实体标注方法、意图识别方法及对应装置、计算机存储介质与流程
本发明涉及计算机应用技术领域,特别涉及一种实体标注方法、意图识别方法及对应装置、计算机存储介质。
背景技术:
自然语言处理是人工智能的一个重要甚至核心的部分,其目的是理解一句话要表达什么,主要包含两大任务:实体标注和意图识别。其中实体标注是标注一句话中实体词的属性标签,意图识别是识别一句话想要实现什么意图或目的。举个例子,如果有这么一句话“周杰伦演过哪些电影”,实体标注的任务是把实体词“周杰伦”标记为movie_actor标签,movie_actor指代影视演员;而意图识别是识别该句话是要获取一个演员演过哪些电影。
目前的实体标注和意图识别方法都只是基于句子结构,这种单纯基于句子结构的方式往往会造成意图识别和实体标注准确率低等问题。
技术实现要素:
有鉴于此,本发明提供了一种实体标注方法、意图识别方法及对应装置、计算机存储介质,以便于提高实体标注和意图识别的准确率。
具体技术方案如下:
本发明提供了一种实体标注方法,该方法包括:
利用知识图谱对句子中至少部分词语的属性标签进行词编码,得到至少部分词语的第一表达向量;
基于句子结构对所述句子中至少部分词语进行词编码,得到至少部分词语的第二表达向量;
将第一表达向量和第二表达向量进行融合,得到对所述句子的实体标注结果。
本发明还提供了一种意图识别方法,该方法包括:
利用知识图谱对句子中至少部分词语的属性标签进行组合编码,得到所述句子的第一句向量;
基于句子结构对所述句子进行编码,得到所述句子的第二句向量;
将所述句子的第一句向量和第二句向量进行融合,得到对所述句子的意图识别结果。
本发明提供了一种实体标注装置,其特征在于,该装置包括:
第一词编码单元,用于利用知识图谱对句子中至少部分词语的属性标签进行词编码,得到至少部分词语的第一表达向量;
第二词编码单元,用于基于句子结构对所述句子中至少部分词语进行词编码,得到至少部分词语的第二表达向量;
向量融合单元,用于将第一表达向量和第二表达向量进行融合,得到对所述句子的实体标注结果。
本发明还提供了一种意图识别装置,该装置包括:
第一句编码单元,用于利用知识图谱对句子中至少部分词语的属性标签进行组合编码,得到所述句子的第一句向量;
第二句编码单元,用于基于句子结构对所述句子进行编码,得到所述句子的第二句向量;
向量融合单元,用于将所述句子的第一句向量和第二句向量进行融合,得到对所述句子的意图识别结果。
本发明提供了一种设备,包括
存储器,包括一个或者多个程序;
一个或者多个处理器,耦合到所述存储器,执行所述一个或者多个程序,以实现上述方法中执行的操作。
本发明还提供了一种计算机存储介质,所述计算机存储介质被编码有计算机程序,所述程序在被一个或多个计算机执行时,使得所述一个或多个计算机执行上述方法中执行的操作。
由以上技术方案可以看出,本发明将知识图谱引入实体标注和意图识别,即通过将知识图谱中实体的属性信息与基于句子结构的方式进行融合,来进行实体标注和意图识别,相比较现有技术单纯基于句子结构的方式提高了准确性。
【附图说明】
图1为本发明实施例提供的实体标注的方法流程图;
图2为本发明实施例提供的利用知识图谱进行词编码的示意图;
图3为本发明实施例提供的基于句子结构进行词编码的示意图;
图4为本发明实施例提供的融合知识图谱和句子结构方式进行实体标注的示意图;
图5为本发明实施例提供的意图识别的方法流程图;
图6为本发明实施例提供的利用知识图谱进行句编码的示意图;
图7为本发明实施例提供的融合知识图谱和句子结构方式进行意图识别的示意图;
图8为本发明实施例提供的实体标注装置的结构图;
图9为本发明实施例提供的意图识别装置结构图;
图10为本发明实施例提供的示例设备的结构图。
【具体实施方式】
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明进行详细描述。
