一种基于方块拼接的任务调度方法与流程
本发明涉及任务调度
技术领域:
,特别涉及一种基于方块拼接的任务调度方法。
背景技术:
:任务调度的目标是分配任务集合到合适的处理器上,并决定任务在处理器上的执行顺序,既能满足任务之间的依赖关系,又可以使所有任务执行完的时间达到最小。一般的任务图的最优的任务调度是一个np-完全问题。因此,有效的调度算法对于分布式计算能获得好的加速比是非常重要的。但是,例如lte中的pdsch信号处理流程形成的任务图,这类任务图具有并行性高、实时性要求高、关键路径高度对称的特点,若采用随机搜索算法(蚁群算法、粒子群算法、遗传算法)进行任务调度则耗时太长,若采用基于任务复制算法进行任务调度,则算法复杂度过高,若采用表调度算法,由于表调度算法不能很好利用任务图自身具备的良好性质(并行性高)、且面对大量任务时不能充分利用多核平台,存在调度时间过长或核间通信量过大等问题。因此,需要一种适用于具有并行性高、实时性要求高、关键路径高度对称特点的任务图的任务调度方法。技术实现要素:本发明的目的在于:现有的任务调度方法在处理lte中的pdsch信号处理流程形成的任务图时所表现出的性能不佳的技术问题。为了实现上述发明目的,本发明提供了以下技术方案:一种基于方块拼接的任务调度方法,其包括以下步骤,步骤一:获取待处理的任务图,采用聚类算法将所述任务图划分成若干个子任务图;步骤二:采用四元组(n,h,w,m)参数化描述节点数目不超过4的子任务图;其中,n为节点数目,h为任务图最大深度,w为任务图最大并行节点数目,m为最大并行处深度;步骤三:分析各个子任务图对应的四元组(n,h,w,m),并以处理器间信息交互量最小和子任务图的任务调度长度最短为目标,产生各个子任务图所对应的方块组;步骤四:以并行节点数不超过处理器总数为条件,将所有子任务图对应的方块组拼接在一起,而得到所有可能的拼接方案;步骤五:采用评价函数评价每个拼接方案,并根据评分最高的拼接方案,确定最终的任务调度方案。根据一种具体的实施方式,本发明基于方块拼接的任务调度方法的步骤一中,若划分后的子任务图的节点数目超过4个,则继续采用所述聚类算法对所述子任务图进行划分,直到所有子任务图的节点数目均不超过4个。进一步地,采用聚类算法对所述任务图划分时,以子任务图之间的节点信息交互总量最小为目标。根据一种具体的实施方式,本发明基于方块拼接的任务调度方法中,评价函数表示为,score=n-a*htop-b*haverage-c*dn其中,n表示初始值,htop表示所有处理器中,负载最大的处理器的任务负载量,haverage表示每个处理器的平均任务负载量,dn表示第n个拼接方案中的节点紧密度,a,b,c为正整数。进一步地,根据拼接方案中每个执行周期内空闲处理器的数目之和,确定所述拼接方案的节点紧密度。与现有技术相比,本发明的有益效果:1、本发明基于方块拼接的任务调度方法中,通过将任务图划分为节点数目不超过四个的子任务图,并采用四元组(n,h,w,m)参数化描述每个子任务图,再通过分析各个子任务图对应的四元组(n,h,w,m),以处理器间信息交互量最小以及总任务调度长度最短为目标,产生相应的方块组,然后以并行节点数目不超过处理器总数目为条件,将所有子任务图对应的方块组拼接在一起,而得到所有可能的拼接方案,最后采用评价函数评价每个拼接方案,并根据评分最高的拼接方案,确定最终的任务调度方案。因此,本发明能够有效减小任务调度过程中处理器间产生的信息交互量以及总任务调度长度,提高处理器的任务处理的效率。2、本发明基于方块拼接的任务调度方法中,采用聚类算法对任务图划分时,以子任务图之间的节点信息交互总量最小为目标,如此,能够使划分后的每个子任务图中各节点间的信息交互量更大,由于每个子任务图中其节点间信息交互量更大,当进行处理器映射时,每个子任务图的节点将有更大的概率被分配在同一个处理器上,从而降低处理器间的信息交互量。附图说明:图1为本发明方法的流程图;图2为包括t1~t134节点的任务图;图3为子任务图{t85,t88}和{t1,t14,t25,t38}所对应的方块组;图4为子任务图{t64,t87,t96,t104}所对应的方块组;图5a和图5b分别为图2所示任务图的部分子任务图的拼接方案示意图;图6为本发明方法与hlfet算法、ish算法、etf算法和dls算法的性能对比图。具体实施方式下面结合试验例及具体实施方式对本发明作进一步的详细描述。但不应将此理解为本发明上述主题的范围仅限于以下的实施例,凡基于本
