典学习的人脸识别方法的实现流程,为了便于说明,仅示出了与本发明实施例相关的部分,详述如下:
在步骤s101中,接收输入的待识别人脸图像,提取待识别人脸图像的人脸特征。
本发明实施例适用于人脸识别平台或系统,当接收到用户输入的待识别人脸图像时,通过预设的人脸特征提取算法提取待识别人脸图像的人脸特征,并通过特征向量矩阵表示该人脸特征。具体地,人脸特征提取算法可为sift(局部特征提取)算法、lbp(localbinarypatterns)算法等。
在步骤s102中,计算人脸特征在训练好的混合字典上的编码系数,混合字典包括类共享字典、类专用字典、模拟干扰字典和真实干扰字典。
在本发明实施例中,通过预设的字典学习模型训练得到混合字典,该混合字典包括类共享字典、类专用字典、模拟干扰字典和真实干扰字典,混合字典的生成过程可参照实施例二的各步骤。人脸特征在混合字典上的编码系数的计算公式为:
在步骤s103中,根据编码系数计算人脸特征在类专用字典的每个类专用子字典上的重构残差。
在本发明实施例中,每个类专用子字典对应着不同的类别,通过计算人脸特征在每个类专用子字典上的重构残差,以确定人脸特征所属的类别。具体地,重构残差的计算公式为:
在步骤s104中,获取所有重构残差中最小的重构残差,根据最小的重构残差对应的类专用子字典的类别,确定待识别人脸图像的身份。
在本发明实施例中,在所有计算得到的重构残差中获取数值最小的重构残差,该最小的重构残差所对应的类专用子字典的类别,即待识别人脸图像所属的类别,进而确定了待识别人脸图像的身份。
在本发明实施例中,通过包括了类共享字典、类专用字典、真实干扰字典和模拟干扰字典的混合字典,有效地对人脸图像进行表示,有效地提高了人脸识别的鲁棒性,此外,在字典学习模型的系数和混合字典间都采用了判别信息,有效地提高人脸识别的识别效率和准确率。
实施例二:
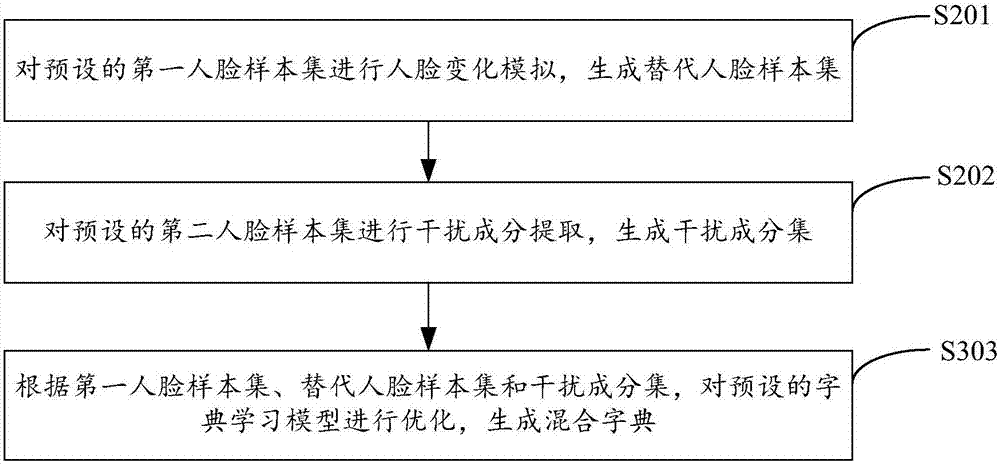
图2示出了本发明实施例二提供的基于混合字典学习的人脸识别方法中混合字典的生成流程,为了便于说明,仅示出了与本发明实施例相关的部分,详述如下:
在步骤s201中,对预设的第一人脸样本集进行人脸变化模拟,生成替代人脸样本集。
在本发明实施例中,第一人脸样本集为进行混合字典学习的训练样本集,第一人脸样本集中包括n个样本子集,n也第一人脸样本集中样本子集的类别数量,每个类别的样本子集可存储同一个人的不同人脸图像。为了得到对人脸遮挡、光照、表情和姿态变化鲁棒性的字典,将第一人脸样本集中的人脸样本进行人脸变化的模拟,由变化后的人脸样本构成替代人脸样本集。作为示例地,第一人脸样本集可表示为a=[a1,a2,…,an]∈rd×s,替代人脸样本集可表示为z=[z1,z2,…,zn]∈rd×s,其中,ai为第一人脸样本集中第i类样本子集,
优选地,可通过采用随机正方形对第一人脸样本集中人脸样本进行遮挡、或通过对第一人脸样本图像进行椒盐噪声污染、或通过对第一人脸样本集中的人脸样本进行镜像变化,实现对第一人脸样本集中人脸样本的人脸变化模拟,多方面地模拟人脸的变化。
在步骤s202中,对预设的第二人脸样本集进行干扰成分提取,生成干扰成分集。
在本发明实施例中,可通过预设的矩阵低秩分解方式提取第二人脸样本集中的干扰成分,干扰成分可包括噪声、野点、光照和遮挡等,从而实现人脸真实变化的提取。具体地,第二人脸样本集中样本子集与第一人脸样本集中样本子集的类别不同,第二人脸样本集可表示为g=[g1,g2,…,gl]∈rd×t,
