一种适用于实时系统周期任务模型的低功耗调度方法与流程
本发明涉及实时系统周期性任务模型的实时调度,具体的说是一种适用于实时系统周期任务模型的低功耗调度方法。
背景技术:
随着超大规模集成电路技术发展,处理器的能耗也越来越大。实时系统是任务的截止时间有严格约束的调度系统,处理器功耗的增加势必导致不稳定性,因此有效降低处理器能耗是实时调度算法需要考虑的问题。实时系统调度分为周期性任务和偶发任务,其中周期性任务模型是实时系统中一种重要的任务模型,特点是任务实例呈周期性到来。目前针对周期性任务集的调度算法主要采用dvs技术,任务的实际执行时间往往小于它的最坏情况下执行时间,从而产生空闲时间。dvs技术可以回收空闲时间,分配给就绪队列中未完成的任务,降低其速度从而降低能耗。目前处理器的功耗分为三部分:静态功耗ps,与速度无关的功耗pind和与速度相关的pdep,pind主要来自漏电电流功耗,pdep主要来自动态功耗。处理器以速度s运行的动态功耗pdep可表示为pdep=cef·sm,其中cef代表电路中的负载电容,s为处理器的运行速度,m是和处理器功耗无关的常指数(2≤m≤3)。因此,处理器的总功耗可以表示为:p=ps+h(pind+pdep)=ps+h(pind+cef·sm),其中系数h为常量,当h=1,表示有任务在运行;否则h=0。处理器动态功耗和速度成约二次方关系,动态功耗因速度降低而大幅度降低。但是低速度势必会导致任务的实际执行时间延长,从而增加静态功耗。为保证系统总功耗最优,现有研究指出了使得系统能耗最低的关键速度,指出超过或低于关键速度,处理器的功耗会增加,其中关键速度
假定处理器能够提供连续的速度,并且对速度进行归一化,使得处理器提供的速度范围为[smin,1],其中smin为处理器的最低运行速度。处理器有三个状态:关闭状态,活跃状态,空闲状态,当处理器处于关闭状态时不消耗能量。若采用dpm技术,考虑到关闭处理器所需的开销,令e0为空闲状态切换到关闭状态所需的能耗开销,pidle为空闲状态的功耗,则关闭处理器的时间开销
技术实现要素:
现有的对周期性任务集低功耗调度的研究大部分都利用了dpm技术以及关键速度来降低能耗,即当传统dvs策略计算的速度小于关键速度时,采用关键速度运行任务。但关键速度也不是绝对的使得能耗最小的速度。在采用传统调度策略或关键速度之间存在一个平衡点,根据任务最坏情况下执行时间与平衡点比较来确定处理器速度。
本发明为实现上述目的所采用的技术方案是:一种适用于实时系统周期任务模型的低功耗调度方法,包括:
步骤1:周期任务集开始调度前,计算周期任务集的总利用率utot、处理器离线速度sof;所述周期任务集为t(t1,t2,t3,…ti…tn),共包含n个周期任务;
在实时调度器上设置任务就绪队列、任务到来队列;所述任务就绪队列包含就绪任务集合rd(ti,t),其中,t表示时刻,ti表示第i个周期任务,且就绪任务集合按照任务的优先级高低排列;所述任务到来队列包含已经运行完毕但下一个实例还没到来的任务;
步骤2:第i个周期任务ti(pi,ci)在t时刻到达时,根据最早截止期限edf优先顺序将周期任务ti(pi,ci)插入任务就绪队列中,并初始设置remi(t)=wi(t)=ci;其中,pi是ti的周期,ci是ti的最坏情况下执行时间,remi(t)是周期任务ti在时刻t的可利用执行时间,wi(t)是周期任务ti在时刻t的剩余最坏情况下执行时间;
步骤3:第i个周期任务ti(pi,ci)在t时刻调度执行,重新计算ti在时刻t的可利用执行时间remi(t),重新计算ti的执行速度si=wi(t)/remi(t);当si<scrit时,判断采用scrit或仍保持si作为执行速度;其中,scrit为关键速度;
步骤4:若t时刻,ti运行过程中不被其他就绪任务抢占,则当周期任务ti执行时remi(t)和wi(t)逐渐减少,如果ti执行完毕,则置wi(t)=0,ti移出任务就绪队列,加入至任务到达队列;将pi增加到ri作为下次周期任务ti的到达时间;返回步骤2继续执行周期任务,直到周期任务执行完毕;