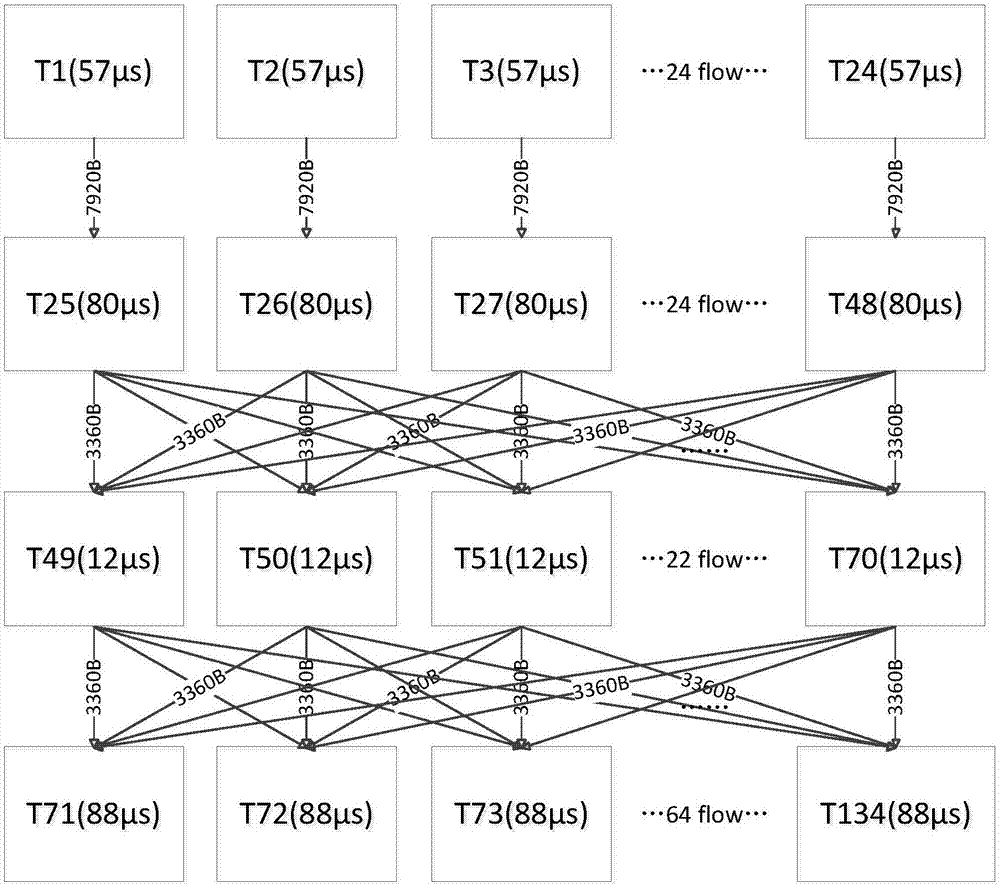
发明内容所实现的技术均属于本发明的范围。结合图1所示的本发明方法的流程图;本发明基于方块拼接的任务调度方法,其包括以下步骤,步骤一:获取待处理的任务图,采用聚类算法将所述任务图划分成若干个子任务图。具体的,若划分后的子任务图的节点数目超过4个,则继续采用聚类算法对节点数目超过4个的子任务图进行划分,直到所有子任务图的节点数目均不超过4个。在实施时,采用聚类算法对任务图划分时,以子任务图之间的节点信息交互总量最小为目标。如此,能够使拆分后的每个子任务图中各节点间的信息交互量更大,由于每个子任务图中其节点间信息交互量更大,当进行处理器映射时,每个子任务图中有大信息量交互的节点对将有更大的概率被分配在同一个处理器上,从而降低处理器间的信息交互量。步骤二:采用四元组(n,h,w,m)参数化描述节点数目不超过4的子任务图;其中,n为节点数目,h为任务图最大深度,w为任务图最大并行节点数目,m为最大并行处深度。步骤三:分析各个子任务图对应的四元组(n,h,w,m),并以处理器间信息交互量最小和子任务图的任务调度长度最短为目标,产生各个子任务图相应的方块组。步骤四:以并行节点数不超过处理器总数为条件,将所有子任务图对应的方块组拼接在一起,而得到所有可能的拼接方案。具体的,拼接方块组就如同俄罗斯方块中拼接不同形状的落子一样,将所有的方块组拼接在一起后,由方块组之间的位置关系确定拼接方案。步骤五:采用评价函数评价每个拼接方案,并根据评分值最高的拼接方案,确定最终的任务调度方案。由于任务调度方案的目的是为了提高任务的处理效率,因此,需要以处理器的任务负载均衡为目标,所以,需要采用评价函数评价每个拼接方案,来确定一个评分最高的拼接方案,从而根据该拼接方案,得到最终的任务调度方案。具体的,本发明基于方块拼接的任务调度方法中的评价函数表示为,score=n-a*htop-b*haverage-c*dn其中,n表示初始值,htop表示所有处理器中,负载最大的处理器的任务负载量,haverage表示每个处理器的平均任务负载量,dn表示第n个拼接方案中的节点紧密度,a,b,c为正整数。在实施时,根据拼接方案中每个执行周期内空闲处理器的数目之和,确定所述拼接方案的节点紧密度。以图2所示的具有134个节点t1~t134的任务图为例,应用本发明基于方块拼接的任务调度方法处理该任务图。第一步,采用聚类算法对该任务图进行划分,由于在划分时,聚类算法以划分后,每个子任务图间节点信息交互总量最小为目标。因此,在划分之前,根据图2所示的任务图,统计每个节点与其他各个节点的信息交互量,而在划分时,只需要将节点间信息交互量总量最大的节点划分在同一子任务图中。同时,在划分时,需要保证每个子任务图的节点数目不超过4个。因此,采用聚类算法对图2所示的任务图进行划分,得到64个子任务图,采用集合表示为:{{t85,t88},{t1,t14,t25,t38},{t9,t33},{t78,t81,t90,t107},{t13,t37},{t21,t45},{t2,t16,t26,t40},{t6,t30},{t7,t31},{t56},{t24,t48},{t63,t82},{t10,t34},{t44},{t84},{t8},{t2},{t22,t46},{t8,t32},{t15,t39},{t124},{t4,t18,t28,t42},{t89,t119},{t12,t36},{t3,