一种基于人工智能算法的土体本构模型参数确定方法与流程
本发明涉及土体本构模型领域,具体涉及根据室内三轴试验数据确定土体本构模型参数的方法,用于解决土体本构模型参数取定困难的问题。
背景技术:
土体本构模型参数一般根据常规三轴试验确定,试样加载应力路径如图7,即首先对土体试样施加初始固结压力σ3,待试样固结稳定后,再施加剪切偏应力δσ1进行剪切,量测剪切过程中试样的应变和体积变化,并绘制典型三轴试验曲线如图8。在常规三轴试验中,第一主应变为轴向应变即ε1=εa,体积应变εv=ε1+2ε3。
当前土工试验数据整理过程通用方法是在获得三轴试验数据后,根据不同模型提出者建议的方法进行人工本构模型参数确定,由于土工试验自身的复杂性和离散性,人工整理试验参数在试验点选取、参数拟合方面有一定的人为经验因素,不同技术人员确定的模型指标往往有不小出入,更有甚者,可能从试验数据确定的模型参数,其“反算”曲线和原试验曲线并不能很好地吻合。也有一些将优化算法用于本构模型参数确定的尝试,但是采用的优化算法为传统的复合形算法等,其在计算效率、寻优能力、鲁棒性方面存在一些不足,使得该方法难以推广使用。
综合以上分析,现有的人工确定土体本构模型参数的方式主要缺陷有两点:1)土工试验数据离散性大,参数拟合和取定时需要一定的人为经验,另外,有些本构模型参数没有明确的物理意义,需要人为估算,这些因素导致同样的试验数据不同人员可能整理得到不同的本构模型参数,这些人为的误差可能导致根据试验数据取定的模型参数并不能与原始的试验数据很好吻合,使得本构模型预测精度严重恶化;2)土体本构模型参数数量多,不同参数之间存在一定的关联性,有些甚至需要试算和反复调整,采用常规方法取定本构模型参数工作任务繁重,且精度低。
技术实现要素:
本发明的目的在于克服现有技术的缺陷,提供一种基于人工智能算法的土体本构模型参数确定方法,以提高本构模型参数取定效率和精度。
实现本发明目的的技术方案是:一种基于人工智能算法的土体本构模型参数确定方法,包括:
步骤100:确定本构模型参数数目;
确定本构模型参数数目后,部分参数通过三轴试验试验数据直接确定,其余的n个参数变量x1~xn通过下述算法确定;
步骤200:产生初代种群;
设种群数目为n,经过基因编码得到n个个体x1~xn的基因型,其中每个个体x={x1,x2,...,xn};
步骤300:构建适应度函数;
步骤400:通过适应度函数对初代种群的n个个体x1~xn分别进行适应度评价,根据适应度由高到低对n个个体进行重新排序;
步骤500:设置阈值εuv,评价个体适应度是否满足要求,若排序中最高适应度个体对应的适应度≤εuv,则停止计算,将该个体作为最优个体输出,否则执行步骤600;
步骤600:根据遗传概率,通过下述操作产生新种群;
步骤601:基于浓度进行个体选择,得到子代种群n个个体;
步骤602:对子代种群n个个体进行个体交叉、变异,形成新的个体;
步骤603:子代种群n个个体经过交叉变异后,形成新的种群,跳转步骤400继续计算;反复执行步骤400至步骤603,依次形成第2代、第3代……第m代新种群,直至满足条件后终止。
作为本发明的进一步改进,所述步骤200中,个体基因型的获取方式如下:
设置[u1,min,u1,max],[u2,min,u3,max]……[un,min,un,max]依次为变量x1,x2,...,xn的上限和下限,生成一个随机参数aij∈[0,1],i=1,2,...,n;j=1,2,...,n;则:
将每个个体x={x1,x2,...,xn}代入式(1),得到n个个体的基因型。
作为本发明的进一步改进,所述步骤300中,适应度函数构建如下:
式中,ω1和ω2为偏应力和体积应变所占的权重,m为试验数据荷载步总数,qi,test为第i个点处试验数据偏应力值,qi,model为第i个点处模型计算所得偏应力值,εv,i,test为第i个点处试验数据体积应变值,εv,i,model为第i个点处模型计算体积应变值。
适应度函数是用于评价个体变现是否的优良的衡量标准,适应度函数选择不当,可能引起遗传算法只能收敛于局部最优,而不能达到全局最优,采用优选的适应度函数,遗传算法收敛度更好。
作为本发明的进一步改进,所述步骤601中,基于浓度的个体选择方式具体如下:
采用如下非线性排序的选择概率计算公式:
eval(xi)=α×(1-α)i-1(4)
上式中i为个体排序序号,i=1~n;α为排序第一的个体的选择概率参数;归一化得到每个个体被选择的概率如下:
求得累积概率
从区间(0,1)产生一个均匀分布的随机浮点数β;若β∈(psi-1,psi],则xi进入子代种群;n次重复产生随机数β,得到子代种群n个个体。
作为本发明的进一步改进,所述步骤602中,选用算术交叉算子进行个体交叉,通过两个个体的线性组合产生两个新的个体。
作为本发明的进一步改进,所述步骤602中,选用均匀变异算子进行个体变异,首先,依次指定个体编码串中每个基因座为变异点;然后,对每一个变异点以变异概率pm从对应基因值的取值范围内取一随机数来替代原有基因值;优选的变异概率pm∈(0.0001,0.1)。在遗传算法中采用变异算子主要目的是增强算法的局部搜索能力和维持群体的抗体多样性,变异算子可采用均匀变异(一致变异)、非均匀变异、边界变异和高斯变异等,本发明中采用均匀变异,操作简单,且搜索能力较优。
传统的土体本构模型参数取定方法效率低,且受到人为经验因素干扰。本发明基于人工智能算法将土体本构模型参数取定转化为求解系统最优解问题,减小了土体参数取定过程中对人为经验的依赖,并且提高了土体参数取定的效率。采用的人工智能算法具有强大的全局寻优能力。算法设计中提供了本构模型模块,能够灵活地应用于各类土体本构模型参数取定。
本发明提出的方法通过构建计算数据和试验数据之间的适应度函数将本构模型参数取定转化为一个系统最优解求解问题,并采用了遗传算法求解该系统的最优解,可以克服传统方法中人为经验的影响,并且可实现多个本构模型参数一次性获得,极大提高了本构模型参数取定效率。
附图说明
图1为本发明实施例的流程图;
图2为常规三轴试验中适应度函数参数图;
图3为本发明实施例的堆石料三轴试验数据图;
图4为本发明实施例的强度参数和剪胀参数拟合图;
图5为寻优过程各参量变化过程,其中图5(a)为λ随进化代数的变化过程;图5(b)为κ随进化代数的变化过程,图5(c)为m随进化代数变化过程,图5(d)为d随进化代数变化过程,图5(e)为适应度函数huv随进化代数变化过程;
图6为试验数据与遗传算法确定模型参数预测的曲线比较图;
图7为常规三轴试验试验加载路径;
图8现有技术的土体典型三轴试验曲线。
具体实施方式
下面结合实施例做进一步说明。
如图1所示,一种基于人工智能算法的土体本构模型参数确定方法,包括:
对土体试样施加初始固结压力;待试样固结稳定后,再施加剪切偏应力δσ1进行剪切;量测剪切过程中试样的应变和体积变化,并绘制典型三轴试验曲线;
基于遗传算法确定土体本构模型参数,包括下列步骤:
步骤100:确定变量数目
首先确定本构模型参数数目,假如某本构模型共9个参数x1,x2,x3,x4,...,x8,x9,其中,x5~x9易于通过试验数据直接确定,所以,需要优化确定的模型参数仅为x1,x2,x3,x4,每个变量xi都有其对应的变化范围[ui,min,ui,max],需确定的未知变量可以写成向量x={x1,x2,x3,x4}。
