一种基于多模态低秩双线性池化的图像内容问答方法与流程
本发明涉及一种针对图像内容问答(imagequestionanswer,iqa)的深度神经网络,尤其涉及一种对图像-问题的跨媒体数据进行统一建模的方法以及在图像和问题细粒度特征上学习“协同关注点”进行建模表达。
背景技术:
“跨媒体”统一表达是一个计算机视觉与自然语言处理研究领域之间的交叉方向,旨在打通不同媒体(如图像和文本)之间的“语义鸿沟”,建立统一的语义表达。基于跨媒体统一表达的理论方法,衍生出一些目前热门的研究方向,如自然描述生成(imagecaptioning)、图像-文本跨媒体检索(image-textcross-mediaretrieval)以及图像内容的自动问答(imagequestionanswering,iqa)等。图像自然描述生成的目标是给一张图像使用一句或几句自然语言对其内容进行概述;图像-文本的跨媒体检索旨在给一张图像从数据库中找到最匹配的文本描述,或给一个文本描述寻找最匹配的图像;图像内容的自动问答的目标在于输入一张图片和一个自然语言描述的问题,算法自动输出一个自然语言描述的答案
随着近年来深度学习的迅速发展,使用深度神经网络,如深度卷积神经网络(convolutionalneuralnetworks,cnn)和深度循环神经网络(recurrentneuralnetworks,rnn)进行端到端(end-to-end)地问题建模成为目前计算机视觉、自然语言处理方向上的主流研究方向。在图像内容问答算法中,引入端到端建模的思想,同时对图像和问题的文本使用适当的网络结构进行端到端建模,直接输出自然语言描述的答案是一个值得深入探索的研究问题。
在实际应用方面,图像内容自动问答算法具有非常广泛的应用场景。基于文本的问答系统已经被广泛应用在智能手机和pc的操作系统中,作为人机交互的一种重要方式,如苹果的siri,微软的cortana,亚马逊的alexa等。随着可穿戴智能硬件(如googleglasses和微软的hololens)以及增强现实技术的快速发展,在不久的将来,基于视觉感知的图像内容自动问答系统可能会成为人机交互的一种重要方式,改变人们目前的交流。在这项技术可以帮助我们,尤其是那些有视觉障碍的残疾人更好地感知和理解世界
综上所述,基于端到端建模的图像内容问答算法是一个值得深入研究的方向,本课题拟从该任务中几个关键的难点问题切入,解决目前方法存在的问题,并最终形成一套完整的图像内容问答系统。
由于自然场景下的图像内容复杂,主体多样;自然语言描述的问题自由度高,这使得图像内容的问答算法面临巨大的挑战。具体而言,主要存在如下两方面的难点:
(1)对图像问题的跨媒体数据进行统一建模,如何进行有效地特征融合:多模态特征融合问题是跨媒体表达中一个经典且基础的问题,常用的方法有特征拼接、特征加和,或使用多层神经网络的特征融合等。此外,基于双线性模型的特征融合模型,在很多领域,如图像细粒度分类、自然语言处理、推荐系统中都发挥了非常好的效果,但是由于其计算复杂度高,给模型的训练带来了很大的挑战。因此,在跨媒体数据特征融合时选择合适的策略,在保证计算的高效性地同时,提高融合特征的表达能力是一个值得深入研究的方向。
(2)如何在图像和问题细粒度特征上学习“协同关注点”进行建模表达:图像内容自动问答算法的输入包含自然语言描述的问题和内容复杂的图像。要正确地回答图像内容相关的问题,既要抽取文本中的关键信息,对问题进行正确地理解(例如,针对“图片中有几个女人?”和“图片中有几个男人?”这两个截然不同的问题,算法要理解“男人”和“女人”是问题中的关键词),同时还要聚焦图像中和问题相关的主体。因此,如何让算法自动学习到图像和问题中的“协同关注点”(co-attention),即问题中的关键词和图像中对应区域,从而进行细粒度特征的融合,形成更为准确地跨媒体表达,是图像内容问答算法中的难点问题,同时也是影响算法结果性能的至关重要的环节。