若t时刻,ti运行过程中被其他就绪任务抢占,则保留remi(t),wi(t),将周期任务ti重新按edf优先级顺序加入就绪队列,返回步骤2继续执行周期任务,直到周期任务执行完毕。
所述周期任务集的总利用率的计算公式为
所述步骤2中的第i个周期任务ti(pi,ci)在t时刻到达时,根据最早截止期限edf优先顺序将周期任务ti(pi,ci)插入任务就绪队列中为根据任务的截止时间动态分配任务的优先级;截止时间越靠前,优先级越高;其中,周期任务ti的截止时限di计算公式为di=ri+pi,其中ri是周期任务ti该次的到达时间。
所述步骤3中的重新计算周期任务ti在时刻t的可利用执行时间remi(t)为:将slh(ti,t)与sll(ti,t)之和增加到remi(t);
其中,比周期任务ti优先级高的任务提前完成所产生的空闲时间总和表示为slh(ti,t);计算公式为
定义时刻tf=t+slh(ti,t)+remi(t);如果在时刻tf就绪队列为空,则定义tf′为在时刻tf之后最近的一次任务的到达时刻;tβ为在时刻tf之前没有完成的优先级最高的任务,remβ(t)和wβ(t)分别为周期任务tβ在时刻t的可利用执行时间和剩余最坏情况下执行时间;
定义pl′(tβ,t)={tx|tx∈pl(ti,t)且dx≤dβ},其中,pl(ti,t)表示在时刻t之前已完成的优先级比周期任务ti低的任务集合,dx和dβ分别表示tx和tβ和截止时限;
如果在[tf,tf+sll(ti,t)]和[tf′,tf′+sll(ti,t)]时间段内存在其他就绪任务tλ,则sll(ti,t)的计算公式为sll(ti,t)=rλ-tf;否则,sll(ti,t)的计算公式为
所述步骤3中的当si<scrit时,判断采用scrit或仍保持si作为执行速度,包括:
假定周期任务ti在区间δt内执行而不被抢占,若有wi(t)<scrit*δt且
在t时刻令δt=remi(t),x=wi(t)判别方法如下:
若pind*δt-e0>0,则在区间(0,scrit*δt)内必有一点w0使得f(w0)=0,该点即为平衡因子,当f(wi(t))>0时,采用scrit作为执行速度,反之保持si作为执行速度;
若pind*δt-e0≤0,保持si作为执行速度;
其中,α是负载电容参数,s是处理器的执行速度,pind是静态功耗,e0为关闭处理器的开销。
本发明具有以下有益效果及优点:
1.采用本发明方法,在保证系统中周期任务可调度性的前提下,充分利用系统的空闲时间,减少关闭处理器的次数。
2.采用本发明方法,在保证系统中周期任务可调度性的前提下,充分降低系统的能耗,保证系统稳定性。
附图说明
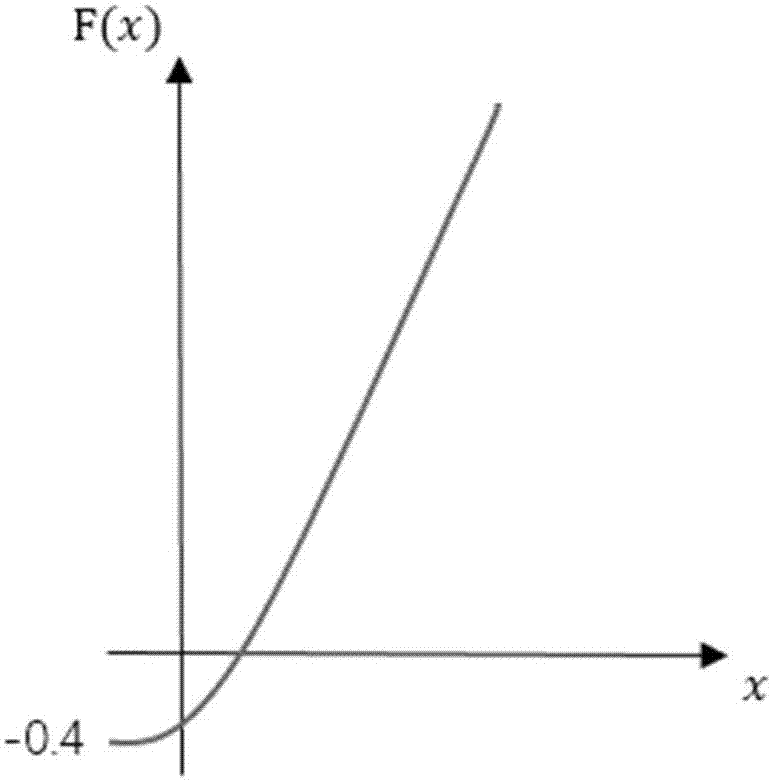
图1为判别函数的导数图;
图2为本发明中任务wcet/bcet的变化对能耗影响的仿真实验结果图;
图3为本发明中系统的利用率变化对能耗影响的仿真实验结果图。
具体实施方式
下面结合附图及实施例对本发明做进一步的详细说明。
周期任务是实时任务的一种,其特点为两个连续的任务实例的释放间隔为固定的常数。本模型考虑存在n个相互独立的周期任务的硬实时系统,采用最早截止期限优先策略(edf)调度该周期任务集t。每个周期任务ti用二元组(pi,ci)来表示,pi为ti的周期,ci为ti在最坏情况下的执行时间,任务的相对截止时限等于其周期。这里用ri和di表示任务ti的释放时间和截止时限,用aci和ti,j分别表示ti的实际执行时间和其第j个任务实例,用utot表示整个任务集的利用率,
周期任务集开始调度之前,计算周期任务的总利用率utot,确定处理器离线速度为sof=max{smin,utot}。
在实时调度器上设置两个队列,一个是任务的就绪队列(ready_queue),另一个是任务的到来队列(delay_queue)。ready_queue包含就绪的任务集合,按照任务的优先级高低排列,定义集合rd(ti,t)为t时刻就绪队列中的任务集合。delay_queue包含已经运行完毕但下一个实例还没到来的任务。
第i个周期任务ti(pi,ci)在t时刻到达时,根据最早截止期限优先原则插入就绪队列中,并初始设置remi(t)=wi(t)=ci,remi(t)是任务ti在时刻t的可利用执行时间,wi(t)是任务ti在时刻t剩余的最坏情况下执行时间。