本发明的核心思想在于,将知识图谱引入实体标注和意图识别,即将知识图谱中实体的属性信息与基于句子结构的方式进行融合,来进行实体标注和意图识别,从而提高准确性。下面结合实施例分别对本发明提供的方法和装置进行详细描述。
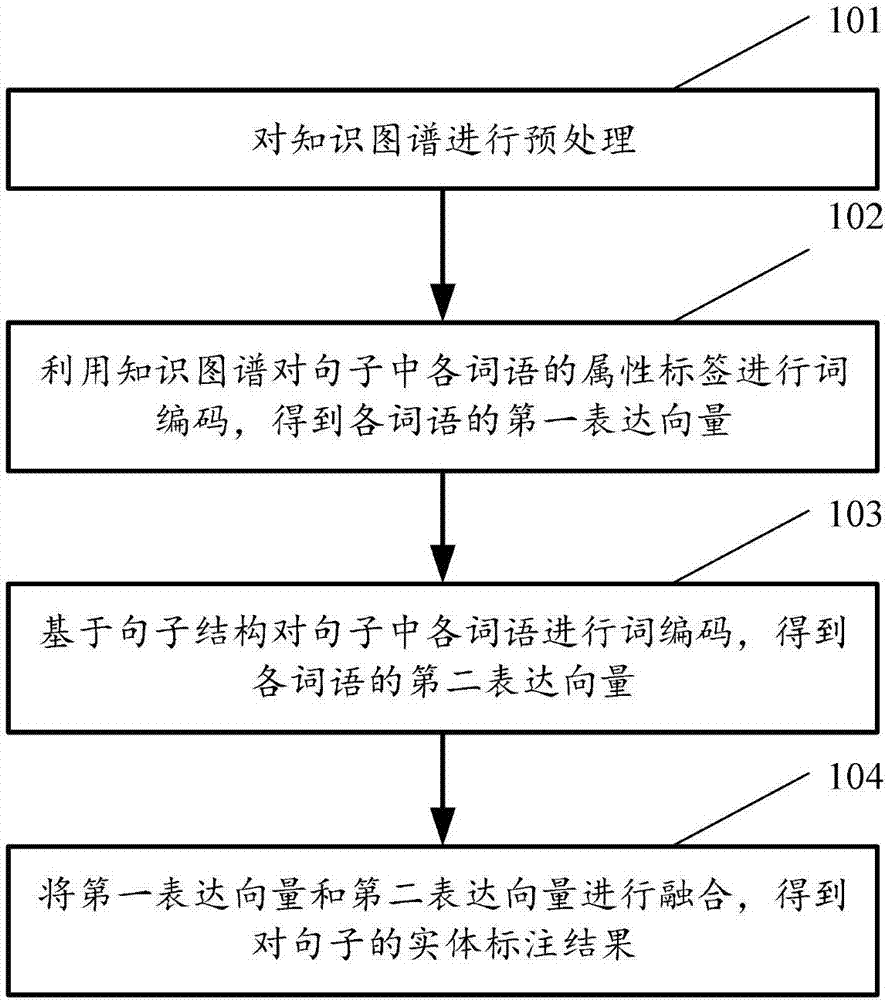
图1为本发明实施例提供的实体标注的方法流程图,如图1中所示,该方法可以包括以下步骤:
在101中,对知识图谱进行预处理。
知识图谱中,存储有各实体以及各实体对应的属性信息、各实体之间的关系。但知识图谱通常是以领域/类别划分的,例如,在音乐领域/类别中,实体“周杰伦”对应有属性标签:“歌手”、“作曲者”和“词作者”,同时在影视领域/类别中,也存在实体“周杰伦”,其对应有属性标签“演员”。本发明实施例中为了方便对知识图谱的利用,可以首先对知识图谱进行预处理。具体地,可以包括以下步骤:
s11、首先将知识图谱中各实体在各领域中的属性标签进行整合,得到各实体对应的属性标签。
仍以上述实体“周杰伦”为例,将其在各领域中的属性标签分别进行整合后,得到该实体“周杰伦”对应的所有属性标签为:“歌手”、“作曲者”、“词作者”、“演员”。
s12、将各实体对应的属性标签存储于键值存储引擎。
在得到各实体对应的属性标签后,分别将实体作为键(key),将实体对应的属性标签作为值(value),然后将各键值(key-value)对存储于键值存储引擎中。
需要说明的是,上述对知识图谱的预处理目的是为了后续方便对实体在知识图谱中的属性标签进行快速查找,但并不是本发明所必须执行的步骤。当然,也可以采用其他对知识图谱进行预处理的方式。
在102中,利用知识图谱对句子中各词语的属性标签进行词编码,得到各词语的第一表达向量。
本步骤中,采用知识图谱得到的各词语的第一表达向量,其目的是为了让各词语的第一表达向量中包含知识图谱中实体的属性信息。具体地,可以通过以下步骤实现:
s21、利用知识图谱识别句子中的实体以及该实体对应的属性标签。
本步骤中可以采用最长匹配原则将句子在知识图谱中进行匹配,识别出句子中的实体。具体地,获取句子的各n-gram(n元语法),在本发明实施例中,n-gram指的是连续n个词语构成的搭配,其中n为1以上的各值。将各n-gram分别与知识图谱进行匹配,看哪些n-gram在知识图谱中匹配到实体,当有发生重叠的多个n-gram都匹配到实体时,取其中长度最长的n-gram作为识别出的实体。
例如,对“周杰伦演过哪些电影”这句话中,分别得到各n-gram包括:
1-gram:“周”、“杰”、“伦”、…、“影”;
2-gram:“周杰”、“杰伦”、“伦演”、…、“电影”;
3-gram:“周杰伦”、“杰伦演”、“伦演过”、…、“些电影”;
……
其中“周杰”能够在知识图谱中匹配到实体,“周杰伦”也能够在知识图谱中匹配到实体,且两者存在重叠,那么取长度最长的“周杰伦”作为识别出的实体。
在确定各实体对应的属性标签时,可以查询键值存储引擎,查找以实体作为key对应的value。
s22、利用识别结果对句子进行分词,对得到的各词语标注属性标签。
在对句子进行分词时,将识别出的实体作为独立的词语,然后对句子的其他内容进行分词。仍以“周杰伦演过哪些电影”为例,进行分词后,得到:“周杰伦”、“演”、“过”、“哪些”、“电影”。
对各词语标注属性标签后,“周杰伦”标注“歌手”、“作曲者”、“词作者”、“演员”,由于“演”、“过”、“哪些”、“电影”均不是知识图谱的实体,因此可以均标注“o”指示没有对应的属性标签。
需要说明的是,在本发明实施例中均以句子中的“各词语”为例进行描述,但也不排除采用句子中的“至少部分词语”进行处理。例如,在本步骤中,对句子进行分词后,对得到的至少部分词语标注属性标签,诸如仅对指示图谱中的实体标注属性标签。
