一种基于图方法的图像检索重排方法与流程
本发明涉及图像处理技术领域,尤其涉及一种基于图方法的图像检索重排方法。
背景技术:
随着社交网站、互联网及多媒体技术的不断发展,视频、图像、音频等多媒体数据正在以惊人的速度增长。例如,google检索每年增长约1,000,000,000,000个新索引;facebook注册用户已经超过1,000,000,000,每月上传超过1,000,000,000的图片。在图像数量不断增长的同时,不同类别图像也在不断丰富。例如,建筑风格图像、地理信息图像、医学图像、刑事侦查图像(脚印、人脸、指纹等)、以及商标版权图像等。随着互联网图像信息丰富,海量图像数据在满足用户对图像需求的同时,产生的噪音信息也越来越多。在海量图像库中寻找对用户有用图像信息的图像检索技术已经成为检索技术的重点研究领域之一。
技术实现要素:
本发明的目的是针对海量图像信息、提出一种提高检索精度的方法。
本发明提供的一种基于图方法的图像检索重排方法,通过对图像的检索结果进行重排,优化已有的排序结果得出更接近用户理想结果;利用原始排序结果的近邻集合计算出每张图像之间近邻集合的相似性;在将紧邻集合的相似性看做图像的相似性;最后利用图像之间新的相似性来重新排序检索结果,包括以下步骤:
步骤一:利用杰卡德系数构建图像近邻的相似性;
定义一个图像集合x={x1,…,xn},xn是图像集合中图像的编号;xq是待检索图像或者中心图像,
步骤二:更新杰卡德系数图;
根据步骤一中杰卡德系数构建的权重图,更新权重图中边权构建更新之后的权重图如下:
然后,将w′(x,xq)作为更新之后的权重图;
步骤三:确定最后的权重图;
根据步骤二中构建的权重图来确定xq与x∈x之间最终的权重图计算公式如下:
最后,将w(x,xq)作为第三层的权重;根据公式(3)构建的最终边权值的期望如下:
有益效果:本发明提出了基于原始排序结果的图像检索构图方法,该方法利用近邻集合的相似度构建出图像之间相关性成正比的局部图,并用利用构图结果进行重排,在满足定理1条件下获取了较高的检索精度。
附图说明
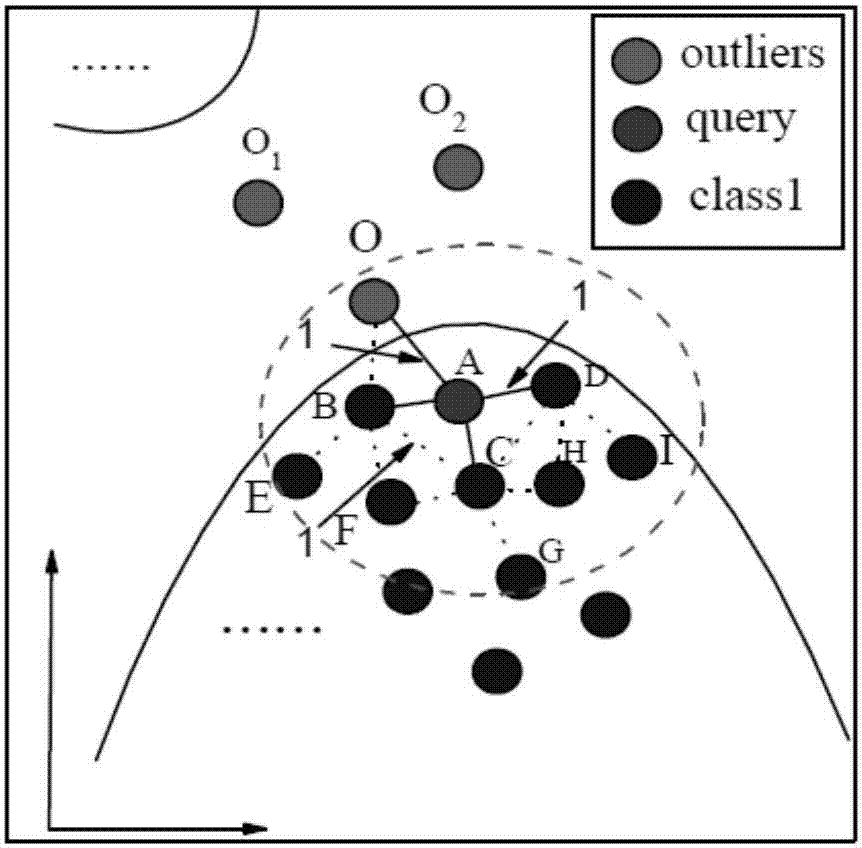
图1通过杰卡德相似性系数度量节点a附近节点的近邻集合相似性。
图2第二层权重图将第一层权重图中杰卡德相似性度量值大于0的边权变为1.