在步骤s203中,根据第一人脸样本集、替代人脸样本集和干扰成分集,对预设的字典学习模型进行优化,生成混合字典。
在本发明实施例中,混合字典d包括类共享字典dc、类专用字典[d1,d2,…,di,…,dn]和干扰字典,干扰字典包括模拟干扰字典db和真实干扰字典dp。设置第一人脸样本集在dc上的编码系数矩阵
在本发明实施例中,在所有重构残差中选择数值最小的重构残差,该最小的重构残差对应的类专用子字典的类别即待识别人脸图像所属的类别,进而可得到待识别人脸图像的身份。
在本发明实施例中,通过对第一训练人脸样本集进行人脸变化模拟和对第二人脸样本集进行人脸真实变化的提取,得到替代人脸样本集和干扰成分集,通过第一训练人脸样本集、替代人样本集和干扰成分集,优化字典学习模型,生成包括类共享字典、类专用字典、模拟干扰字典和真实干扰字典的混合字典,该混合字典能够有效地对人脸图像进行表示,从而有效地提高字典学习的鲁棒性,还在字典学习模型的系数和混合字典间都采用了判别信息,有效地提高人脸识别的识别效率和准确率。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于一计算机可读取存储介质中,所述的存储介质,如rom/ram、磁盘、光盘等。
实施例三:
图3示出了本发明实施例三提供的基于混合字典学习的人脸识别装置的结构,为了便于说明,仅示出了与本发明实施例相关的部分,其中包括:
特征提取模块31,用于接收输入的待识别人脸图像,提取待识别人脸图像的人脸特征。
在本发明实施例中,通过预设的人脸特征提取算法提取待识别人脸图像的人脸特征,并通过特征向量矩阵表示该人脸特征。
系数计算模块32,用于计算人脸特征在训练好的混合字典上的编码系数,混合字典包括类共享字典、类专用字典、模拟干扰字典和真实干扰字典。
在本发明实施例中,人脸特征在混合字典上的编码系数的计算公式为:
残差计算模块33,用于根据编码系数计算人脸特征在类专用字典的每个类专用子字典上的重构残差。
在本发明实施例中,每个类专用子字典对应着不同的类别,通过计算人脸特征在第一人脸样本集的每类样本子集上的重构残差,以确定人脸特征所属的类别。具体地,重构残差的计算公式为:
身份确定模块34,用于获取所有重构残差中最小的重构残差,根据最小的重构残差对应的类专用子字典的类别,确定待识别人脸图像的身份。
在本发明实施例中,在所有计算得到的重构残差中获取数值最小的重构残差,该最小的重构残差所对应的类专用子字典的类别,即待识别人脸图像所属的类别,进而确定了待识别人脸图像的身份。
优选地,如图4所示,基于混合字典学习的人脸识别装置还包括:
人脸变化模拟模块41,用于对预设的第一人脸样本集进行人脸变化模拟,生成替代人脸样本集。
在本发明实施例中,第一人脸样本集为进行混合字典学习的训练样本集,第一人脸样本集中包括n个样本子集,n也第一人脸样本集中样本子集的类别数量,每个类别的样本子集可存储同一个人的不同人脸图像。为了得到对人脸遮挡、光照、表情和姿态变化鲁棒性的字典,将第一人脸样本集中的人脸样本进行人脸变化的模拟,由变化后的人脸样本构成替代人脸样本集。作为示例地,第一人脸样本集可表示为a=[a1,a2,…,an]∈rd×s,替代人脸样本集可表示为z=[z1,z2,…,zn]∈rd×s,其中,ai为第一人脸样本集中第i类样本子集,