本发明提出了一种针对图像内容自动问答任务的深度神经网络架构,以解决如上两个难点问题。1、提出一种多模态低秩双线性池化模型,实现不同模态特征之间的有效融合;2.在神经网络框架下,提出一种协同关注点模型,同时对问题和图像中的共同关注区域进行有效学习。
技术实现要素:
本发明的目的是针对现有技术的不足,提供一种基于多模态低秩双线性池化的图像内容问答方法。
本发明解决其技术问题所采用的技术方案如下:
给定图像i、相应的问题q和答案a,构成三元组i,q,a作为训练集。
步骤(1)、数据预处理,对图像和文本数据提取特征
对图像i预处理:先将图像i缩放到统一的尺寸大小,再使用现有的深度神经网络提取图像的特征if。
对问题q和答案a的文本数据的预处理:
问题q文本数据:首先分词,构建问题文本字典,将问题文本保留前l个词语并把词语替换成字典中的索引值,得到文本索引向量;
答案a文本数据:不分词,构建答案字典并截取频率最高的υ个答案。并将给定的答案转换成答案字典中的索引值,最后转换成υ维的一位有效编码(one-hot)答案向量;
步骤(2)、创建多模态低秩双线性池化(multi-modalfactorizedbilinearpooling,mfb)模型,进行特征融合。
本文在现有的原始双线性池化模型(bilinearpoolingmodel)的基础上,提出了一种多模态低秩双线性池化(mfb)模型,克服了原始双线性模型参数量过大的问题,并且基于神经网络实现该模型步骤(3)、基于协同关注点建模的神经网络模型
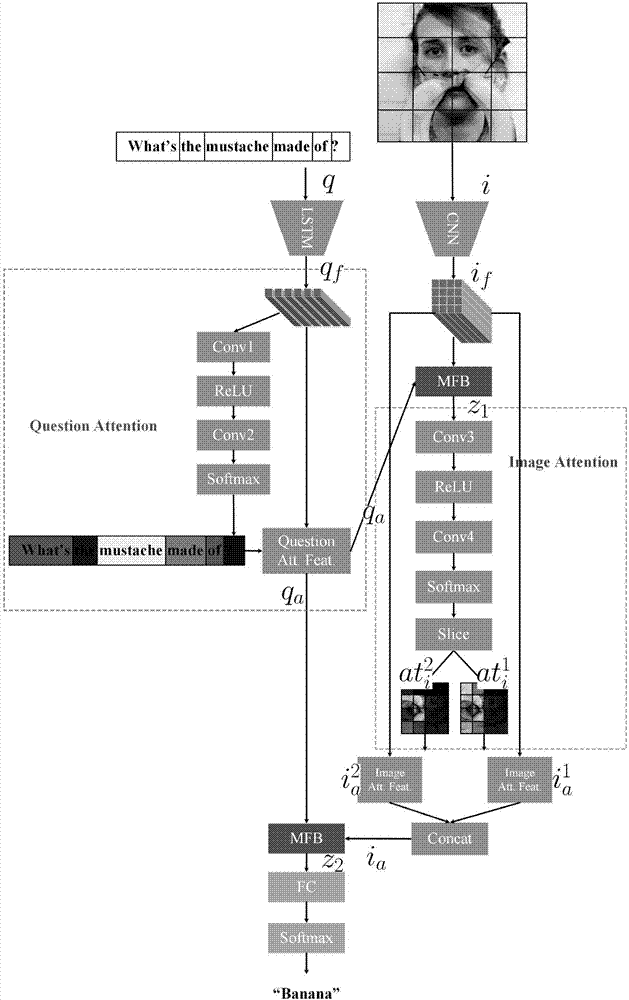
对于问题文本,首先将问题文本的一位有效编码(one-hot)特征利用词语向量化(wordembedding)技术转换成矩阵qe。将转换后的问题矩阵qe输入到长短期记忆网络(longshorttermmemory,lstm)并输出l×d维向量qf,其中l是问题的词语个数,d是lstm输出特征维度。对问题生成注意点区域特征attq,并生成带注意点信息的问题特征qa,如图2中的questionattention部分所示。将生成的qa和图像的特征if输入步骤(2)描述的模型(mfb)得到输出特征z1。如图2中imageattention部分所示,对图像提取注意点区域特征atti,其中atti是一个多通道特征矩阵,其中每个通道代表一个图像注意点区域特征。将图像特征if同atti的每一个通道做softattention操作,其中softattention将在之后具体介绍,并将结果拼接起来生成输出ia,将ia同qa一起输入到步骤(2)的模型(mfb)并输出z2。对z2做全连接操作后产生一个v维向量(其中v是上述构建的答案字典的大小),再经过一个softmax产生概率输出作为网络的输出预测值。
步骤(4)、模型训练
根据产生的预测值同该问题的实际答案的差异,并利用反向传播算法(back-propagation,bp)对步骤(3)定义的神经网络的模型参数进行训练,直至整个网络模型收敛。
步骤(1)所述的数据预处理及对图像和文本进行特征提取:
1-1.对图像i进行特征提取,使用现有的深度神经网络提取图像特征,形成图像特征if,其中
1-2.对于问题文本首先将问题文本拆分成固定单词个数的单词列表qw,其具体公式如下:
qw=(w1,w2,...,wl)(公式1)
其中wi是单词字符串,l为单词数;
根据单词字典将单词列表qw中的词语转化成索引值,得到固定长度的索引值向量qi,其具体公式如下:
其中
1-3.将答案文本记为as,直接将答案替换成答案字典中的索引ai,之后将答案转化成一个v维且只在ai元素上值为1,其余元素全为0的一位有效编码(one-hot)向量ao,其中v是答案字典的大小,其具体公式如下:
ai=dict(as)(公式3)
ao=onehot(ai)(公式4)
其中dict(as)表示查找as在答案字典中的索引值,onehot(ai)是一位有效编码函数作用是将ai转换成向量ao,其中