步骤200:产生初代种群:设种群数目为n,经过基因编码得到n个个体的基因型;
设种群数目为n,则随机产生n个初始向量,x1,x2,...xn,每个向量xi=(x1,x2,x3,x4)i,其中,[u1,min,u1,max]为变量x1的上限和下限,u2,min,u2,max]为变量x2的上限和下限,[u3,min,u3,max]为变量x3的上限和下限,[u4,min,u4,max]为变量x4的上限和下限。实际操作过程中,生成一个随机参数αi,j∈[0,1],i=1,2,...,n;j=1,2,3,4,i表示第i个个体,j表示第j个未知变量则有:
将每个个体xi=(x1,x2,x3,x4)i代入式(1)可以得到n个个体的基因型。
步骤300构建适应度函数。适应度函数是用于评价个体变现是否的优良的衡量标准,本方法采用如下适应度函数衡量个体的适应度:
式中,huv为适应度函数,ω1和ω2为偏应力和体积应变所占的权重,m为试验数据荷载步总数,qi,test为第i个点处试验数据偏应力值,qi,model为第i个点处模型计算所得偏应力值,εv,i,test为第i个点处试验数据体积应变值,εv,i,model为第i个点处模型计算体积应变值。如图2。
在常规三轴试验中,偏应力表示为:q=σ1-σ3,其中σ1为第一主应力,σ3为第三主应力。从图2中看出,qi,test和εv,i,test可以由试验数据直接获得。由本构模型计算获得第i个点处的qi,model和εv,i,model值,全量的偏应力qi,model为荷载步i之前所有荷载步偏应力增量的累加:
其中,δσ1,k为荷载步k引起的δσ1。
全量体积应变εv,i,model为荷载步i之前所有荷载步体积应变增量的累加:
其中,δε1,k为荷载步k引起的δε1,δε3,k为荷载步k引起的δε3,k。
步骤400:评价个体适应度:将初始种群的n个个体x1,x2,…,xn分别进行适应度评价,即将上述个体分别代入上步骤公式计算该荷载步对应的εv,i,model和qi,model,再代入式(2)得到每个个体对系统的适应度huv,huv越小个体的适应度越高,根据适应度由高到低对n个个体进行重新排序。
步骤500:评价适应度是否满足要求;当huv越小时个体的适应度越高,计算过程中可设置一个阈值εuv,步骤400中对种群适应度由高到低进行了排序,所以向量x1的适应度最高,若x1对应的适应度函数huv(x1)≤εuv,则停止计算,输出最优个体x1;若不满足则转向步骤600。
步骤600:根据遗传概率,用下述操作产生新种群:
步骤601:基于浓度的个体选择:采用如下非线性排序的选择概率计算公式:
eval(xi)=α×(1-α)i-1(5)
上式中i为个体排序序号,α为排序第一的个体的选择概率参数。归一化得到,每个个体被选择的概率
计算过程中需要求得累积概率psi,
从区间(0,1)产生一个随机浮点数β;若β∈(psi-1,psi],则xi进入子代种群;n次重复产生随机数β,得到子代种群n个个体。
步骤602:个体间交叉变异:个体间交叉是指两个相互配对的染色体相互互换部分基因,形成两个新的个体,在遗传过程中具有重要意义。本次的方法选用算术交叉算子。算术交叉是指由两个个体的线性组合而产生两个新的个体。例如:按杂交概率pc,一般建议pc∈(0.4,0.99),随机选取得两个父代向量
式中,α为(0,1)范围内的随机参数。
在遗传算法中采用变异算子主要目的是增强算法的局部搜索能力和维持群体的抗体多样性。常用的变异算子有均匀变异(一致变异)、非均匀变异、边界变异和高斯变异等,本发明中采用均匀变异算子,操作简单,且搜索能力较优。其操作过程是:首先,依次指定个体编码串中每个基因座为变异点。然后,对每一个变异点以变异概率pm从对应基因值的取值范围内取一随机数来替代原有基因值。优选pm∈(0.0001,0.1)。
