一种非高峰时段多列车运行节能优化方法与流程
本发明属于列车运行控制技术领域,特别是一种非高峰时段多列车运行节能优化方法。
背景技术:
近年来,随着我国社会经济的快速发展和城市化进度的不断推进,城市地铁发展也相当迅速,由此带来的城市轨道交通能耗也越来越大。如何在满足列车准点运行的基础上,更加有效地提高能源利用率,降低运营成本,对我国的铁路事业发展有重大意义。
列车节能运行控制是一个典型的多目标多约束的优化控制问题,很难确立精确的数学模型来描述列车运行过程。传统的数学方法,如数值解析法、最优控制理论等,难以获取到模型的精确解,即使采用迭代方法也只能求得模型的近似解,且容易陷入局部最优。目前处理列车节能多目标多约束优化问题的方法,主要是通过多个优化目标加权,将多目标转化为单目标进行优化,然而这类方法在加权系数上需要依靠大量的经验积累,且容易造成局部优化,只能得到一组解,且优化速度慢。
技术实现要素:
本发明的目的在于提出一种收敛速度快、准确性高的非高峰时段多列车运行节能优化方法。
实现该发明目的的技术解决方案为:一种非高峰时段多列车运行节能优化方法,包括以下步骤:
步骤1,设置列车运行基本数据及pareto算法参数,包括非高峰多列车运行的线路数据、列车数据、运营数据和pareto多目标遗传算法的基本参数;
步骤2,构建非高峰时段多列车能耗计算模型;
步骤3,以停站时间的压缩值为优化变量,以节能指标和准时指标为优化目标,以单向总运行时间和停站时间变化范围为约束条件,建立非高峰时段多列车优化模型;
步骤4,基于pareto多目标遗传算法来求解非高峰时段多列车节能优化模型,得到一组非支配解集;
步骤5,提取最优解,从而得出优化后的时刻表,完成非高峰时段多列车节能优化模型的求解。
进一步地,步骤1中所述的线路数据,包括坡道起止公里标及对应坡度i、曲线段起止公里标及对应曲率c,限速段起止公里标及对应限速vt;所述的列车数据,包括列车的编组方式、长度l、载荷等级aw、戴维斯方程系数(a,b,c)、最大加速度amax、最大速度vmax、牵引特性曲线f(v)和制动特性曲线b(v);所述的pareto多目标遗传算法的基本参数,包括选择算子、交叉算子、变异算子、最大进化代数、种群大小和适应度函数。
进一步地,步骤2中所述的构建非高峰时段多列车能耗计算模型,具体如下:
步骤2.1、根据列车运行区段工况转折点,分区间进行列车的牵引能耗计算,根据列车前一个仿真步长运行至当前仿真步长的公里标s(t),得到当前仿真步长内列车的坡度i、曲率c;
步骤2.2、根据前一个仿真步长列车的速度v(t)、能耗e(t),计算出当前仿真步长内列车的牵引力f(v)、制动力b(v)和阻力参数f;
步骤2.3、根据列车的工况和受力分析,计算出当前时间t列车的加速度a(t)、牵引功率p(t),进而计算出下一个仿真步长内的速度v(t+δt)、公里标s(t+δt)、牵引功率p(t+δt),以及牵引能耗e(t+δt),δt为仿真步长时间。
进一步地,步骤3中所述的非高峰时段多列车优化模型,具体如下:
ldi≤g2(x)=dn≤udi(4)
式中f1(x)为与节能指标相关的目标函数,f(t),b(t)分别为t时刻标列车的牵引力和制动力;η为利用相邻列车再生制动能量率;e0(i)为列车在区间i原计划的能耗值;t0,tf分别为列车运行时刻和结束时刻;k,k-1分别为车站数和列车运行区间数;f2(x)为与准时指标相关的目标函数,δdi为车站i的停站时间压缩值;ti为车站i的计划运行时间;g1(x)为与总运行时间相关的约束条件,g2(x)为与停站时间相关的约束条件,ldi和udi分别为最小停站时间和最大停站时间。
