一种基于云计算的风电大数据分析系统的制作方法
本发明涉及风电技术领域,特别是一种基于云计算的风电大数据分析系统。
背景技术:
风能作为一种清洁的可再生能源,已经受到全球性的广泛关注和高度重视。随着电力系统中风电装机容量的比重日益增大,每台风电机组的数据也日趋完善和丰富,这样,风电的集中监控系统,也面临着数据存储规模大、实时性、分析性强等挑战。实时、有效、准确的对风电基础数据分析,不仅可以从各方面对风机性能进行掌控,提高风机发电效率和设备利用率,还可以对风电的预测更加准确,从而,使管理人员可以提前做好调度准备,有助于电网消纳更多的风电。
对于集控侧的风机数据,其多样丰富和存储量大的特性,构成风电系统中独具特色的大数据,对于“大数据”,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。大数据技术的战略意义不在于掌握庞大的数据信息,而是对于这些含有意义的数据进行专业化处理。目前,国内集控系统从风电场侧采集的数据主要有:风机数据、升压站数据、电计量数据、测风塔数据等。风场侧通过数据采集装置和网络将数据传输到集控中心侧,集控中心侧部署数据存储服务器,将所有数据进行历史存储。现有技术关于风电数据的采集和存储系统的流程图如图1所示。
随着风电行业的迅猛发展,风机数据日趋丰富和完善,传统的数据存储系统和数据分析结构将面临巨大的压力和挑战。云计算是一种全新的大规模分布式计算模式,起源于互联网公司对大量计算与存储资源的需求以及对可伸缩性、高性能、高可用等特征的追求。云计算聚合了大量分布、异构的资源,向用户提供强大的海量数据存储与计算能力,云计算通过虚拟化、动态资源调配等技术向用户提供服务避免资源浪费与竞争,提高资源利用率以及应用性能。云计算提供横向伸缩和动态夫在均衡能力。云计算环境中的资源被组织为数据中心的形式,一个数据中心包含数千个甚至数万个节点,节点间通过高速网络互联,共同向用户提供计算和存储资源。
技术实现要素:
本发明的目的在于提供一种基于云计算的风电大数据分析系统,包括分布式文件系统模块,并行编程框架模块,数据仓库系统,监控工具,运行调度工具以及开发工具集合模块,其中所述分布式系统文件系统用于数据的持久化存储,所述监控工具用于监控系统的运行状态、数据分析作业的执行状态,所述运行调度工具根据需求对数据分析作业进行调度,解析作业间的关联或依赖关系,所述开发工具集合模块用于简化系统的配置管理。
优选的,所述分布式文件系统包括元数据服务器和多个数据服务器。
优选的,所述分布式文件系统的文件由数据块构成,数据块分布在不同的节点上,用于维持负载均衡。
优选的,所述并行编程框架模块采用谷歌公司的hadoop,基于map-reduce进行并行编程。
优选的,所述数据仓库模块采用基于hadoop平台的hive。
优选的,所述开发工具集合模块包括sql翻译、并行etl工具、索引管理和任务管理。
采用该基于云计算的风电大系统,可以提高风电数据分析挖掘速度,从而提高风电管理效率和风机设备利用率,进而提高发电量。在数据存储方面,构建起相对大规模的存储级别的相关系统,在设备利用方面,实现存储设备在线的有效收缩和扩展,在负载均衡方面,实现系统的全局性自动的均衡夫在,在数据安全方面,云存储实现整体数据的安全性与保护性。
根据下文结合附图对本发明具体实施例的详细描述,本领域技术人员将会更加明了本发明的上述以及其他目的、优点和特征。
附图说明
后文将参照附图以示例性而非限制性的方式详细描述本发明的一些具体实施例。附图中相同的附图标记标示了相同或类似的部件或部分。本领域技术人员应该理解,这些附图未必是按比例绘制的。本发明的目标及特征考虑到如下结合附图的描述将更加明显,附图中:
图1为现有技术风电数据的采集和存储系统的流程图;
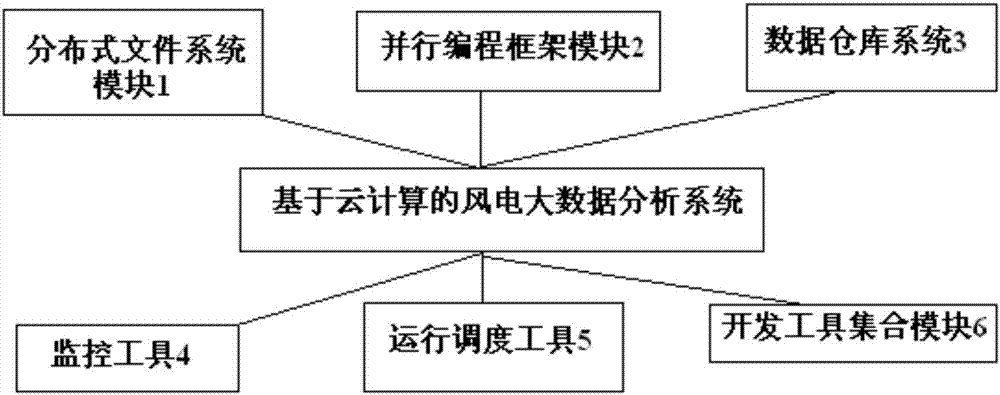
图2为根据本发明实施例的基于云计算的风电大数据分析系统框图;
附图3为根据本发明实施例的基于云计算的风电大数据分析系统的数据流程图。
具体实施方式
参见附图1,已经在背景技术部分说明了部分该流程图的内容,从风电场侧采集的数据主要有:风机数据、升压站数据、电计量数据、测风塔数据等,风场侧通过数据采集装置和网络将数据传输给集控中心侧,集控中心侧部署数据存储服务器,将所有数据进行历史存储。
参见附图2,一种基于云计算的风电大数据分析系统,包括分布式文件系统模块1,并行编程框架模块2,数据仓库系统3,监控工具4,运行调度工具5以及开发工具集合模块6,其中所述分布式系统文件系统1用于数据的持久化存储,所述监控工具4用于监控系统的运行状态、数据分析作业的执行状态,所述运行调度工具5根据需求对数据分析作业进行调度,解析作业间的关联或依赖关系,所述开发工具集合模块6用于简化系统的配置管理。分布式文件系统1包括元数据服务器1-1和多个数据服务器1-2。分布式文件系统1的文件由数据块构成,数据块分布在不同的节点上,用于维持负载均衡。并行编程框架模块2采用谷歌公司的hadoop,基于map-reduce进行并行编程。数据仓库系统3采用基于hadoop平台的hive。开发工具集合模块6包括sql翻译、并行etl工具、索引管理和任务管理。
参见附图3,风电大数据与互联网大数据存在明显区别,大多数大数据分析系统hive和impala等均未对索引提供良好支持,而风电大数据分析中,多维区域查询极为常见,由于没有索引,导致访问大量不需要的数据,显著降低查询的执行性能,需要设计合适的索引结构以及相应的数据检索机制,风电大数据业务场景中,存在大量的数据修改,以覆盖现有数据的方式执行会导致执行效率低下的问题,因此需提供效率较高的数据改写机制,互联网根据自身的业务而设计的hql只是sql的一个子集,并不完全适用于风电大数据分析系统。因此附图3展示的是一种新型的风电数据分析挖掘应用的数据流程图,更适应风电的应用。
采用该基于云计算的风电大系统,可以提高风电数据分析挖掘速度,从而提高风电管理效率和风机设备利用率,进而提高发电量。在数据存储方面,构建起相对大规模的存储级别的相关系统,在设备利用方面,实现存储设备在线的有效收缩和扩展,在负载均衡方面,实现系统的全局性自动的均衡夫在,在数据安全方面,云存储实现整体数据的安全性与保护性。
虽然本发明已经参考特定的说明性实施例进行了描述,但是不会受到这些实施例的限定而仅仅受到附加权利要求的限定。本领域技术人员应当理解可以在不偏离本发明的保护范围和精神的情况下对本发明的实施例能够进行改动和修改。
技术特征:
技术总结
本发明提供了一种基于云计算的风电大数据分析系统,包括分布式文件系统模块(1),并行编程框架模块(2),数据仓库系统(3),监控工具(4),运行调度工具(5)以及开发工具集合模块(6),其中分布式系统文件系统(1)用于数据的持久化存储,监控工具(4)用于监控系统的运行状态、数据分析作业的执行状态,运行调度工具(5)根据需求对数据分析作业进行调度,解析作业间的关联或依赖关系,开发工具集合模块(6)用于简化系统的配置管理。该系统提高风电数据分析挖掘速度,从而提高风电管理效率和风机设备利用率,进而提高发电量。
技术研发人员:不公告发明人
受保护的技术使用者:深圳市樊溪电子有限公司
技术研发日:2017.07.05
技术公布日:2017.11.10
- 还没有人留言评论。精彩留言会获得点赞!