s23、对各词语的属性标签进行词编码,并将编码结果进行全连接层的转换,得到各词语的第一表达向量。
本步骤中,对各词语的属性标签进行词编码,目的是将各词语的属性标签集合转换为一串计算机能够识别的编码。本实施例中采用的编码方式可以包括但不限于one-hot(独热)编码。
如图2所示,每个词语对应的属性标签集合分别进行one-hot编码后,分别得到一个编码结果。该编码结果的长度可以为属性标签的总数量,例如知识图谱中存在m个属性标签,那么编码结果就是m位,每一位对应一个属性标签。编码结果中各位的取值用以表明是否具有该位所对应的属性标签。例如“周杰伦”进行词编码的结果中,有4位为1,表明“周杰伦”存在这4个位置对应的属性标签。
对于one-hot的编码结果,进行全连接层的转换,目的是将各词语的属性标签的编码结果映射至实体标签上,该实体标签就是对句子中词语进行实体标注的标签。经过全连接层转换后,得到各词语的第一表达向量。
在本发明实施例中,可以预先对上述全连接层进行训练。训练过程可以包括:预先将已标注有实体标签的句子作为训练样本,利用知识图谱对训练样本中的句子进行上述实体识别、分词、属性标签的标注、one-hot编码后,作为该全连接层的输入,该句子中各词语对应的实体标签构成的第一表达向量为该全连接层的目标输出,对全连接层进行训练。训练得到的全连接层实际上用以进行one-hot编码后编码结果到实体标签的映射。
继续如图2所示,各词语对应的one-hot编码结果分别经过全连接层转换后,得到各词语的第一表达向量,分别表示为:t-dict1,t-dict2,t-dict3,t-dict4和t-dict5。
在103中,基于句子结构对句子中各词语进行词编码,得到各词语的第二表达向量。
本步骤中,具体可以执行以下步骤:
s31、确定句子中各词语的词向量。
在确定句子中各词语的词向量时,可以采用现有的词向量生成工具,例如word2vec等,基于基于语义预先训练word2vec,然后利用该word2vec就能够针对各词语分别生成词向量,每个词对应的词向量长度相同。这种确定词向量的方式是基于语义的,能够使得词向量之间的距离体现词语语义间的关联程度,语义之间关联程度越高的词语,其对应的词向量之间的距离越小。鉴于基于语义的词向量确定方式可以采用目前已有的技术,在此不做详述。
s32、将词向量输入预先训练的神经网络,分别得到各词语的第二表达向量。
将各词向量输入预先训练的神经网络,目的是对句子按照词语粒度进行编码。上述神经网络可以采用诸如双向rnn(循环神经网络)、单向rnn、cnn(卷积神经网络)等等。其中优选双向rnn,因为双向rnn能够循环对句子进行编码。双向rnn的基本思想是提出每一个训练序列向前和向后分别是两个rnn,且这两个rnn都连接着一个输出层。这种结构能够将输入序列中每一个点的前后上下文信息都提供给输出层。具体到本发明,当输入一个分词好的句子,假设该句子中包含n个词,那么经过双向rnn后,将会有n个输出向量,每个词对应一个向量。由于rnn的记忆性,第i个向量包含了前面所有词的信息,因此最后一个词的输出向量也被称为“句向量”,因为理论上它包含了前面所有词的信息。
仍以“周杰伦演过哪些电影”为例,如图3所示,分词后得到的各词语“周杰伦”、“演”、“过”、“哪些”、“电影”分别确定出对应的词向量后,将词向量输入双向rnn,这样分别得到歌词与的第二表达向量,分别记为:output1、output2、output3、output4、output5,每个词语的第二表达向量都包含了上下文信息,即重分考虑了句子结构的影响,包含了句子结构信息。其中output5包含了整个句子的信息,可以被称为句向量。
需要说明的是,上述步骤102和103中基于知识图谱和基于句子结构进行的处理可以以任意的顺序先后执行,也可以同时执行。本实施例中所示的顺序仅为其中一种执行方式。