若ti(pi,ci)在t时刻就绪,则任务ti在时刻t可利用的时间由3部分组成:比ti优先级高的任务提前完成所产生的空闲时间总和slh(ti,t);任务ti原有的可利用执行时间;比ti优先级低的任务所产生的空闲时间总和sll(ti,t)。按照以下的方法计算空闲时间以及处理器速度:
1.计算
2.定义tf=t+slh(ti,t)+remi(t),如果在时刻tf就绪队列为空,则定义tf′为在时刻tf之后最近的一次任务到达时刻。tβ为在时刻tf之前没有完成的优先级最高的任务,remβ(t)和wβ(t)分别为tβ的可利用执行时间和剩余最坏情况下执行时间,pl(ti,t)表示在时刻t之前已完成的优先级比任务ti低的任务集合,则定义pl′(tβ,t)={tx|tx∈pl(ti,t)anddx≤dβ},其中dx和dβ分别是tx和tβ的相对截止时限,计算
3.将slh(ti,t)和sll(ti,t)之和增加到remi(t),计算ti的速度si=wi(t)/remi(t)。
4.判别si是否是使得ti能耗最优的速度。处理器的功耗表达式为,p=α*s3+pind,其中,s是处理器的执行速度,pind是静态功耗。若采用scrit执行任务,当任务提早完成,若空闲时间大于关闭处理器开销t0,需要关闭处理器。根据xscale处理器功耗模型简化上式,α=1.52,pind=0.08,关闭处理器的开销e0=0.8,scrit取0.3,则p=1.52*s3+0.08,其中s是处理器速度。假定ti在区间δt内执行而不被抢占。此时任务ti剩余最坏情况下执行时间为wi(t),当wi(t)<scrit*δt,且
当x∈(0,0.3δt),如图1所示为判别函数的导数图,f′(x)<0,f(x)在(0,0.3δt)上单调递减,f(0.3δt)=-0.8<0。
在t时刻令δt=remi(t),x=wi(t)判别方法如下:
若0.08*δt-0.8>0,则当f(wi(t))>0时,设置si=scrit,反之保持si不变;
若0.08*δt-0.8≤0,si不变。
当任务ti执行时,remi(t)和wi(t)逐渐减少,如果ti完成执行,则置wi(t)=0,ti加入delay_queue。将pi增加到ri,增加后的ri作为下次周期任务ti的释放时间。
若t时刻,ti运行过程中被其他就绪任务抢占,保留remi(t),wi(t),将ti重新按edf优先级顺序加入就绪队列。
图2为本发明中任务wcet/bcet的变化对能耗影响的仿真实验结果图,其中wcet是任务的最坏情况下执行时间,bcet是任务的最好情况下执行时间。对比算法为现有的dra算法和dstra算法,以及本发明提出的lpabobf算法。横坐标为wcet/bcet,纵坐标为归一化后的能耗。当wcet/bcet逐渐增大,任务的实际执行时间的平均值就会减少,任务集的平均空闲时间就逐渐增多,三者的能耗都逐渐下降。可以看出lpabobf算法的性能始终优于dra和dstra算法,经计算可知,在这种情况下lpabobf比dra算法节省约18.33%~28.57%的能耗,比dstra节省约7.3%~18.03%能耗。
图3为本发明中系统的利用率变化对能耗影响的仿真实验结果图。对比算法为现有的dra算法和dstra算法,以及本发明提出的lpabobf算法。横坐标为利用率,纵坐标为归一化后的能耗。随着利用率的增加,处理器处于运行状态的时间比增大,三种算法的能耗均逐渐增大。可以看出lpabobf算法的节能效果相对两者较好。当利用率较小时,处理器总是处于关闭的状态,故三者能耗相接近,但采用dpm技术的dstra和lpabobf算法有一定优势。随着利用率的增加,很多时间段上要在传统dvs策略或关键速度策略中做出选择,lpabobf算法逐渐起到了效果。当利用率接近1时,负载加重,处理器速度小于关键速度的情况较少,lpabobf算法与dstra算法节能效果相接近,经计算,lpabowsa比dra算法节省8.9%~26.19%的能耗,比dstra算法节省约2.7%~13.98%的能耗。
- 还没有人留言评论。精彩留言会获得点赞!