进一步地,步骤4中所述的基于pareto多目标遗传算法来求解非高峰时段多列车节能优化模型,得到一组非支配解集,具体如下:
步骤4.1、种群初始化:初始化种群p,种群大小为n,种群中每个个体对应一组停站时间压缩值矩阵xi=[δd1,δd2,...δdj,...,δdk],k表示车站数,时刻表以秒为最小单位,故采用整数编码;
步骤4.2、节能指标f1(x)和准时指标f2(x)适应度值计算:首先根据种群中每个个体对应的停站时间压缩值矩阵δdi,计算出种群中每个个体对应的准时指标f2(x)适应度值与各区间新的运行时间和停站时间;然后将新的运行时间代入单列车定时节能优化模型中,求出非高峰时段单向全程多列车运行的总牵引能耗,并求出节能指标f1(x);
步骤4.3、对种群中的个体进行非支配排序,计算个体的拥挤度:首先将种群中每个个体的节能指标f1(x)和准时指标f2(x)适应度值进行非支配排序,确定种群中每个个体的排序号irank,然后对非支配层中的每个个体进行拥挤度计算,确定种群中非支配次序关系以及个体的拥挤度;
步骤4.4、使用锦标赛法选择精英个体,产生子代种群:根据种群中非支配次序关系以及个体的拥挤度,使用锦标赛法从种群p中随机选择个体进行交叉和变异操作,产生子代种群q;
步骤4.5、新一代父代种群生成:从第二代开始,首先将父代种群p与子代种群q合并,形成新种群r,种群大小为2n,其次进行非支配排序,确定种群中每个个体的irank值,然后对非支配层中每个个体进行拥挤度计算,根据非支配次序关系以及个体的拥挤度选取个体组成下一代父代种群p,保持种群个体数为n;
步骤4.6、循环步骤4.2~4.5直至达到最大迭代次数,停止遗传操作并保存得到pareto最优的非支配解集。
进一步地,步骤5中所述的提取最优解,从而得出优化后的时刻表,完成非高峰时段多列车节能优化模型的求解,具体为:通过提取全局最优解,在pareto非支配解集中,按制定的节能和准时的相对重要性,选择最合适的停站时间压缩矩阵作为全局最优解,求出优化后区间运行时间和各站停站时间,从而得出优化后的时刻表,完成非高峰时段多列车节能优化模型的求解。
本发明与现有技术相比,其显著优点为:(1)基于pareto多目标遗传算法的列车定时节能运行方法,在搜索过程中不易陷入局部最优,进化结果不局限于单值解,非常适合求解复杂的多目标问题;(2)通过选择、交叉、变异操作来表现复杂现象,充分利用适应值函数而不需要其它先验知识,收敛速度快、准确性高。
下面结合附图对本发明作进一步详细描述。
附图说明
图1为本发明非高峰时段多列车运行节能方法的流程示意图。
图2为本发明非高峰时段多列车节能优化模型求解流程图。
图3为本发明中多目标pareto前沿的非支配最优解集图。
图4为本发明中pareto多目标遗传算法每代选取的全局最优解能耗指标变化图。
图5为本发明中pareto多目标遗传算法每代选取的全局最优解准时指标变化图。
图6为优化后每辆列车在各区间牵引能耗图。
图7为优化后的列车运行图。
具体实施方式
结合图1,本发明非高峰时段多列车运行节能优化方法,包括以下步骤:
步骤1,设置列车运行基本数据及pareto算法参数,包括非高峰多列车运行的线路数据、列车数据、运营数据和pareto多目标遗传算法的基本参数;
步骤2,构建非高峰时段多列车能耗计算模型;
步骤3,以停站时间的压缩值为优化变量,以节能指标和准时指标为优化目标,以单向总运行时间和停站时间变化范围为约束条件,建立非高峰时段多列车优化模型;
步骤4,基于pareto多目标遗传算法来求解非高峰时段多列车节能优化模型,得到一组非支配解集;
步骤5,提取最优解,从而得出优化后的时刻表,完成非高峰时段多列车节能优化模型的求解。
