一种基于Kriging模型的约束全局优化方法与流程
本发明涉及基于元模型的智能优化、计算机仿真应用领域,尤其涉及的是,一种基于kriging模型的约束全局优化方法。
背景技术:
计算机仿真分析的最终目的是优化设计,基于kriging模型的仿真优化方法利用计算机试验设计、优化算法、kriging建模及其所给出的有效信息来实现模型的仿真优化。在优化过程中,来自于kriging模型的估值、方差等信息能够有效地指导优化搜索朝向全局的方向。因此,针对复杂并行仿真,基于计算机试验设计的kriging优化方法是一种有效的解决途径。但目前仍存在不足。
kriging是一种通过已知点来预测未知观察点的一种插值方法。kriging思想源于南非的矿业工程师krige;接着法国数学家georges对该思想进行系统化、理论化分析,提出一种插值和外推理论;进而又被运用到计算机科学,产生kriging模型;后来,试验设计与kriging实现过程的结合被称为计算机试验设计与分析(dace),广泛应用于采矿业、水文地质学、自然资源、环境科学、遥感、工程分析、机电产品设计的黑箱仿真模型中。
在少量昂贵估值下,基于kriging约束问题的优化效率不高,且难以获得更好的优化精度。复杂目标和黑箱约束的仿真问题易导致基于kriging优化方法在某些情况下陷入局部最优区域。在算法无法有效判断是否陷入该区域的情况下,通常需要经过大量昂贵仿真估值方可跳出,这将大幅降低约束优化效率。从优化精度方面考虑,以少量昂贵仿真估值次数作为优化停止的依据,将无法判断搜索到的近似最优解是否为全局最优解,但又不得不接受这个最优解。而且,随着优化问题复杂度的增加,传统加点采样准则的多峰性和复杂性将导致优化采样难度大幅增加,从而影响最终的优化精度。
基于kriging的约束优化难以实现。在带有黑箱约束的优化问题中,必须判断初始试验设计所获取样本点的可行性,否则,进一步的迭代优化毫无意义。如果缺少初始可行采样点,需要利用已存在的有效信息探索一种可行采样点的获取方法。此外,目标和约束的黑箱性和复杂性将导致求解优化问题的难度骤然增加,如何通过kriging模型的方差估计、目标估值和权重系数构造有效的加点采样准则,以获取下一个近似最优可行解,以及在多次搜索后无法获取可行采样点的情况下,如何通过合理的校正方法将处于可行域边界的采样点拉回到可行域内,有待于进一步研究。
技术实现要素:
本发明所要解决的技术问题是提供一种兼顾kriging建模和约束优化采样的基于kriging模型的约束全局优化方法。
为实现上述目的,本发明所采用了下述的技术方案:一种基于kriging模型的约束全局优化方法,包括步骤如下:
s1,通过拉丁超立方试验设计获取2*(d+1)个初始样本点(d表示设计变量的个数);对每一个数据点xi(i=1,...,m),计算目标f(xi)及约束g1(xi),...,gq(xi),并得到初始最佳函数值fbest和所对应的xbest;
s2,初始建模;利用初始试验设计所获取的采样点和仿真估值,并结合计算机试验设计与分析(dace)方法分别建立目标函数和约束函数的kriging模型;
s3,获取可行采样点:在没有初始可行采样点的情况下,循环执行以下子步骤,直到获取可行采样点;
s31:根据当前迭代点x获取近似目标
s32:计算当前样本中所有采样点之间的最大距离dmax,并设置dj=λiter*dmax,其中λiter根据迭代次数从常数矩阵θ={λ1,λ2,...,λk}={0.1,0.05,0.01,0.005,0.001,0.0005}中获取;
s33:优化最大如公式1所示的可行概率来寻找一个可行采样点;
其中,φ(·)是一个正态累计分布函数,s是最大约束函数
s34:对xnext进行昂贵的函数仿真估值,并加入到样本数据集中;
s35:根据g1(xi),...,gq(xi)是否小于0判断xnext是否为可行采样点,如果不是,则跳转到s31,如果可行且当xnext小于xbest时,设置xbest:=xnext,fbest:=fnext,并顺序向下执行;
s4,根据所获得的可行采样点搜索一个全局最优可行解,循环执行下面的子流程,直到满足所允许的最大函数仿真估值次数;
s41:通过对公式2进行优化来获取下一个更优可行采样点xnext;
其中,
s42:权重系数ki的选择;首先,定义松弛因子δ,如公式3所示;
这里的τ1和τ2(0<τ1<1,τ2>1,经验值选择τ1=0.618和τ2=1.618)是松弛常数,
其中nmax是最大昂贵函数估值次数;权重ki-1<1(当ki-1=1时,
s43:在迭代点xnext处对f(x)和g1(x),...,gq(x)进行估值,并加入不可行采样点集;如果xnext不可行,不可行采样点总数目加1,并更新样本集;
s44):当满足不可行采样点的总数大于所允许的最大不可行次数时,选择不可行采样点集中的最小违背点作为伪可行点;并在该点处运行近似约束校正方法得到一个校正点xcorrect,并转到s45;否则的话,返回步骤s1;