图3第三层权重图将第二层权重图节点之间的边数求和作为权重图的边权值。
具体实施方式
为使本发明解决的技术问题、采用的技术方案和达到的技术效果更加清楚,下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部内容。
本发明提供了基于图方法的图像检索重排,通过对图像的检索结果进行重排计算,优化已有的排序结果得出更接近用户理想结果的重排方法。该方法利用原始排序结果的近邻集合计算出每张图像之间近邻集合的相似性;在将紧邻集合的相似性看做图像的相似性;最后利用图像之间新的相似性来重新排序检索结果。重排方法的主要步骤如下:
步骤一:利用杰卡德系数构建图像近邻的相似性
定义一个图像集合x={x1,…,xn},xq是待检索图像(或者中心图像),
步骤二:更新杰卡德系数图
根据步骤一中杰卡德系数构建的权重图,更新权重图中边权构建更新之后的权重图如下:
然后,将w′(x,xq)作为更新之后的权重图。
步骤三:确定最后的权重图
根据步骤二中构建的权重图来确定xq与x∈x之间最终的权重图计算公式如下:
最后,将w(x,xq)作为第三层的权重。至此,可以根据特征相似近邻集合和公式(3)构建任意特征重排的权重图。相比于现有的特征图构建算法,本文算法除了直观上能够一定程度上消除图像流形附近存在边界点对检索效果的影响之外。构建权重图的边权值在概率上接近图像之间的相似性概率。根据公式(3)构建的最终边权值的期望如下:
构图过程的整体步骤如图1至图3所示。
理论证明
为了方便描述图像之间的相似性关系,定义函数c(·,·)(若
定理1:如果下面两个条件被满足:
(1)p(c(x,a)=1|x∈nk(a))=p(c(x,b)=1|x∈nk(b))=p
(2)|v|>>k
(3)
则,
证明:
在证明定理1之前,首先给出下面两个引理及证明:
引理1:如果下面两个条件被满足:
(1)p(c(x,a)=1|x∈nk(a))=p(c(x,b)=1|x∈nk(b))=p
(2)|v|>>k
则,
证明:
由引理1结论出发,根据条件概率公式可以得到如下等式关系:
其中,等式右侧第一项为节点a的第k个近邻属于节点b的前k个近邻时满足结合nk(a)与nk(b)的交集大小为α的概率,同理等式右侧第二项表示节点a的第k个近邻不属于节点b的前k个近邻时满足结合nk(a)与nk(b)的交集大小为α的概率。不同特征的排序结果相互独立,因此:
进一步推导可知:
从上述推导可知,引理1得证。
引理2:如果下面两个条件被满足:
(1)p(c(x,a)=1|x∈nk(a))=p(c(x,b)=1|x∈nk(b))=p
(2)|v|>>k
则,
证明:
由引理2结论出发,根据条件概率公式可以得到如下等式关系:
其中,等式右侧第一项为节点a的第k个近邻属于节点b的前k个近邻时满足结合nk(a)与nk(b)的交集大小为α的概率,同理等式右侧第二项表示节点a的第k个近邻不属于节点b的前k个近邻时满足结合nk(a)与nk(b)的交集大小为α的概率。不同特征的排序结果相互独立,因此:
进一步推导可知:
从上述推导可知,引理2得证。
通过引理1和引理2的证明之后。从定理1的结论出发,利用条件概率公式可以得到如下推导过程:
接下来再次根据条件概率公式可以推导出:
p(j(a,b)=α)
=p(j(a,b)=α|c(a,b)=1)·p(c(a,b)=1)+p(j(a,b)=α|c(a,b)=0)·p(c(a,b)=0)
上述等式右边第一项边为图像a和图像b是相关图像时j(a,b)=α的概率,等式右边第二项为图像a和图像b不是相关图像的概率。由此可以得出如下等式:
通过引理1、引理2和上述公式,可以推知:
当α=0时,能够得到如下等式:
上述等式p(c(a,b)=1)是待求解的未知数,容易得出上述公式的解为
定理1得证。
通过定理1的结论计算e(w(x,xq))如下:
通过公式(5)可知,w(x,xq)值的期望与p(c(x,xq)=1)成正比关系。至此,公式(3)给出了本文构图方法,公式(5)给出了本文方法可靠性的理论证明。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!