步骤(2)所述的多模态低秩双线性池化模型(multi-modalfactorizedbilinear,mfb)对特征融合,具体如下:
首先叙述原始双线性池化模型(bilinearpoolingmodel),以及在双线性模型基础上利用矩阵分解推导mfb模型的具体过程如下:
2-1.原始双线性池化模型(bilinearpoolingmodel)公式如下:
其中
其中
在双线性模型基础上推导mfb模型的具体过程如下:
将公式(5)中的wi近似表示成两个低秩矩阵相乘wi≈uivit;
并且公式(7)可进一步推导成如下形式:
其中
为了得到
进一步推出:
其中
可得mfb模型总的参数量为k×(m+n),相较于原始双线性模型大大的减少了参数量。
接下来叙述mfb模型基于神经网络的具体实现如下:
2-3.利用映射矩阵将输入的特征映射到k×o维,具体公式如下:
x1=utx;y1=vty(公式12)
其中
2-4.对两个相同维度的向量做hadamardproduct,其具体公式如下:
2-5.对hadamardproduct输出做sumpooling操作,其具体公式如下:
其中
2-6.对于z进行归一化操作,具体归一化公式如下:
zo=normalize(z)(公式15)
综上,mfb函数的公式如下:
步骤(3)所述的构建深度神经网络,具体如下:
3-1.为了把文本转换成网络需要的文本特征矩阵,将步骤(1)输出的索引向量qi中的索引值通过wordembedding转换成词向量,得到文本词向量特征
其中
将问题词向量特征qe输入到lstm,输出特征
qf=lstm(qe)(公式18)
3-2.如图2中所示的questionattention部分,对问题文本特征qf提取注意点特征(questionattention)attq,具体的,将qf依次进过conv1,relu,conv2,softmax操作生成attq,其中conv1,conv2表示卷积操作,relu表示非线性激活函数,并将attq和问题特征qf融合,输出带关注点信息的问题特征qa,具体公式如下:
attq=softmax(conv(relu(conv(qf))))(公式19)
qa=softattention(attq,qf)(公式20)
其中
softattention公式表述如下:设att=[att1,att2,...,attn];
sa=softattention(att,x)=att1·x1+att2·x2+...+attn·xn(公式22)
3-3.对步骤(1)产生的图像特征if提取图像注意点区域特征(imageattention)atti。其中首先将qa复制h×w份,得到
z1=mfb(if,qt)(公式23)
atti=softmax(conv(relu(conv(z1))))(公式24)
其中
3-4.将3-2输出的带关注点信息的问题文本特征qa和3-3输出的带关注点信息的图像特征ia输入到步骤(2)描述的mfb模块产生输出z2,并依次进过fc和softmax操作,其中fc是神经网络全连接操作,最终输出答案预测向量
z2=mfb(ia,qa)(公式27)
p=softmax(fc(z2))(公式28)
步骤(4)所述的训练模型,具体如下:
将步骤(3)产生的预测向量p同步骤(1)产生的答案向量ao输入到定义的损失函数kldloss,得到损失值loss,具体公式如下:
loss=kldloss(ao,p)(公式29)
其中kldloss公式如下:
其中
根据计算得到的损失值loss,利用反向传播算法(back-propagation,bp)调整网络中的参数。
本发明有益效果如下:
本发明所提出的方法在针对图像内容问答(imagequestionanswer,iqa)的问题上相比于其他方法在准确率上取得了目前最好的成绩;大大减少了模型参数量,有效地防止模型过拟合并降低了模型训练时间;并且相比于其他模型更加简单易于实现。