在104中,将第一表达向量和第二表达向量进行融合,得到对句子的实体标注结果。
本步骤中对第一表达向量和第二表达向量的融合实际上就是对基于知识图谱得到的实体标注和基于句子结构得到的实体标注进行融合。具体地,可以具体执行以下步骤:
s41、分别将各词语的第一表达向量和第二表达向量进行拼接,得到各词语的第三表达向量。
本步骤中,可以将两个向量按照预设的顺序进行拼接,从而得到一个更长的向量,该向量为第三表达向量。
需要说明的是,除了将第一表达向量和第二表达向量进行拼接的方式之外,还可以采用将第一表达向量和第二表达向量进行叠加等其他融合方式,但由于拼接的方式能够分开考虑基于知识图谱的影响和基于句子结构的影响,从而在后续全连接层的转换过程中分别采用不同的参数,因此优选拼接的方式。
s42、将各词语的第三表达向量经过全连接层转换为各词语的结果向量。
将各词语的第三表达向量输入预先训练的全连接层进行转换,从而将各第三表达向量映射至实体标签,经过转换后得到结果向量。其中结果向量的长度为对应实体标签的总数量,结果向量的各位对应各实体标签,各位的取值对应各实体标签的得分。
在本发明实施例中,可以预先对上述全连接层进行训练。训练过程可以包括:预先将已标注有实体标签的句子作为训练样本,分别执行上述步骤102和103中的步骤,即针对训练样本中的句子分别得到各词语的第一表达向量和第二表达向量,然后将第一表达向量和第二表达向量拼接后的结果(即第三表达向量)作为该全连接层的输入,该句子的实体标签作为全连接层的输出进行训练。训练得到的全连接层用以进行句子中各词语的第三表达向量至实体标签的映射。
s43、依据各词语的结果向量对句子进行实体标注。
每个词语均对应有一个结果向量,可以依据结果向量中各实体标签的得分,选择得分最高的实体标签对句子中的各词语进行实体标注。
仍以“周杰伦演过哪些电影”为例,如图4所示,将各词语的第一表达向量和第二表达向量分别进行拼接,得到第三表达向量。图4中,“周杰伦”的第一表达向量t-dict1与第二表达向量output1进行拼接后,得到第三表达向量k1,其他词语类似。然后将各词语的第三表达向量k1、k2、…k5分别输入全连接层,分别得到各词语的结果向量。词语“周杰伦”对应的结果向量中实体标签“actor_name(演员名字)”的得分最高,可以采用“actor_name”对词语“周杰伦”进行标注,其他词语对应的结果向量中,得分最高的实体标签为“o”,指示不是实体,因此采用实体标签“o”对其他词语进行标注。
图5为本发明实施例提供的意图识别的方法流程图,如图5所示,该方法可以包括以下步骤:
在501中,利用知识图谱对句子中各词语的属性标签进行组合编码,得到句子的第一句向量。
与实体标注类似地,在本步骤之前可以首先对知识图谱进行预处理,预处理的过程不再详述,可以参见图1中101的相关描述。
本步骤中,采用知识图谱得到句子的第一句向量,目的是为了让第一句向量中包含知识图谱中实体的属性信息。具体地,可以通过以下步骤实现:
s51、利用知识图谱识别句子中的实体以及该实体对应的属性标签。
本步骤的详细实现参见图1所示实施例中,102中的步骤s21,在此不再赘述。
s52、对各词语的属性标签进行组合编码,并将编码结果进行全连接层的转换,得到句子的第一句向量。
在得到句子中各词语的属性标签后,统一对各词语的属性标签进行组合编码,得到一个编码结果。该编码结果是一个向量,该向量的长度对应属性标签的总数量,每一位对应一个属性标签,各位的取值为该属性标签在句子中的权值。
其中,在确定属性标签在句子中的权值时,可以依据该句子中属性标签出现的次数以及与该属性标签对应相同实体的属性标签数量确定。具体地,属性标签labeli的权值
其中,m表示句子中的第m个词语,m表示句子中词语的个数。aim表示标签labeli对于第m个词语的取值,若labeli不是第m词语的属性标签,则aim的值取0,若labeli是第m个词语的属性标签,则aim的取值为