进一步地,步骤1中所述的线路数据,包括坡道起止公里标及对应坡度i、曲线段起止公里标及对应曲率c,限速段起止公里标及对应限速vt;所述的列车数据,包括列车的编组方式、长度l、载荷等级aw、戴维斯方程系数(a,b,c)、最大加速度amax、最大速度vmax、牵引特性曲线f(v)和制动特性曲线b(v);所述的pareto多目标遗传算法的基本参数,包括选择算子、交叉算子、变异算子、最大进化代数、种群大小和适应度函数。
进一步地,步骤2中所述的构建非高峰时段多列车能耗计算模型,具体如下:
步骤2.1、根据列车运行区段工况转折点,分区间进行列车的牵引能耗计算,根据列车前一个仿真步长运行至当前仿真步长的公里标s(t),得到当前仿真步长内列车的坡度i、曲率c;
步骤2.2、根据前一个仿真步长列车的速度v(t)、能耗e(t),计算出当前仿真步长内列车的牵引力f(v)、制动力b(v)和阻力参数f;
步骤2.3、根据列车的工况和受力分析,计算出当前时间t列车的加速度a(t)、牵引功率p(t),进而计算出下一个仿真步长内的速度v(t+δt)、公里标s(t+δt)、牵引功率p(t+δt),以及牵引能耗e(t+δt),δt为仿真步长时间。
进一步地,步骤3中所述的非高峰时段多列车优化模型,具体如下:
ldi≤g2(x)=dn≤udi(4)
式中f1(x)为与节能指标相关的目标函数,f(t),b(t)分别为t时刻标列车的牵引力和制动力;η为利用相邻列车再生制动能量率;e0(i)为列车在区间i原计划的能耗值;t0,tf分别为列车运行时刻和结束时刻;k,k-1分别为车站数和列车运行区间数;f2(x)为与准时指标相关的目标函数,δdi为车站i的停站时间压缩值;ti为车站i的计划运行时间;g1(x)为与总运行时间相关的约束条件,g2(x)为与停站时间相关的约束条件,ldi和udi分别为最小停站时间和最大停站时间。
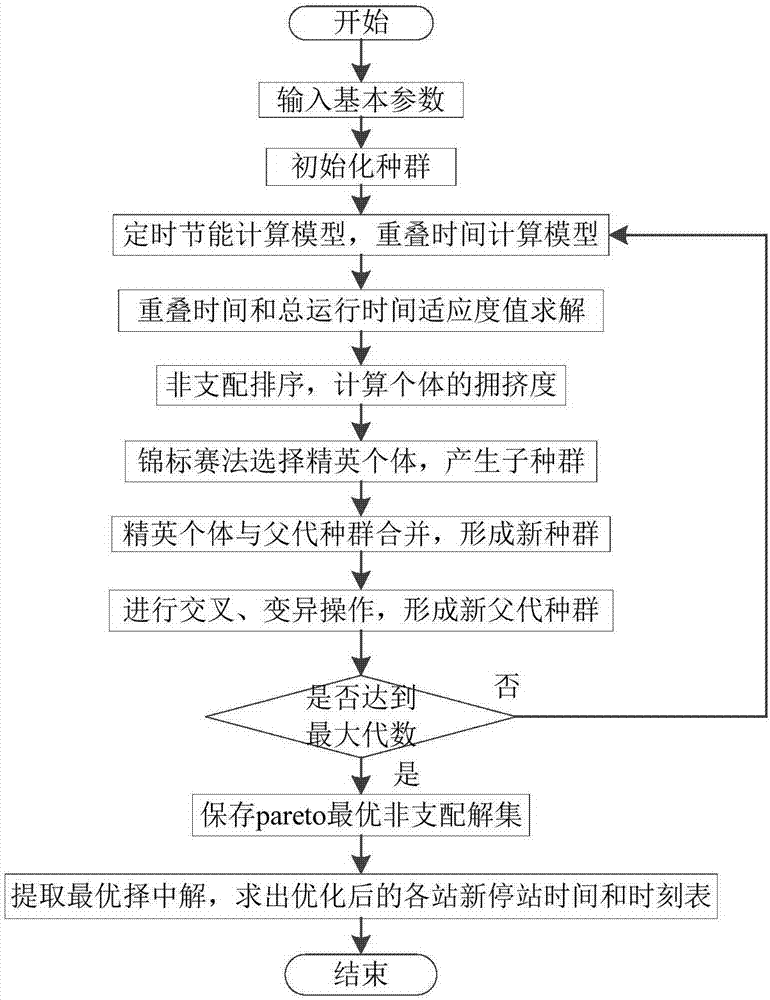
进一步地,步骤4中所述的基于pareto多目标遗传算法来求解非高峰时段多列车节能优化模型,得到一组非支配解集,结合图2,具体如下:
步骤4.1、种群初始化:初始化种群p,种群大小为n,种群中每个个体对应一组停站时间压缩值矩阵xi=[δd1,δd2,...δdj,...,δdk],k表示车站数,时刻表以秒为最小单位,故采用整数编码;
步骤4.2、节能指标f1(x)和准时指标f2(x)适应度值计算:首先根据种群中每个个体对应的停站时间压缩值矩阵δdi,计算出种群中每个个体对应的准时指标f2(x)适应度值与各区间新的运行时间和停站时间;然后将新的运行时间代入单列车定时节能优化模型中,求出非高峰时段单向全程多列车运行的总牵引能耗,并求出节能指标f1(x);
步骤4.3、对种群中的个体进行非支配排序,计算个体的拥挤度:首先将种群中每个个体的节能指标f1(x)和准时指标f2(x)适应度值进行非支配排序,确定种群中每个个体的排序号irank,然后对非支配层中的每个个体进行拥挤度计算,确定种群中非支配次序关系以及个体的拥挤度;
步骤4.4、使用锦标赛法选择精英个体,产生子代种群:根据种群中非支配次序关系以及个体的拥挤度,使用锦标赛法从种群p中随机选择个体进行交叉和变异操作,产生子代种群q;
步骤4.5、新一代父代种群生成:从第二代开始,首先将父代种群p与子代种群q合并,形成新种群r,种群大小为2n,其次进行非支配排序,确定种群中每个个体的irank值,然后对非支配层中每个个体进行拥挤度计算,根据非支配次序关系以及个体的拥挤度选取个体组成下一代父代种群p,保持种群个体数为n;