本发明提出一种针对图像问答的神经网络模型,特别是提出一种图像问答领域中对图像-问题的跨媒体数据进行统一建模的方法,以及在图像和问题细粒度特征上学习“协同关注点”进行建模表达的网络结构,并且获得了目前在图像问答领域中的最好效果。
附图说明
图1为多模态低秩双线性池化模型的结构示意图。
图2为本发明的总体流程图。
具体实施方式
下面对本发明的详细参数做进一步具体说明。
如图1所示,本发明提供一种针对图像内容问答(imagequestionanswer,iqa)的深度神经网络结构,具体步骤如下:
步骤(1)所述的数据预处理及对图像和文本进行特征抽取,具体如下:
这里使用coco-vqa数据集作为训练和测试数据。
1-1.对于图像数据,这里使用现有的152层深度残差网络(resnet-152)模型抽取图像特征。具体的,我们把图像数据统一缩放到448×448并输入到深度残差网络中,抽取其res5c层的输出作为图像特征
1-2.对于问题文本数据,我们先对问题分词,并且构建问题的单词字典。并且每个问题只取前15个单词,若问题不满15个单词则补充空字符。之后,将每个单词用该单词在单词字典中的索引值代替,得到问题文本的单词索引向量特征
1-3.对于答案文本数据不做分词。这里统计每个答案的频率并取出现频率最高的3000个答案,同样的对这3000个答案建立答案字典。
步骤(2)所述的多模态低秩双线性池化模型(multi-modalfactorizedbilinear,mfb)对特征融合,具体如下:
2-1.对于输入特征
2-2.我们使用hadamardproduct对映射后的向量进行融合操作,其中hadamardproduct表示两个向量间对应元素相乘,得到5000维输出特征。
2-3.为方便操作,将上一步骤产生的5000维特征重排,形成5行1000列的矩阵,并用矩阵1与该矩阵相乘,其中
设x=[x1,x2,...,xn]
至此完成多模态低秩双线性池化(mfb)操作。
步骤(3)所述的构建深度神经网络,具体如下:
3-1.对于问题文本特征,输入是步骤(1)产生的15维索引向量,经过wordembedding技术将每个单词索引转换成300维词向量,得到问题词向量特征
3-2.如图2中的questionattention部分所示,提取问题文本的注意点(attention)特征。对lstm的输出向量qf依次进行conv1,relu,conv2,以及softmax操作,其中conv1,conv2的核大小为1×1,输出通道(channel)分别为512和1。得到问题文本的注意点特征
3-3.如图2中imageattention部分所示,提取图像的注意点(attention)特征,。我们将上一步得到的带注意点信息的问题特征复制196(14×14)份,并变形成1024×14×14维的矩阵,将其和步骤(1)中的图像特征if一起输入到步骤(2)描述mfb模块,将其输出依次进过conv3,relu,conv4,softmax操作得到g个图像注意点特征
3-4.我们将上述生成的带注意点信息的问题特征与带注意点信息的图像特征再次使用步骤(2)描述的mfb模块进行特征融合,产生1000维的输出特征。之后将该向量依次进过输出通道为3000的fc操作(其中fc表示全连接),以及softmax操作,得到输出特征
步骤(4)所述的训练模型,具体如下:
对于步骤(3)产生的预测3000维向量,将其与该问题的正确答案做比较,通过定义的损失函数kldloss计算得出预测值与实际正确值之间的差异并形成损失值,之后根据该损失值利用反向传播算法(back-propagation,bp)调整整个网络的参数值,直到网络收敛。
表1是本文所述的方法在coco-vqa数据集中准确率。其中oe表示开放式答案(open-ended,oe)任务,mc表示多选式答案(multi-choice)任务,all表示在所有问题的上的准确率,y/n表示在判断式问题上的准确率,num表示需回答数量的问题上的准确率,others表示在其他问题上的准确率。
- 还没有人留言评论。精彩留言会获得点赞!