s45:在点xcorrect处对f(x)和g1(x),...,gq(x)进行昂贵估值,而且,如果xcorrect是可行点,且小于点xbest处的函数值,则设置xbest:=xcorrect,fbest:=fcorrect;
s46:根据所获得的采样点更新样本数据集;
s5,根据所获得的可行采样点,更新样本数据集。
相对于现有技术的有益效果是,采用上述方案,本发明在一次迭代优化过程中获取多个有效的并行昂贵估值(采样)点,以便大幅减少昂贵仿真时间的消耗并提高全局寻优速度,从而解决在可行采样点的获取和最优可行点的搜索方面所存在的缺陷。
附图说明
图1是基于kriging模型的约束全局优化方法的基本流程图;
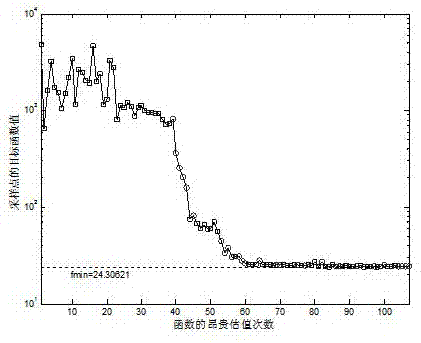
图2是测试函数g7在约束优化过程中的迭代过程;
图3是测试函数g8在约束优化过程中的迭代过程;
图4是方法验证的实例模型-减速器的优化设计图;
图5是减速器约束优化设计问题的迭代过程。
具体实施方式
为了便于理解本发明,下面结合附图和具体实施例,对本发明进行更详细的说明。附图中给出了本发明的较佳的实施例。但是,本发明可以以许多不同的形式来实现,并不限于本说明书所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
需要说明的是,当元件被称为“固定于”另一个元件,它可以直接在另一个元件上或者也可以存在居中的元件。当一个元件被认为是“连接”另一个元件,它可以是直接连接到另一个元件或者可能同时存在居中元件。本说明书所使用的术语“垂直的”、“水平的”、“左”、“右”以及类似的表述只是为了说明的目的。
除非另有定义,本说明书所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本说明书中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是用于限制本发明。
如图1-5所示,本发明的一个实施例是,该一种基于kriging模型的约束全局优化方法,包括步骤如下:
s1,通过拉丁超立方试验设计获取2*(d+1)个初始样本点(d表示设计变量的个数);对每一个数据点xi(i=1,...,m),计算目标f(xi)及约束g1(xi),...,gq(xi),并得到初始最佳函数值fbest和所对应的xbest;
s2,初始建模;利用初始试验设计所获取的采样点和仿真估值,并结合计算机试验设计与分析(dace)方法分别建立目标函数和约束函数的kriging模型;
s3,获取可行采样点:在没有初始可行采样点的情况下,循环执行以下子步骤,直到获取可行采样点;
s31:根据当前迭代点x获取近似目标
s32:计算当前样本中所有采样点之间的最大距离dmax,并设置dj=λiter*dmax,其中λiter根据迭代次数从常数矩阵θ={λ1,λ2,...,λk}={0.1,0.05,0.01,0.005,0.001,0.0005}中获取;
s33:优化最大如公式1所示的可行概率来寻找一个可行采样点;
其中,φ(·)是一个正态累计分布函数,s是最大约束函数
s34:对xnext进行昂贵的函数仿真估值,并加入到样本数据集中;
s35:根据g1(xi),...,gq(xi)是否小于0判断xnext是否为可行采样点,如果不是,则跳转到s31,如果可行且当xnext小于xbest时,设置xbest:=xnext,fbest:=fnext,并顺序向下执行;
s4,根据所获得的可行采样点搜索一个全局最优可行解,循环执行下面的子流程,直到满足所允许的最大函数仿真估值次数;
s41:通过对公式2进行优化来获取下一个更优可行采样点xnext;
其中,
s42:权重系数ki的选择;首先,定义松弛因子δ,如公式3所示;
这里的τ1和τ2(0<τ1<1,τ2>1,经验值选择τ1=0.618和τ2=1.618)是松弛常数,
其中nmax是最大昂贵函数估值次数;权重ki-1<1(当ki-1=1时,
s43:在迭代点xnext处对f(x)和g1(x),...,gq(x)进行估值,并加入不可行采样点集;如果xnext不可行,不可行采样点总数目加1,并更新样本集;
s44):当满足不可行采样点的总数大于所允许的最大不可行次数时,选择不可行采样点集中的最小违背点作为伪可行点;并在该点处运行近似约束校正方法得到一个校正点xcorrect,并转到s45;否则的话,返回步骤s1;
s45:在点xcorrect处对f(x)和g1(x),...,gq(x)进行昂贵估值,而且,如果xcorrect是可行点,且小于点xbest处的函数值,则设置xbest:=xcorrect,fbest:=fcorrect;
s46:根据所获得的采样点更新样本数据集;
s5,根据所获得的可行采样点,更新样本数据集。
需要说明的是,上述各技术特征继续相互组合,形成未在上面列举的各种实施例,均视为本发明说明书记载的范围;并且,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!