t17,t27,t41},{t11,t35},{t19,t23,t43,t47},{t49,t62},{t5,t29},{t98,t101},{t12},{t76,t11},{t69,t103,t106,t129},{t93},{t117},{t111},{t94,t102,t121,t130},{t112},{t59,t66},{t64,t87,t96,t104},{t114},{t51},{t58,t7},{t52},{t53,t65},{t79},{t57,t132},{t92},{t83,t126},{t61,t73},{t74},{t75},{t95},{t115,t122},{t68,t113,t116,t134},{t67,t71,t97,t100},{91,99},{t60,t72,t108,t123},{t105,t118},{t77},{t127},{t50,t55,t86,t125},{t133},{t54,t109,t128,t131}}。当然,本发明通过聚类算法对任务图划分所得到的结果是存在偏差的,但仍在可控范围内。第二步,采用四元组(n,h,w,m)参数化描述第一部中得到的64个子任务图。其中,n为节点数目,h为任务图最大深度,w为任务图最大并行节点数目,m为最大并行处深度。具体的,仅以第一步中的前两个子任务图{t85,t88},{t1,t14,t25,t38}为例,在子任务图{t85,t88}中,节点数目为2,根据图2所示的任务图可知,节点t85与节点t88并行,那么,任务图最大深度为1,任务图最大并行节点数目为2,最大并行处深度为1。因此,子任务图{t85,t88}的四元组描述为{(2,1,2,1)}。而在子任务图{t1,t14,t25,t38}中,节点数目为4,根据图2所示的任务图可知,节点t25与节点t38并行,节点t1与节点t14并行,那么,任务图最大深度为2,任务图最大并行节点数目为2,同时,由于两组并行节点数目均为2,节点t1和节点t14的深度为1,而节点t25和节点t38的深度为2。而为确定描述方式,在这种情形下,设定最大并行处深度为0,因此,子任务图{t1,t14,t25,t38}的四元组描述为{(4,2,2,0)}。第三步,根据第二步中得到的各个子任务图的所对应的四元组,并以处理器间信息交互量最小和子任务图的任务调度长度最短为目标,产生各个子任务图所对应的方块组。具体的,仍以子任务图{t85,t88},{t1,t14,t25,t38}为例,子任务图{t85,t88}所对应的四元组为{(2,1,2,1)},子任务图{t1,t14,t25,t38}所对应的四元组为{(4,2,2,0)}。根据子任务图{t85,t88}所对应的四元组{(2,1,2,1)},由于节点t85与节点t88并行,因此得到如图3所示的方块组a和方块组b,不过在任务调度中,方块组a和方块组b是等效的,表示节点t85和节点t88由两个不同的处理器并行处理。根据子任务图{t1,t14,t25,t38}所对应的四元组为{(4,2,2,0)},由于节点t25与节点t38并行,节点t1与节点t14并行,且任务图最大深度为2,任务图最大并行节点数目为2,因此得到如图3中所示的方块组c和方块组d,方块组c表示节点t25和节点t38由两个不同的处理器并行处理,节点t1和节点t14由两个不同的处理器并行处理,且t25和节点t1由同一个的处理器处理,t38和节点t14由同一个的处理器处理。而方块组d表示节点t25和节点t38由两个不同的处理器并行处理,节点t1和节点t14由两个不同的处理器并行处理,且t25和节点t14由同一个的处理器处理,t38和节点t1由同一个的处理器处理。所以,方块组c和方块组d不等效。由此可见,根据四元组产生的方块组可能存在多个。因此,为了降低处理器间的通信量和提高调度效率,根据子任务图的四元组,产生方块组时,需要以处理器间信息交互量最小和子任务图的任务调度长度最短为目标,来产生子任务图对应的方块组。