仍以句子“周杰伦演过哪些电影”为例,“周杰伦”对应的所有属性标签为:“歌手”、“作曲者”、“词作者”、“演员”,其他词语在知识图谱中均不存在对应的属性标签。那么对于“歌手”这个属性标签而言,其在句子中的权值为:
在得到上述编码结果后,将编码结果经过全连接层转换,目的是将句子的基于属性标签的编码结果映射至实体标签上。该实体标签就是对句子中词语进行实体标注的标签。经过全连接层转换后,得到句子的第一句向量。该第一句向量的长度对应实体标签的总数量,第一句向量的各位取值为该位所对应实体标签在句子中的权值。
在本发明实施例中,可以预先对上述全连接层进行训练。训练过程可以包括:预先将已标注有实体标签的句子作为训练样本,利用知识图谱对训练样本中的句子进行上述实体识别、分词、属性标签的标注、组合编码后,得到的编码结果作为该全连接层的输入,该句子中各词语对应的实体标签构成的第一句向量作为该全连接层的目标输出,对全连接层进行训练。训练得到的全连接层实际上用以进行组合编码后编码结果到实体标签的映射。
本步骤中的过程可以如图6所示,“周杰伦演过哪些电影”中各词语的属性标签经过组合编码后,得到的编码结果经过全连接层,最终得到第一句向量,表示为s-dict。
在502中,基于句子结构对句子进行编码,得到句子的第二句向量。
本步骤中,具体可以执行以下步骤:
s61、确定句子中各词语的词向量。
s62、将各词语的词向量输入预先训练的神经网络,得到句子的第二句向量。
具体地,将各词语的词向量输入预先训练的神经网络后,分别得到各词语的第二表达向量,将最后一个词语的第二表达向量作为句子的第二句向量。
上述确定句子中各词语的词向量,以及将各词语的词向量输入预先训练的神经网络的处理过程与图1所示实施例中步骤103中的相应实现一致,在此不再赘述。只是在得到各词语的第二表达向量后,将最后一个词语的第二表达向量作为句子的第二句向量,而其他词语的第二表达向量在句子意图识别中并未使用。也就是说,采用了图3中的output5作为该句子的第二句向量。
在503中,将句子的第一句向量和第二句向量进行融合,得到对句子的意图识别结果。
本步骤中对第一句向量和第二句向量的融合实际上就是对基于知识图谱得到的意图信息和基于句子结构得到的意图信息进行融合。其中基于知识图谱的实体标注结果对意图识别具有非常大的影响,仍以“周杰伦演过哪些电影”为例,将“周杰伦”正确地标注为“演员”对正确地意图识别结果“一个演员演过哪些电影”影响很大,若将实体“周杰伦”错误地标注为“歌手”,则就很可能无法得到上述意图识别结果。
具体地,本步骤可以包括以下步骤:
s71、将第一句向量和第二句向量进行拼接,得到第三句向量。
本步骤中,可以将两个向量按照预设的顺序进行拼接,从而得到一个更长的向量,该向量为第三句向量。
需要说明的是,除了将第一句向量和第二句向量进行拼接的方式之外,还可以采用将第一句向量和第二句向量进行叠加等其他融合方式。但由于拼接的方式能够分开考虑基于知识图谱的影响和基于句子结构的影响,从而在后续全连接层的转换过程中分别采用不同的参数,因此优选拼接的方式。
s72、将第三句向量经过全连接层转换为结果向量。
将第三句向量输入预先训练的全连接层进行转换,从而将第三句向量映射至句子意图,经过转换后得到结果向量。该结果向量的长度对应句子意图的类别数量,结果向量的各位对应各类句子意图的得分。
在本发明实施例中,可以预先对上述全连接层进行训练。训练过程可以包括:预先将已确定句子意图的句子作为训练样本,分别执行上述步骤501和502中的步骤,及针对训练样本中的句子分别得到第一句向量和第二句向量,然后将第一句向量和第二句向量拼接后的结果(即第三句向量)作为全连接层的输入,该句子的句子意图作为全连接层的输出,进行训练。训练得到的全连接层用以进行句子的第三句向量至句子意图的映射。
s73、依据结果向量确定句子意图。