优选地,可通过采用随机正方形对第一人脸样本集中人脸样本进行遮挡、或通过对第一人脸样本图像进行椒盐噪声污染、或通过对第一人脸样本集中的人脸样本进行镜像变化,实现对第一人脸样本集中人脸样本的人脸变化模拟,多方面地模拟人脸的变化。
真实干扰提取模块42,用于对预设的第二人脸样本集进行干扰成分提取,生成干扰成分集。
在本发明实施例中,可通过预设的矩阵低秩分解方式提取第二人脸样本集中的干扰成分,干扰成分可包括噪声、野点、光照和遮挡等,从而实现人脸真实变化的提取。
具体地,第二人脸样本集中样本子集与第一人脸样本集中样本子集的类别不同,第二人脸样本集可表示为g=[g1,g2,…,gl]∈rd×t,
字典学习模块43,用于根据第一人脸样本集、替代人脸样本集和干扰成分集,对预设的字典学习模型进行优化,生成混合字典。
在本发明实施例中,设置第一人脸样本集在dc上的编码系数矩阵
优选地,真实干扰提取模块42包括:
分解提取模块421,用于通过预设的矩阵低秩分解方式对第二人脸样本集中每类样本子集进行干扰成分提取。
优选地,字典学习模块43包括:
字典模型优化模块431,用于根据第一人脸样本集、替代人脸样本集合和干扰成分集,通过交替迭代混合字典和字典学习模型中的编码系数矩阵,对字典学习模型进行迭代优化,生成混合字典。
作为示例地,在实验中,从标准人脸库ar中选取50个男性和50个女性,从100个人中随机选取90个人。从标准人脸库ar第1集中获取90个人中每个人的7幅具有光照和表情变化的图像,以用于训练,并从该标准人脸库ar第2集中获取该90个人中每人的13幅具有光照、遮挡和表情变化的图像,以用于测试,将用于训练的图像的镜像设置为替代训练样本,将字典学习模型中的标量常数λ1、λ2、λ3和λ4分别设置为0.001、0.005、0.05和0.0001,将编码系数的计算公式中的λ设置为0.001,将标准人脸库ar第1集中的100个人的剩余10个人,每人具有13幅光照、遮挡和表情变化的图像用于干扰成分的提取,图5示出了本发明实施例与fddl、copap、esrc在标准人脸库ar上的人脸识别结果。如图5所示,图5的训练时间为对字典学习模型进行离线训练的时间,识别时间为平均一幅图像的在线识别时间。可见,本发明实施例在实验中的识别精度明显高于fddl、copap和esrc,训练时间明显短于fddl和copap,esrc不存在训练时间,而识别时间和fddl、copap、esrc的识别时间都很短。
又如,还可在标准人脸库multi-pie、extendedyaleb等上进行实验,并将实验结果与fddl、copap、esrc的实验结果进行比较,同样可得出本发明实施例的识别精度较高、训练时间较短以及识别时间较短的比较结果。
在本发明实施例中,通过对第一训练人脸样本集进行人脸变化模拟和对第二人脸样本集进行人脸真实变化的提取,得到替代人脸样本集和干扰成分集,通过第一训练人脸样本集、替代人样本集和干扰成分集,优化字典学习模型,生成包括类共享字典、类专用字典、模拟干扰字典和真实干扰字典的混合字典,该混合字典能够有效地对人脸图像进行表示,从而有效地提高字典学习的鲁棒性,还在字典学习模型的系数和混合字典间都采用了判别信息,有效地提高人脸识别的识别效率和准确率。
在本发明实施例中,基于混合字典学习的人脸识别装置的各模块可由相应的硬件或软件模块实现,各模块可以为独立的软、硬件模块,也可以集成为一个软、硬件模块,在此不用以限制本发明。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!