步骤4.6、循环步骤4.2~4.5直至达到最大迭代次数,停止遗传操作并保存得到pareto最优的非支配解集。
进一步地,步骤5中所述的提取最优解,从而得出优化后的时刻表,完成非高峰时段多列车节能优化模型的求解,具体为:通过提取全局最优解,在pareto非支配解集中,按制定的节能和准时的相对重要性,选择最合适的停站时间压缩矩阵作为全局最优解,求出优化后区间运行时间和各站停站时间,从而得出优化后的时刻表,完成非高峰时段多列车节能优化模型的求解。
实施例1
结合图1~7,本实施例非高峰时段多列车运行节能优化方法,以广州地铁七号线广州南站至大学城南站(上行方向)数据进行仿真分析,设置的仿真非高峰时段为:初期6:00至7:00,6:00至7:00初期计划的单位小时发车对数为6,上行方向单位小时发车数为6辆。如图1所示,包括以下步骤:
步骤1:设置列车运行基本数据及pareto算法参数,包括非高峰多列车运行的线路数据、列车数据、运营数据和遗传算法的基本参数,其中:线路数据,包括坡道起止公里标及对应坡度i、曲线段起止公里标及对应曲率c,限速段起止公里标及对应限速vt,;列车数据,包括列车的编组方式、长度l、载荷等级aw,戴维斯方程系数(a,b,c)、最大加速度amax、最大速度vmax、牵引特性曲线f(v)和制动特性曲线b(v);pareto多目标遗传算法基本参数,包括选择算子、交叉算子、变异算子、最大进化代数、种群大小和适应度函数;
步骤2:构建非高峰时段多列车能耗计算模型,具体为根据列车运行区段工况转折点,分区间进行列车的牵引能耗计算,首先根据列车前一个仿真步长运行至当前仿真步长的公里标s(t)得到对应该仿真步长内列车的坡度i、曲率c;其次根据前一个仿真步长列车的速度v(t)、能耗e(t),求出当前仿真步长内列车的牵引力f(v)、制动力b(v)和阻力参数f;最终根据列车的工况和受力分析,计算出当前时间t列车的加速度a(t)、牵引功率p(t),进而求出下一个仿真步长内的速度v(t+δt)、公里标s(t+δt)、牵引功率p(t+δt),以及牵引能耗e(t+δt),δt为仿真步长时间;
步骤3:以停站时间的压缩值为优化变量,以节能指标和准时指标为优化目标,以单向总运行时间和停站时间变化范围为约束条件,建立非高峰时段多列车优化模型,对非高峰运行时段的停站时间和区间运行时间进行合理优化。优化模型为:
ldi≤g2(x)=dn≤udi(4)
式中f1(x)为与节能指标相关的目标函数,f(t),b(t)分别为某时刻标列车的牵引力和制动力;η为利用相邻列车再生制动能量率;e0(i)为列车在区间i原计划的能耗值;t0,tf分别为列车运行和结束的时刻;k,k-1分别为车站数和列车运行区间数;f2(x)为与准时指标相关的目标函数,δdi为车站i的停站时间压缩值;ti为车站i的计划运行时间;g1(x)为与总运行时间相关的约束条件,g2(x)为与停站时间相关的约束条件,分别为最小停站时间和最大停站时间值;
步骤4:基于pareto多目标遗传算法来求解非高峰时段多列车节能优化模型,得到一组非支配解集,结合图2,具体步骤如下:
(1)种群初始化。初始化种群p,种群大小为n。种群中每个个体对应一组停站时间压缩值矩阵xi=[δd1,δd2,...δdj,...,δdk],k表示车站数。时刻表是以秒为最小单位,故采用整数编码;
(2)节能指标f1(x)和准时指标f2(x)适应度值计算。首先根据种群中每个个体对应的停站时间压缩值矩阵δdi,计算出种群中每个个体对应的准时指标f2(x)适应度值与各区间新的运行时间和停站时间;然后将新的运行时间代入单列车定时节能优化模型中,求出非高峰时段单向全程多列车运行的总牵引能耗,并求出节能指标f1(x);