在本步骤中,可以依据结果向量中各句子意图类别的分值来确定句子意图,例如将分值最高的句子意图作为识别出的该句子的意图。
仍以“周杰伦演过哪些电影”为例,如图7所示,将句子的第一句向量s-dict与第二句向量output5进行拼接后,得到第三句向量k。然后将第三句向量k输入全连接层,最后得到一个结果向量。该结果向量中最高分值的句子意图为:“一个演员演过哪些电影”。
以上是对本发明所提供方法进行的详细描述,下面结合实施例对本发明提供的装置进行详细描述。
图8为本发明实施例提供的实体标注装置的结构图,如图8所示,该装置可以包括:第一词编码单元10、第二词编码单元20和向量融合单元30,还可以进一步包括图谱预处理单元40。其中各组成单元的主要功能如下:
第一词编码单元10负责利用知识图谱对句子中各词语的属性标签进行词编码,得到各词语的第一表达向量。
具体地,第一词编码单元10可以包括:匹配子单元11、分词子单元12和第一词编码子单元13。
其中,匹配子单元11负责利用知识图谱识别句子中的实体以及该实体对应的属性标签。具体地,匹配子单元11可以采用最长匹配原则将句子在知识图谱中进行匹配,识别出句子中的实体。例如,可以获取句子的各n-gram,其中n为1以上的各值。将各n-gram分别与知识图谱进行匹配,看哪些n-gram在知识图谱中匹配到实体,当有发生重叠的多个n-gram都匹配到实体时,取其中长度最长的n-gram作为识别出的实体。
分词子单元12负责利用匹配子单元11的识别结果对句子进行分词,并对得到的各词语标注属性标签。分词子单元在对句子进行分词时,可以将匹配子单元11识别出的实体作为独立的词语。
第一词编码子单元13负责对各词语的属性标签进行词编码,例如可以对各词语的属性标签进行one-hot编码,并将编码结果进行全连接层的转换,得到各词语的第一表达向量。
对于one-hot的编码结果,进行全连接层的转换,目的是将各词语的属性标签的编码结果映射至实体标签上,该实体标签就是对句子中词语进行实体标注的标签。经过全连接层转换后,得到各词语的第一表达向量。
在本发明实施例中,可以预先对上述全连接层进行训练。训练过程可以包括:预先将已标注有实体标签的句子作为训练样本,利用知识图谱对训练样本中的句子进行上述实体识别、分词、属性标签的标注、one-hot编码后,作为该全连接层的输入,该句子中各词语对应的实体标签构成的第一表达向量为该全连接层的目标输出,对全连接层进行训练。训练得到的全连接层实际上用以进行one-hot编码后编码结果到实体标签的映射。
图谱预处理单元40负责将知识图谱中各实体在各领域中的属性标签进行整合,得到各实体对应的属性标签集合;将各实体对应的属性标签集合存储于键值存储引擎。相应地,匹配子单元11可以采用最长匹配算法将句子在键值存储引擎中进行匹配。
第二词编码单元20负责基于句子结构对句子中各词语进行词编码,得到各词语的第二表达向量。具体地,第二词编码单元20可以首先确定句子中各词语的词向量;然后将词向量输入预先训练的神经网络,分别得到各词语的第二表达向量。
第二词编码单元20在确定句子中各词语的词向量时,可以采用现有的词向量生成工具,例如word2vec等,基于基于语义预先训练word2vec,然后利用该word2vec就能够针对各词语分别生成词向量,每个词对应的词向量长度相同。这种确定词向量的方式是基于语义的,能够使得词向量之间的距离体现词语语义间的关联程度,语义之间关联程度越高的词语,其对应的词向量之间的距离越小。
上述神经网络可以采用诸如双向rnn(循环神经网络)、单向rnn、cnn(卷积神经网络)等等。其中优选双向rnn。
向量融合单元30负责将第一表达向量和第二表达向量进行融合,得到对句子的实体标注结果。