x′k=umin+γ(umax-umin)(8)
式中γ为[0,1]范围内符合均匀概率分布的一个随机数。
步骤603新种群的产生:步骤601中选择的n个个体经过步骤602中的交叉和变异后形成了新的种群(第2代),将这些n个新个体重新回到步骤400,反复执行步骤400~步骤602,依次形成第2代、第3代..第n代新个体,直至满足条件后终止。
下面以近些年来使用较为普遍的广义塑性模型为例,说明本发明方法的有效性,广义塑性模型弹塑性矩阵写为:
其中,de为弹性矩阵,dep为塑性矩阵;ng为塑性流动方向;n为加载方向;h为塑性模量,表达式分别如下:
弹性模量为,
广义塑性模型有
图3为某堆石材料三轴试验数据,该种堆石料强度参数和剪胀参数可直接根据试验资料确定,如图4,将破坏点处摩擦角和平均应力绘制在图中,线性拟合得到强度参数
遗传算法过程中需要确定的变量有λ,κ,m,d4个,优化算法初始参数设定如下:
①设定变量变化基本范围,根据变量的物理意义和使用经验取定范围如下λ∈[0.004,0.19];κ∈[0.0013,0.06];m∈[0.001,1.0];d∈[0.001,6.0],此初始变化范围可通过试算调整。
②设定优化算法控制参数,根据项目优化精度要求、计算机计算能力和容量设定算法执行参数。本案例种群数目设定n=100个,最大进化代数设定为20代,注意到种群数目越大,进化代数越多系统越易达到其最优解,但相应的计算成本也随之增加,此参数用户可根据自身需求设定。
本实施例中适应度函数阈值εuv设定,若某个体适应度小于该值则输出个体,终止计算,阈值越小,系统的解越优化,计算成本也增大,此参数用户可根据自身需求设定。
偏应力权值偏应力权值ω1,ω2用于指示偏应力精度和体积应变精度分别所占的比重,通常地,土工参数对偏应力精度要求更高,本实施例中设定ω1=0.8,体积应变权值ω2=0.4。
选择概率参数α,变异概率参数pm,杂交概率pc均为常数,分别取定为0.12,0.1,0.9。
本实施例基于fortran语言实现了上述算法,程序框架如下:
子程序input用于读入变量数目、各变量的变化范围、三轴试验数据等;
子程序initialization用于产生初代种群个体;
子程序adaptability用于计算个体的适应度并选择适应度较高的个体;
子程序cross用于对新种群进行交叉运算;
子程序mutation用于对新种群进行变异运算。
图5为寻优过程各变量演化过程,其中图5(a)为λ随进化代数的变化过程;图5(b)为κ随进化代数的变化过程,图5(c)为m随进化代数变化过程,图5(d)为d随进化代数变化过程,图5(e)为适应度函数huv随进化代数变化过程。
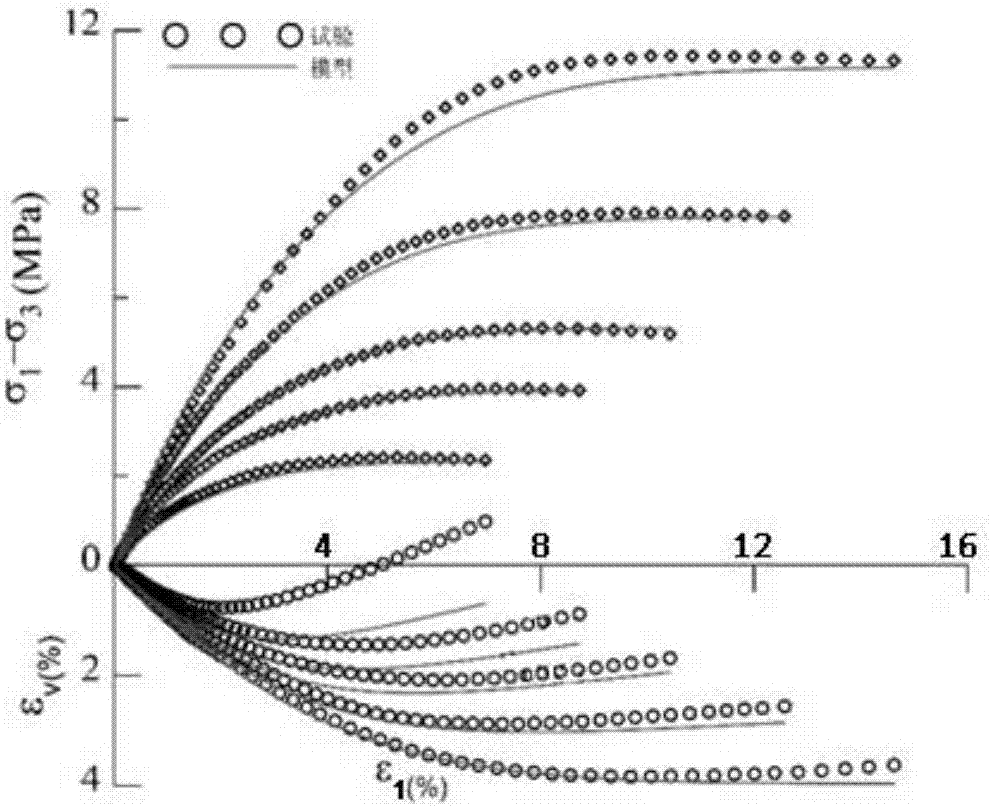
从计算结果可以看出,进化代数大于12代后,各参数值基本稳定,适应度函数值随着进化代数显著减小,说明本次发明提出的方法在本构模型参数确定方面效率高。本例中λ,κ,m,d最终值分别为0.0075、0.0024、0.566、1.009。图6为试验数据与遗传算法确定模型参数预测的曲线比较,可以看出,本次提出的方法确定的模型参数计算结果与试验数据吻合较好。
本发明的关键点是结合了遗传算法在系统优化方面优势,将其引入到土体本构模型参数确定方法中,减小了模型取定过程中对人为经验的依赖,提高了土体本构模型参数确定的效率,由于优化算法采用了全局寻优能力强的遗传算法,算例表明本次提出的方法具有极强的实用性。
- 还没有人留言评论。精彩留言会获得点赞!