(3)对种群中的个体进行非支配排序,计算个体的拥挤度。首先种群中每个个体的节能指标f1(x)和准时指标f2(x)适应度值进行非支配排序,确定种群中每个个体的irank值,然后对非支配层中的每个个体进行拥挤度计算,确定种群中非支配次序关系以及个体的拥挤度;
(4)锦标赛法选择精英个体,产生子代种群。根据种群中非支配次序关系以及个体的拥挤度,使用锦标赛法从种群p中随机选择个体进行交叉和变异操作,产生子代种群q;
(5)新一代父代种群生成。从第二代开始,首先将父代种群p与子代种群q合并,形成新种群r,种群大小为2n,其次进行非支配排序,确定种群中每个个体的irank值,然后对非支配层中每个个体进行拥挤度计算,根据非支配次序关系以及个体的拥挤度选取合适的个体组成下一代父代种群p,保持种群个体数为n;
(6)通过遗传算法的选择、交叉和变异操作产生新的子代种群,依此类推,直到满足结束条件,停止遗传操作,并保存pareto前沿的非支配解集。
步骤5:提取全局最优解,在pareto非支配解集中,按制定的节能和准时的相对重要性,选择最合适的停站时间压缩矩阵作为全局最优解,求出优化后区间运行时间和各站停站时间,从而得出优化后的时刻表,完成非高峰时段多列车节能优化模型的求解。
根据步骤1中的方法,本实施例线路广州地铁七号线是广州地铁2016年底开通的一条地铁线路,七号线第一期西起广州南站,东至大学城南站,全长17.5公里,均为地下线,其中七号线采购的列车为中国南车所提供的b型电力机车,该型车采用4动2拖的编组方式,每节动车厢配备4台牵引电机,共计16台牵引电机。该型车全长为118.32m。列车总质量既包括车厢的质量,还包括载客的质量。按照载客数量,将列车载重等级分为:aw0(空载)、aw1(座席载荷)、aw2(额定载荷)、aw3(超员载荷)四种等级。遗传算法的相关参数为种群大小为100,最大迭代次数30次,选择率0.9,交叉比率0.8,突变率0.005。
根据步骤3中的方法,设置总运行时间约束为1385s,停站时间上限值为60s,停站时间下限值中换乘车站和非换乘车站分别为30s和25s。
根据步骤4中的方法,得到pareto多目标遗传算法优化的种群中每代可行解集合中的选取的全局最优解的能耗指标与准时指标变化曲线,分别如图4和5所示。图中表明,30代个体中每代全局最优解的能耗指标在12.41kw.h与12.64kw.h之间波动,并趋近于12.47kw.h,而对应的准时指标在0s上下波动,并趋近于0s。
根据步骤5中的方法,得到在适应度空间上的非支配解分布图,即pareto前沿的分布,如图3所示。由图中可以看出列车能耗指标与准时指标近似成反比关系,表现为列车站间运行时间越长,能耗越大。但增加相同的运行时间并不会减少等量的能耗,具体表现为列车站间运行时间影响能耗变化的趋势逐渐降低。
根据步骤5中的方法,得到6:00至7:00优化后的列车运行图和牵引能耗图,分别为图6和图7。由于石壁、谢村和钟村三座车站的停站时间为停站时间的下限值,故其停站时间没有进行压缩,而其他6座车站的停站时间都进行相应压缩。优化后,列车到站时刻偏差为0s,故满足乘客对候车时间的需求。优化后的停站时间都在25s~60s之间,满足停站时间约束范围。优化前后,线路始终保持总运行时间为1385s不变,满足总运行时间不变的约束。总停站时间从295s下降至247s,共降低48s,区间运行时间从1090s提高至1138s,共提高了48s,占总运行时间的3.47%。每辆列车全程牵引能耗从206.9025kw.h下降到196.2072kw.h,最终牵引能耗下降了10.6953kw.h,牵引能耗的优化比例达5.17%。
- 还没有人留言评论。精彩留言会获得点赞!