具体地,向量融合单元30可以将各词语的第一表达向量和第二表达向量分别进行拼接,得到各词语的第三表达向量;然后将各词语的第三表达向量经过全连接层转换为各词语的结果向量,其中,结果向量的长度对应实体标签的总数量,结果向量的各位对应各实体标签,各位的取值体现对应实体标签的得分;最后依据各词语的结果向量对句子进行实体标注。
其中,向量融合单元30在依据各词语的结果向量对句子进行实体标注时,可以分别按照各词语的结果向量中得分最高的实体标签对句子中的各词语进行实体标注。
图9为本发明实施例提供的意图识别装置结构图,如图9所示,该装置可以包括:第一句编码单元50、第二句编码单元60和向量融合单元70,还可以包括图谱预处理单元80。其中各组成单元的主要功能如下:
第一句编码单元50负责利用知识图谱对句子中各词语的属性标签进行组合编码,得到句子的第一句向量。
其中,第一句编码单元50可以具体包括:匹配子单元51、分词子单元52和组合编码子单元53。
其中,匹配子单元51负责利用知识图谱识别句子中的实体以及该实体对应的属性标签。具体地,匹配子单元51可以采用最长匹配算法将句子在知识图谱中进行匹配,识别出句子中的实体。
分词子单元52负责利用识别结果对句子进行分词,并对得到的各词语标注属性标签。其中,在分词时将匹配子单元51识别出的实体作为独立的词语。
组合编码子单元53负责对各词语的属性标签进行组合编码,并将编码结果进行全连接层的转换,得到句子的第一句向量,第一句向量的长度对应实体标签的总数量,第一句向量的各位取值为该位所对应实体标签在句子中的权值。
图谱预处理单元80负责将知识图谱中各实体在各领域中的属性标签进行整合,得到各实体对应的属性标签集合;将各实体对应的属性标签集合存储于键值存储引擎。相应地,上述匹配子单元51可以采用最长匹配算法将句子在键值存储引擎中进行匹配。
第二句编码单元60负责基于句子结构对句子进行编码,得到句子的第二句向量。具体地,第二句编码单元60可以首先确定句子中各词语的词向量;然后将词向量输入预先训练的神经网络,得到句子的第二句向量。
其中在确定句子中各词语的词向量时,第二句编码单元60利用基于语义预先训练的word2vec,针对句子中各词语分别生成词向量。
上述神经网络可以采用诸如双向rnn(循环神经网络)、单向rnn、cnn(卷积神经网络)等等。其中优选双向rnn。
第二句编码单元60在将词向量输入预先训练的神经网络,得到句子的第二句向量时,可以具体将词向量输入预先训练的神经网络,分别得到各词语的第二表达向量;将最后一个词语的第二表达向量作为句子的第二句向量。
向量融合单元70负责将句子的第一句向量和第二句向量进行融合,得到对句子的意图识别结果。具体地,可以将第一句向量和第二句向量进行拼接,得到第三句向量;将第三句向量经过全连接层转换为结果向量,其中结果向量的长度对应句子意图的类别数量,结果向量的各位对应各类句子意图,各位的取值体现对应句子意图的得分;依据结果向量确定句子意图。
其中,向量融合单元70在依据结果向量确定句子意图时,可以将结果向量中得分最高的句子意图作为句子的句子意图。
上述实体标注和意图识别的方法可以应用于基于自然语言处理的多种场景,在此举一个应用场景的例子:
在智能问答领域,例如用户在手机上的智能问答类客户端输入问题“周杰伦演过哪些电影”,经过上述实体标注和意图识别后,标注出实体“周杰伦”为“actor_name(演员名字)”,意图为“一个演员演过哪些电影”。那么该意图对应的处理逻辑是,在电影数据库中查找该句子中标注为“actor_name(演员名字)”的实体对应的电影名称。假设在电影数据库中找到“周杰伦”对应的电影名称为:“不能说的秘密”、“刺陵”、“天台爱情”、“满城尽带黄金甲”……,那么智能问答类客户端可以直接向用户返回答案:“不能说的秘密”、“刺陵”、“天台爱情”、“满城尽带黄金甲”……。