以图3所示的方块组c和方块组d为例,根据图2所示的任务图可知,节点t1与节点t25有信息交互且信息交互量为7920b,节点t14与节点t38有信息交互且信息交互量为7920b,节点t1与节点t38无信息交互,节点t14与节点t25无信息交互,由于节点t1和节点t14的任务处理时间为57μs,节点t25和节点t38的任务处理时间为80μs。那么,在方块组c中,节点t1和t25由一个处理器处理,节点14和节点38由另一个处理器处理,因此,方块组c的处理器间信息交互量为0,而且由于信息交互均发生在处理器内部,这部分的延时均可忽略不计,对总体调度长度不产生影响,所以,方块组c的任务调度长度为137μs。而在方块组d中,节点t14和t25由一个处理器处理,节点1和节点38由另一个处理器处理,而且,由于节点t1与节点t25的信息交互量为7920b,节点t14与节点t38的信息交互量为7920b,那么,这两个处理器之间信息交互量为15840b。同时,由于方块组d的处理器间存在信息交互,不能忽略这部分信息交互对任务调度长度的影响,所以,方块组d的任务调度长度为137μs+(7920*)2/bps,bps表示处理器带宽。因此,以处理器间信息交互量最小和子任务图的任务调度长度最短为目标的话,最终产生的方块组应当是方块组c。但是,在实施时产生方块组的过程中还有可能出现的其他情形。例如以子任务图{t64,t87,t96,t104}为例,根据图2所示的任务图可知,其四元组描述为{(4,2,3,2)},其可能产生的方块组如图4所示的方块组e,方块组f和方块组g。按照以上方法,先考虑处理器间的交互量以及子任务图的任务调度长度,进一步根据图2所示的任务图可知,节点t87,t96和t104并行,且分别与节点t64间均有信息交互,同时信息交互量均为3360b,所以方块组e,方块组f和方块组g中处理器间的信息交互量均为6720b。而考虑子任务图的任务调度长度,由于节点t64的任务调度长度为12μs,节点t87,t96和t104均为88μs并行,所以方块组e,方块组f和方块组g总的任务调度长度均为100μs+(6720b/bps)。因此,在这种情形下,最终产生的方块组由后续评价函数确定。第四步,以并行节点数不超过处理器总数为条件,将所有子任务图对应的方块组拼接在一起,而得到所有可能的拼接方案,即遍历所有方块组的拼接的情形。如图5a和图5b所示的部分子任务图的拼接方案示意图,本领域技术人员能够根据已公开的内容,得到所有可能的完整的拼接方案。第五步,仅以图5a和图5b分别所示的部分子任务图的拼接方案为例,并设定评价函数score=n-a*htop-b*haverage-c*dn中的n=200,a=2,b=3,c=4,则二者的评价值score计算如下表所示:htophaveragednscore图5a43.51177.5图5b63.84160.6因此,使用评价函数对图5a与图5b两种拼接方案进行比较时,应该选用图5a的拼接方式。如图2所示的任务图,为对pdsch信号处理流程的任务抽象,对该任务图应用本发明基于方块拼接的任务调度方法、hlfet算法、ish算法、etf算法和dls算法进行任务调度,同时进行性能仿真比较。仿真使用windows7操作系统、matlab2014b,映射的对象是n×n规模的2dmesh结构的noc平台。其中任务在ip上的运算时间只与任务量的大小相关。同时,设ip核主频100mhz,处理位宽为64位,则带宽为800m,将图3中的信息传递量转换为与信息处理时间相当的微秒(μs)级别的信息传递时间。仿真结束后,得到如图6所示的性能对比图。在对lte中的pdsch信号处理流程形成的任务图时,本发明基于方块拼接的任务调度方法,处理任务图的总任务调度长度比hlfet算法少39.8%,比ish算法少41.9%,比etf算法少46.0%,比dls算法少65.8%。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1