图10示例性地示出了根据各种实施例的示例设备1000。设备1000可包括一个或多个处理器1002,系统控制逻辑1001耦合于至少一个处理器1002,非易失性存储器(non-volatilememory,nmv)/存储器1004耦合于系统控制逻辑1001,网络接口1006耦合于系统控制逻辑1001。
处理器1002可包括一个或多个单核处理器或多核处理器。处理器1002可包括任何一般用途处理器或专用处理器(如图像处理器、应用处理器基带处理器等)的组合。
一个实施例中的系统控制逻辑1001,可包括任何适当的接口控制器,以提供到处理器1002中的至少一个的任何合适的接口,和/或提供到与系统控制逻辑1001通信的任何合适的设备或组件的任何合适的接口。
一个实施例中的系统控制逻辑1001,可包括一个或多个内存控制器,以提供到系统内存1003的接口。系统内存1003用来加载以及存储数据和/或指令。例如,对应设备1000,在一个实施例中,系统内存1003可包括任何合适的易失性存储器。
nvm/存储器1004可包括一个或多个有形的非暂时的计算机可读介质,用于存储数据和/或指令。例如,nvm/存储器1004可包括任何合适的非易失性存储装置,如一个或多个硬盘(harddiskdevice,hdd),一个或多个光盘(compactdisk,cd),和/或一个或多个数字通用盘(digitalversatiledisk,dvd)。
nvm/存储器1004可包括存储资源,该存储资源物理上是该系统所安装的或者可以被访问的设备的一部分,但不一定是设备的一部分。例如,nvm/存储器1004可经由网络接口1006被网络访问。
系统内存1003以及nvm/存储器1004可分别包括临时的或持久的指令1010的副本。指令1010可包括当由处理器1002中的至少一个执行时导致设备1000实现图1或图5描述的方法之一或组合的指令。各实施例中,指令1010或硬件、固件,和/或软件组件可另外地/可替换地被置于系统控制逻辑1001,网络接口1006和/或处理器1002。
网络接口1006可包括一个接收器来为设备1000提供无线接口来与一个或多个网络和/或任何合适的设备进行通信。网络接口1006可包括任何合适的硬件和/或固件。网络接口1006可包括多个天线来提供多输入多输出无线接口。在一个实施例中,网络接口1006可包括一个网络适配器、一个无线网络适配器、一个电话调制解调器,和/或无线调制解调器。
在一个实施例中,处理器1002中的至少一个可以与用于系统控制逻辑的一个或多个控制器的逻辑一起封装。在一个实施例中,处理器中的至少一个可以与用于系统控制逻辑的一个或多个控制器的逻辑一起封装以形成系统级封装。在一个实施例中,处理器中的至少一个可以与用于系统控制逻辑的一个或多个控制器的逻辑集成在相同的管芯上。在一个实施例中,处理器中的至少一个可以与用于系统控制逻辑的一个或多个控制器的逻辑集成在相同的管芯上以形成系统芯片。
设备1000可进一步包括输入/输出装置1005。输入/输出装置1005可包括用户接口旨在使用户与设备1000进行交互,可包括外围组件接口,其被设计为使得外围组件能够与系统交互,和/或,可包括传感器,旨在确定环境条件和/或有关设备1000的位置信息。
在本发明所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。
上述以软件功能单元的形式实现的集成的单元,可以存储在一个计算机可读取存储介质中。上述软件功能单元存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本发明各个实施例所述方法的部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read-onlymemory,rom)、随机存取存储器(randomaccessmemory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!